
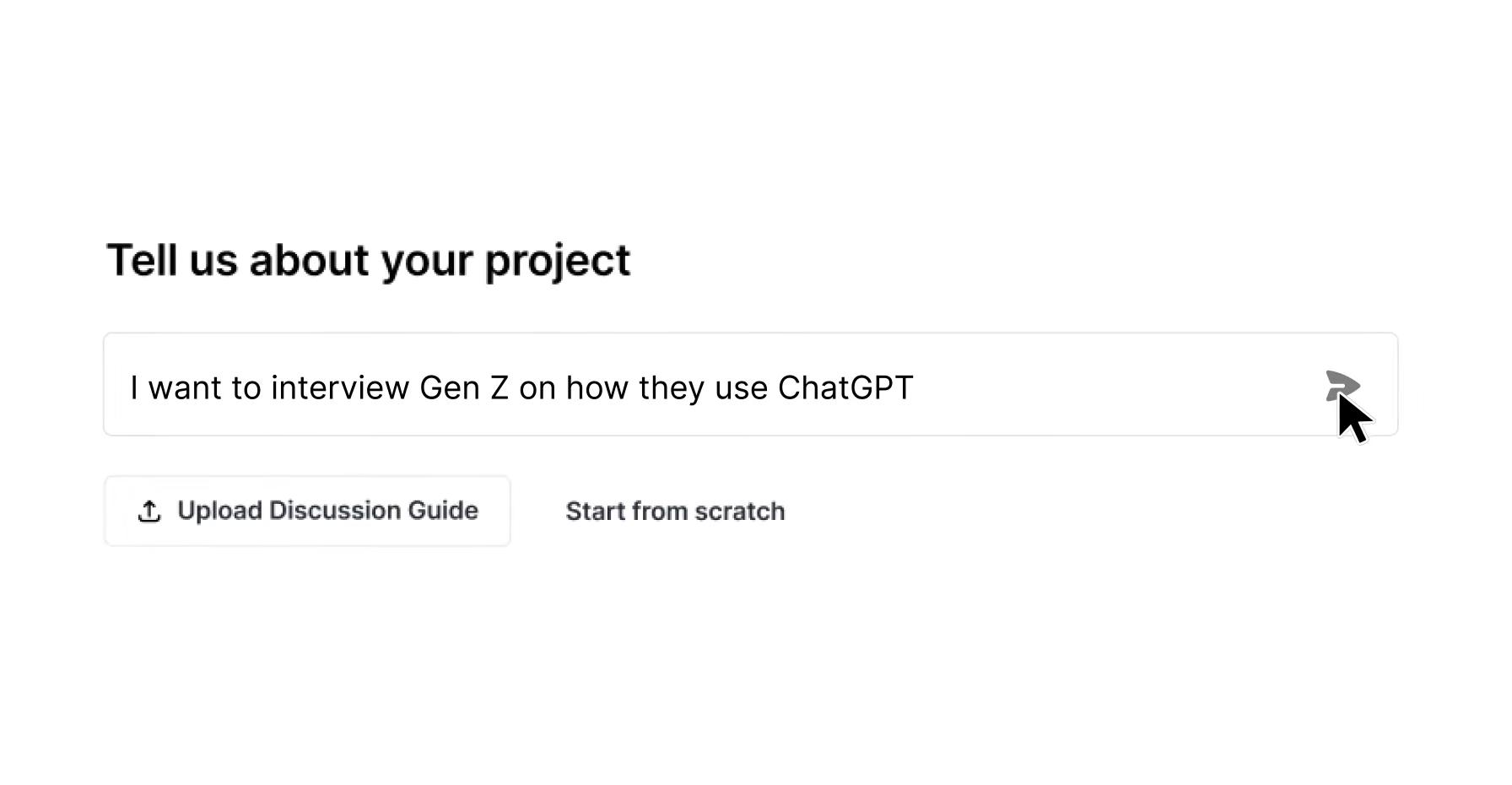
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways for Enterprise Insights Leaders
- Traditional qualitative research takes 4–6 weeks and forces enterprises to choose between depth and scale, which creates backlogs and stale insights.
- Existing tool categories, including agencies, surveys, panels, and repositories, each solve only part of the problem and leave gaps in speed, emotional intelligence, or security.
- Emerging AI interview platforms can deliver hundreds of adaptive conversations in parallel, but quality depends on verified panels, real-time fraud prevention, and full-lifecycle coverage.
- Listen Labs resolves every tradeoff with a 30M verified panel, AI-moderated video interviews, emotional signal analysis, and consultant-quality deliverables in under 24 hours.
- Enterprise teams ready to replace slow, fragmented research programs can see continuous customer intelligence in action with Listen Labs.
The Problem: Why Traditional Research Cycles No Longer Work
Enterprise research cycles move too slowly for modern product and marketing teams. A typical qualitative cycle runs 4–6 weeks from study design to final report. In large organizations, internal prioritization queues, budget approvals, and team backlogs often stretch that timeline to six months. By the time findings land, the product roadmap has shifted and the insights feel stale.
Cost compounds this timing problem. High-quality qualitative research requires specialized moderators, third-party panel providers, recruitment operations, transcription vendors, analysts, and report writers, each representing a separate vendor relationship. Because every handoff introduces delay, cost, and quality risk, these dependencies compound quickly. A single large study can reach hundreds of thousands of dollars, which limits most research teams to a handful of studies per quarter regardless of demand.
Panel quality adds another layer of risk that teams must manage. Opt-in commodity panels are structurally exposed to professional survey-takers, fraudulent profiles, and incentive-driven responses. Unlike probability-based panels that use address-based sampling and random selection to prevent large-scale bot and click-farm fraud, opt-in panels allow anyone to self-enroll. This structure creates persistent data quality problems that researchers must manually audit and clean.
The depth-versus-scale tradeoff sits at the center of every research planning conversation. Qualitative interviews deliver nuanced understanding but remain limited to small sample sizes. Quantitative surveys scale easily but sacrifice adaptive follow-up and emotional context. Organizations have historically been forced to choose one or the other. The shift toward continuous customer intelligence programs, where research becomes always-on infrastructure rather than a sequence of one-off projects, makes that forced choice increasingