LEARN
Common AI-Moderated Research Questions
Understanding how AI-moderated research changes question design.
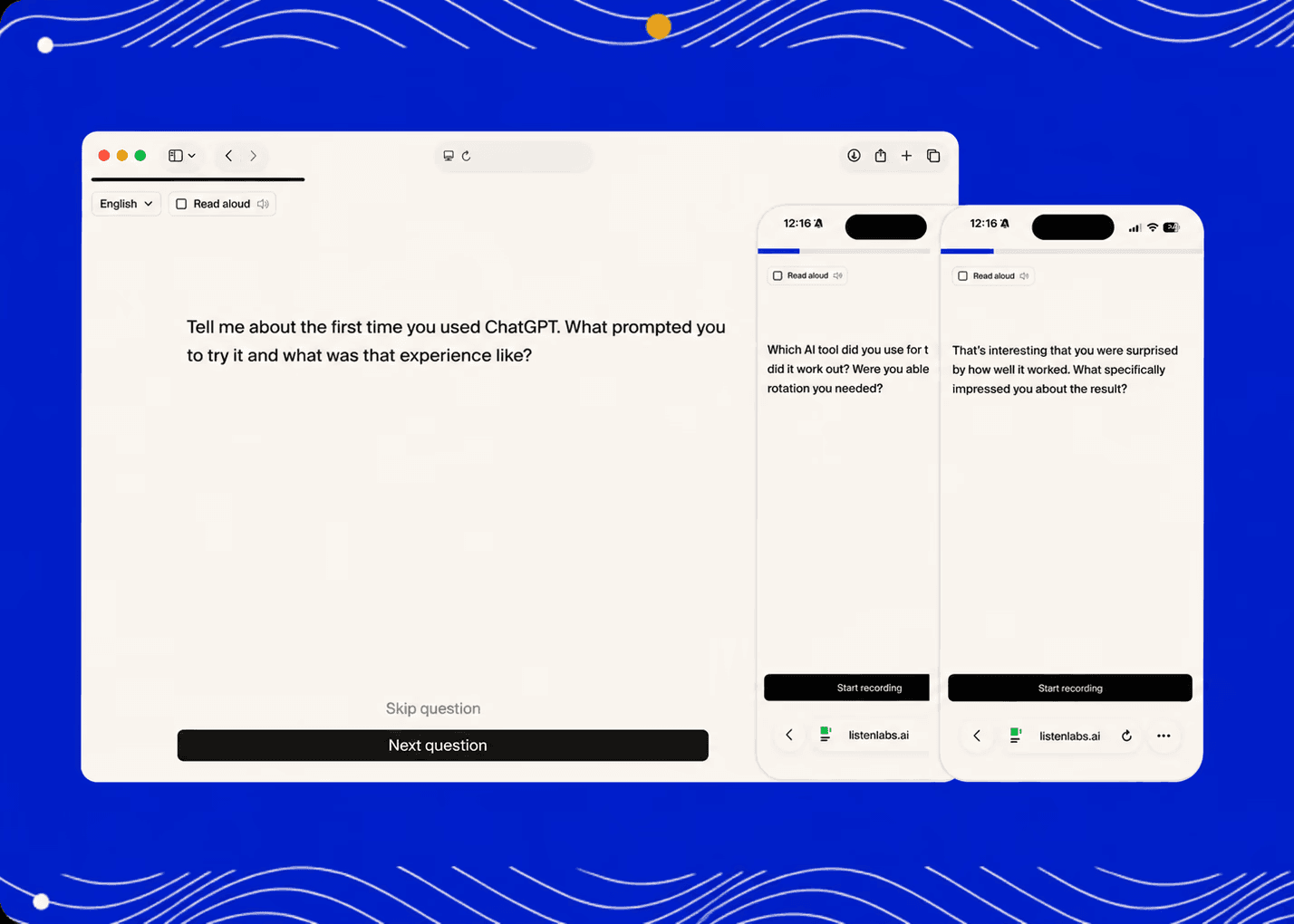
In traditional research, a discussion guide is a script for one conversation. In AI-moderated research, it’s instructions for hundreds of simultaneous ones. The questions carry the entire interview: probing, pacing, follow-ups. What you put in the guide is what every participant gets.
AI-moderated research questions are the prompts in a discussion guide that an AI moderator uses to conduct interviews. Unlike survey questions, they’re designed to invite open-ended responses and trigger adaptive follow-ups. The guide carries the conversation, so question quality shapes every response at once
What makes AI-moderated questions different
When AI runs the interview, questions must be self-sufficient. There’s no moderator reading confusion on someone’s face and rephrasing on the fly. As a result, a question that depends on tone or clarification falls flat. Meanwhile, root questions can be sparser because the AI handles probing. Now, researchers can write the opening prompt and let the platform pull the thread. Furthermore, participants respond differently to AI than to humans. AI-moderation skips small talk and has more direct framing and fewer hedges.
Open-ended vs closed-ended in AI-moderated research
One of the biggest benefits of AI-moderated research is the ability to conduct qualitative research at scale. Open-ended questions are most often used, while closed-ended questions are added when quantitative insights are required alongside qualitative depth.
Question type | When to use it |
|---|---|
Open-ended | Exploring motivations, reactions, decision logic, language participants use |
Closed-ended | Segmenting responses, confirming behaviors, capturing structured data for cross-tabs |
Question banks by use case
Tone/Angle | Prompt |
|---|---|
Concept and creative testing. |
|
Brand research and tracking. |
|
Product discovery. |
|
Screeners and the fraud problem at scale
When you’re running hundreds of interviews in parallel, screeners do two jobs: they qualify the right participants, and they filter out bad actors who fake their way into incentives. The most reliable tool here is the red herring, an option that sounds plausible but shouldn’t apply to a genuine respondent. If someone selects it, screen them out.
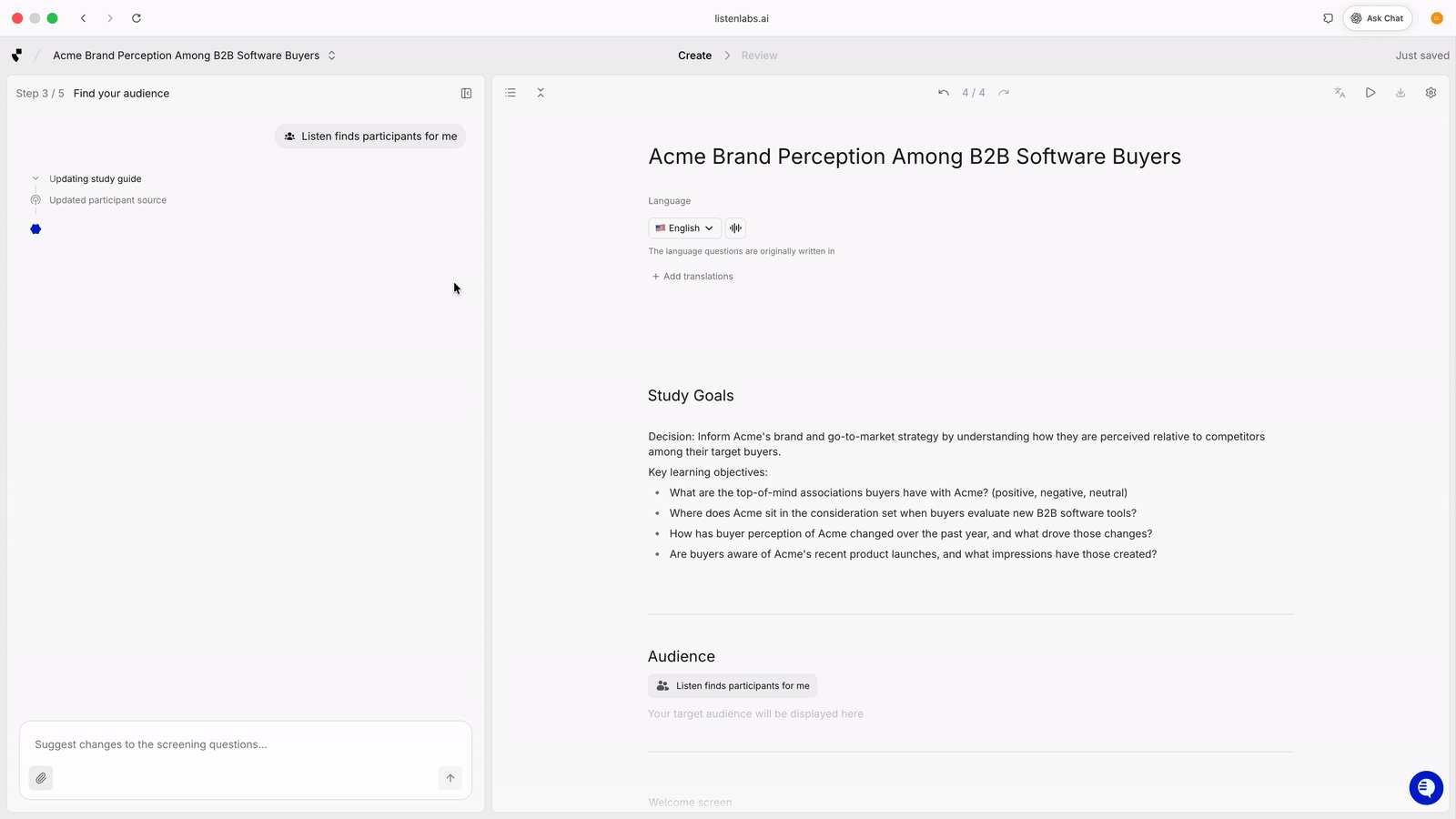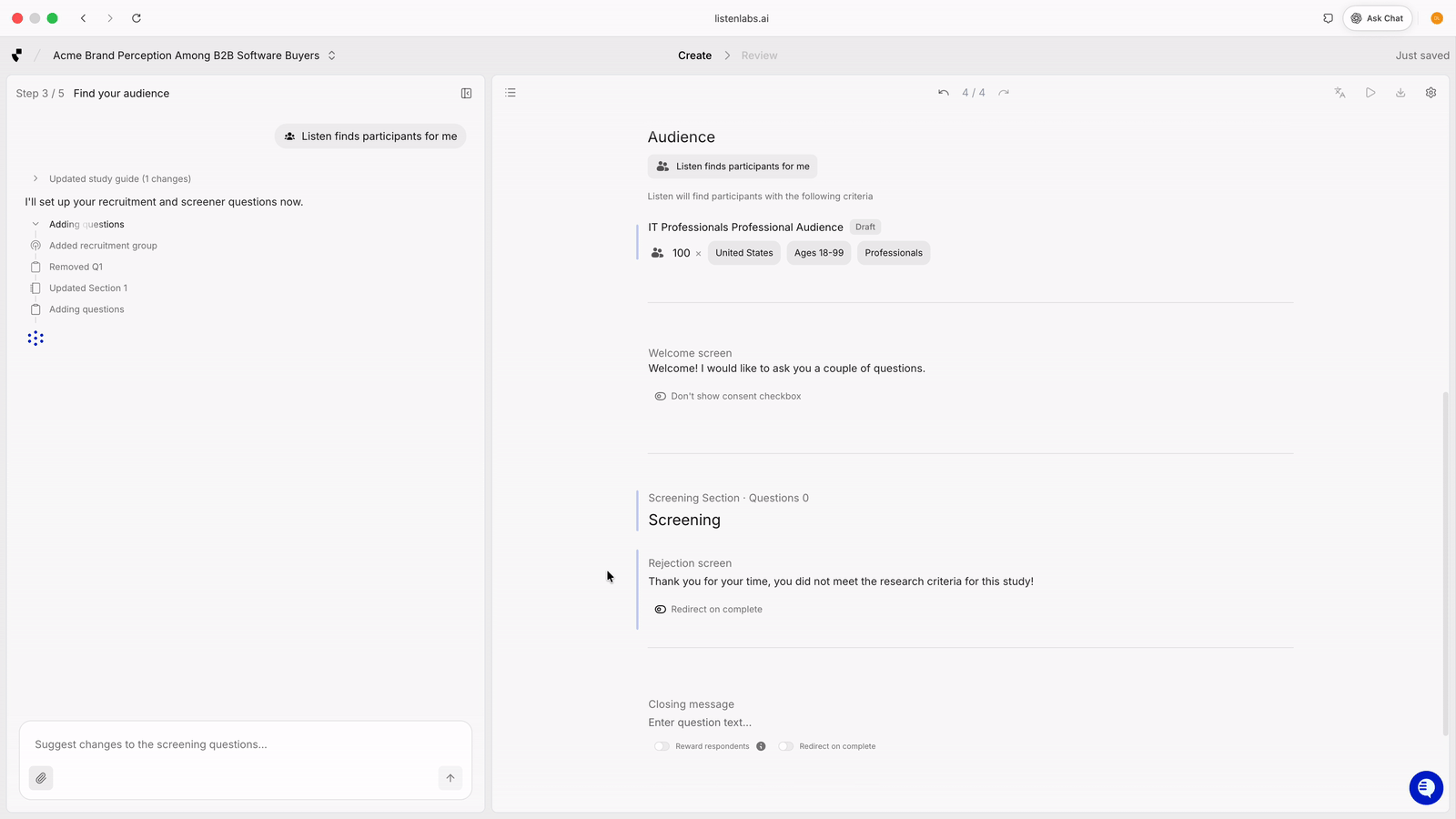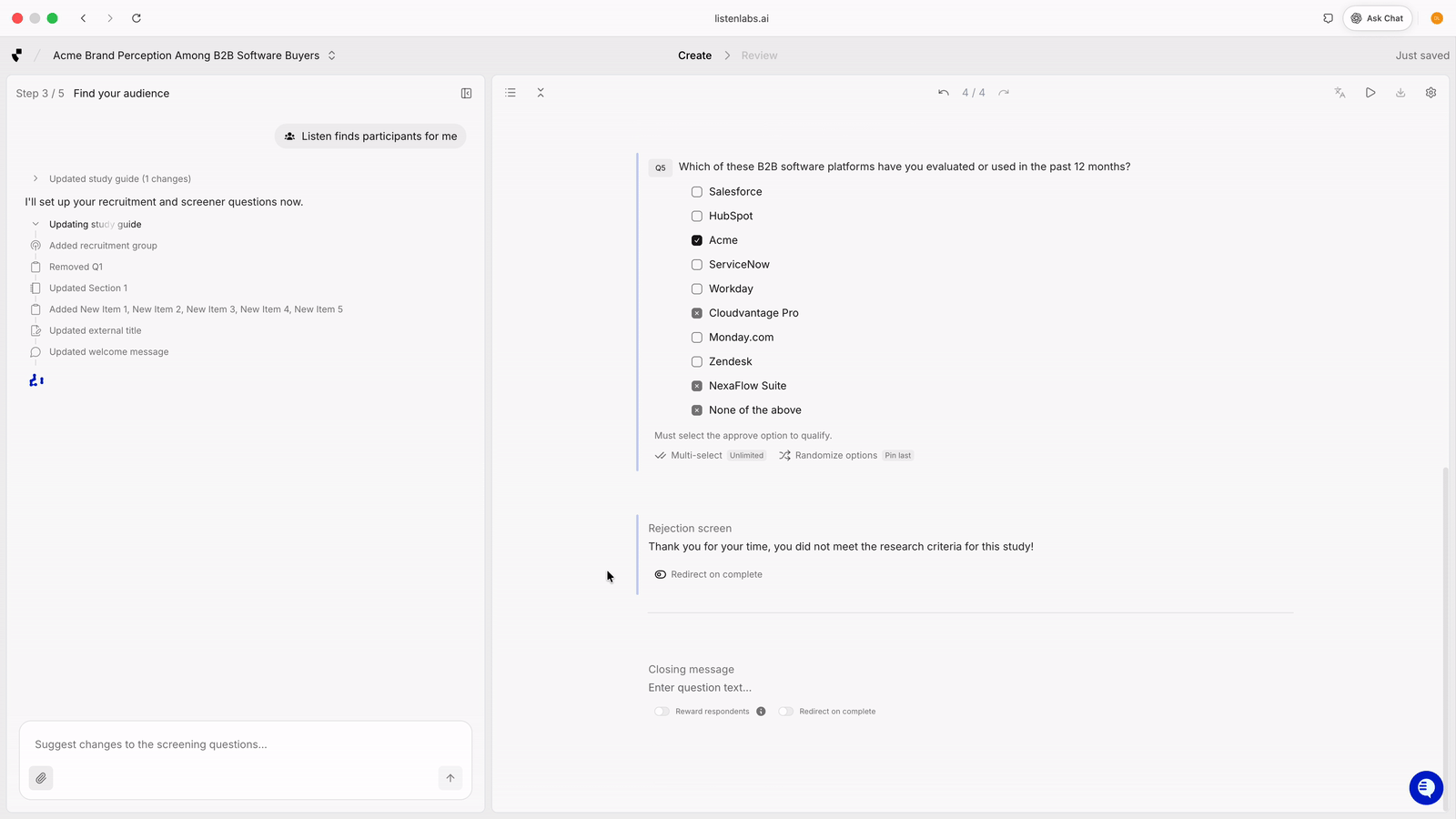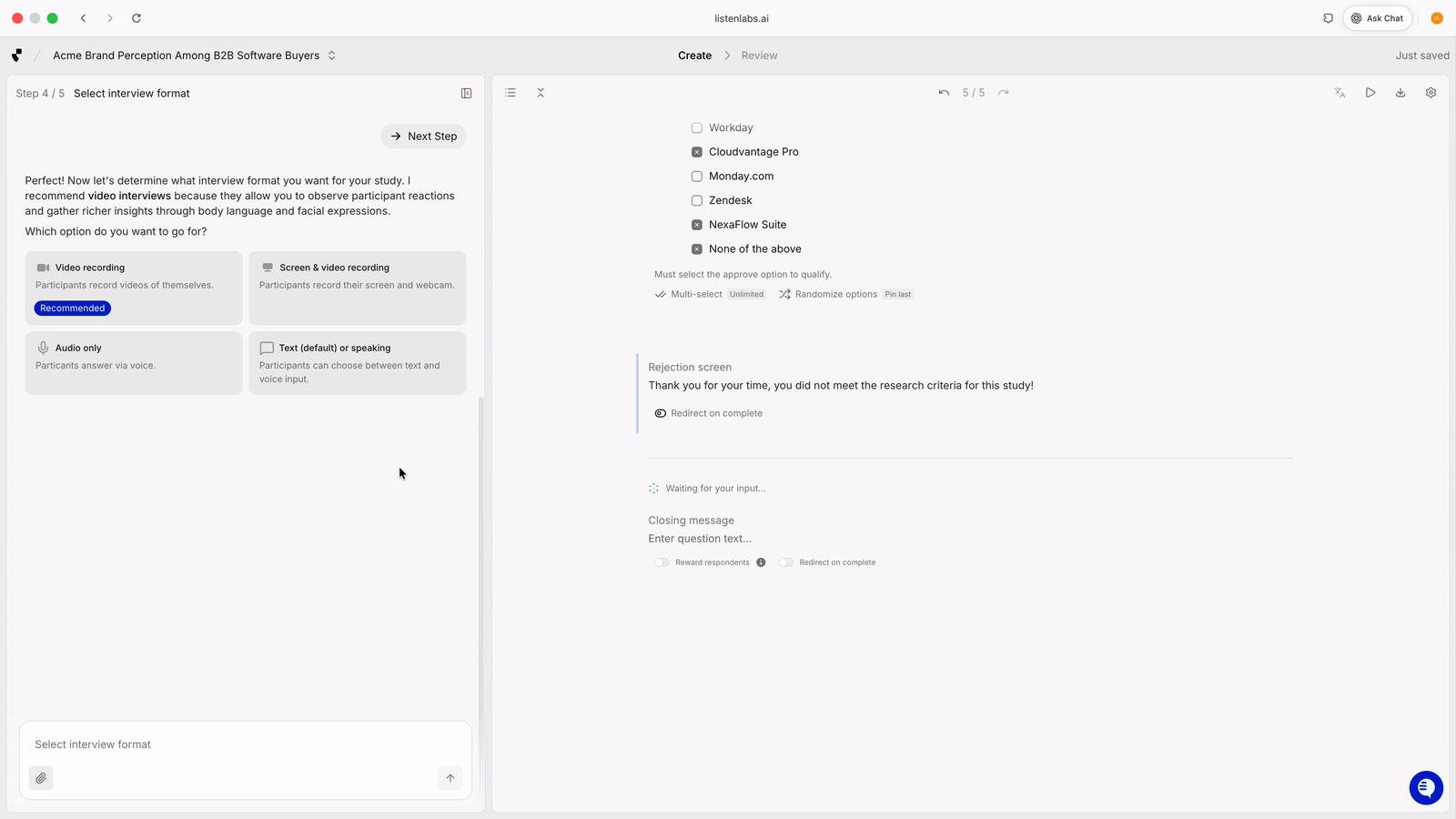
Listen generates screeners from a study brief, including red herring options to filter out fraudulent participants.
Two example screeners for a CPG concept test:
Which of these snack brands have you purchased in the past month? [include one fake brand]
How often do you shop the frozen aisle for household meals?
Behavioral screening (what people do) and attitudinal screening (what they think or feel) tend to be stronger filters than demographic screening alone, which is easy to spoof. A solid mix uses all three.
Probing: what good AI moderators do
A participant says “I don’t really use it that much anymore.” A weak probe restates the obvious: “Can you tell me more?” A better probe pulls the thread: “What changed?” Evaluate platforms on whether the moderator:
Allows silence instead of jumping in after one beat
Mirrors participant language instead of reformulating it in marketing-speak
Stays neutral: no “great answer” responses that bias the next turn
Resists over-explaining when participants pause to think
Should I write follow-ups or let the AI handle them?
Both. Write follow-ups for the moments you can’t afford to miss, like a specific brand association or a known objection. Let the AI handle organic follow-ups for everything else. The best guides combine researcher-specified probes with platform-driven adaptive probing.
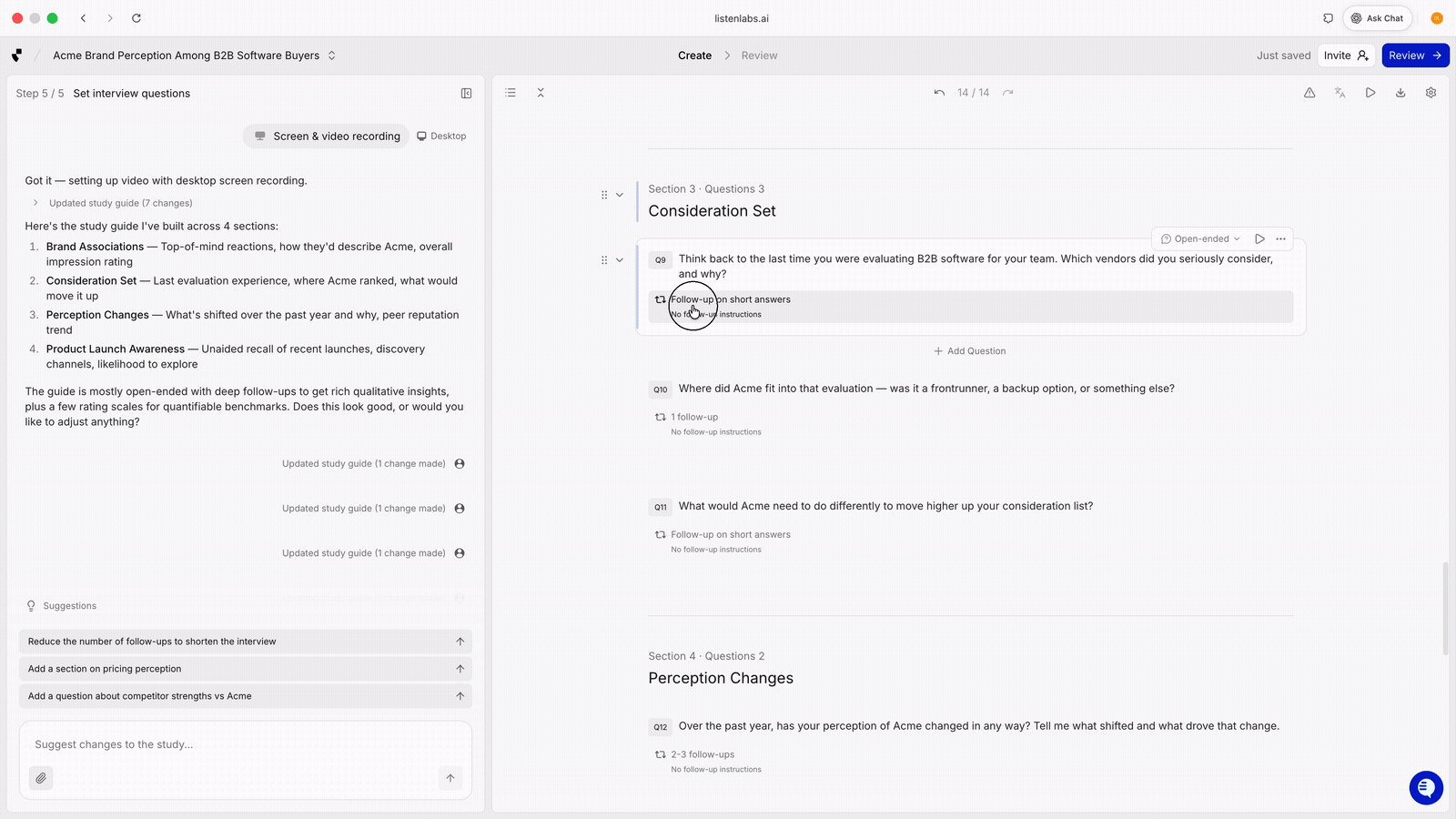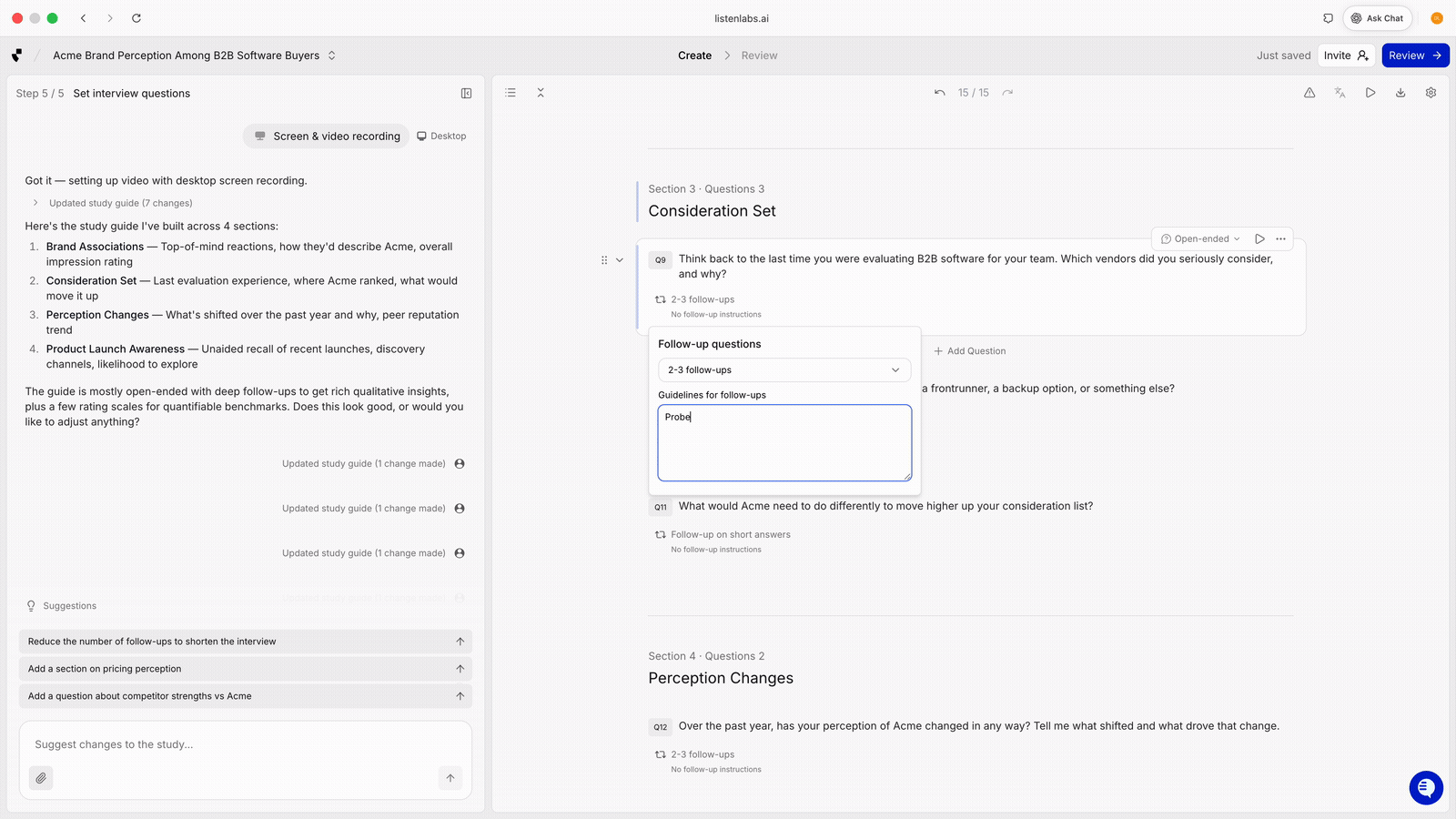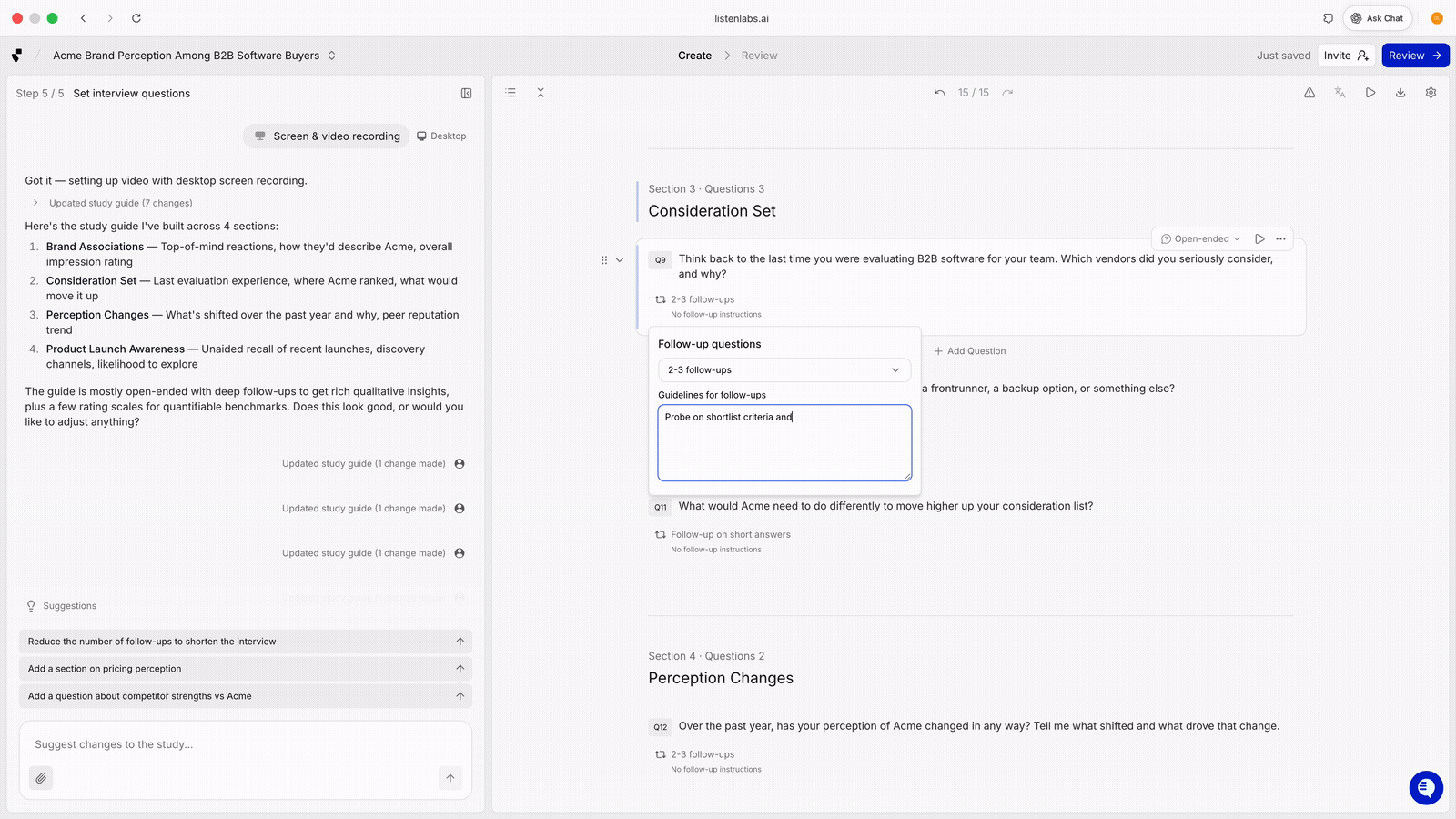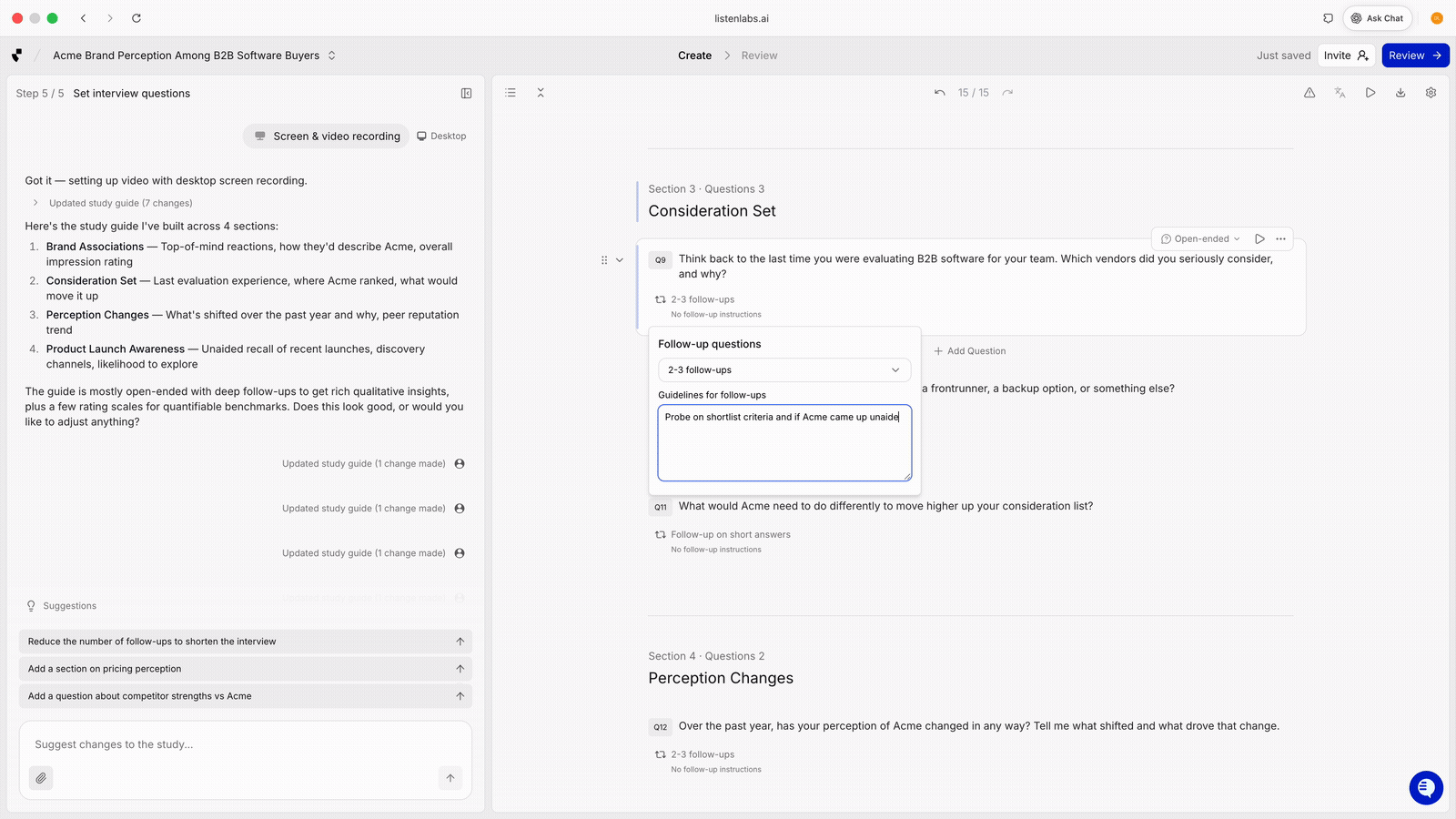
In Listen, researchers can control probe behavior per question: when to probe, how many follow-ups, and what to probe on.
Letting AI draft the discussion guide
The difference between actionable insights and shallow takeaways is usually the quality of the questions. Modern platforms generate guides from a study brief, following research best practices, and researchers edit from there. You stay in control of the conversation; the platform handles the first draft.
Good AI-drafted guides include:
Study context. Goals, decisions the research will inform, and audience definition shape every question the AI writes. Without this layer, you get generic questions; with it, you get a guide that asks what your business actually needs to know.
Stage structure. Warm-up to establish context, core questions to hit the research objectives, deepen questions to push past surface answers, close to capture anything missed.
Open-ended defaults. The platform should default to open prompts and only suggest closed questions where they earn their place.
Use-case-aware patterns. A concept test guide looks different from a brand tracking guide. The platform should know the difference.
Question-level control over follow-up behavior. Set when to probe (never, on short answer, always one to two follow-ups), how many follow-ups to allow, and what to probe on. Example guideline: “probe specifically around HR discoverability and whether they think it could affect job security.”
Researchers need granular control at the question level. Without it, adaptive probing stays a black box. Listen Labs' AI Moderator drafts guides from a brief and exposes these controls so researchers shape the AI’s behavior question by question.

A brand research discussion guide created in Listen. The AI structures sections by research stage and adapts question patterns to the use case.
Common mistakes
Mistake | Why it hurts | Better approach |
|---|---|---|
Leading questions | Telegraphs the answer you want; biases every response at scale | Ask what the participant noticed or felt without naming the conclusion |
Stacking multiple questions | Participant answers one and skips the rest; the AI moves on | One idea per question; let probing pull the threads |
Writing survey questions | Closed-ended stems return closed-ended depth | Open the stem (“walk me through,” “describe”) and let the conversation breathe |
The questions do the work the moderator used to do. At scale, every phrasing choice compounds. One leading question biases hundreds of responses before you catch it. Write accordingly.
See how Listen helps teams run qualitative research at scale without sacrificing depth. Book a demo.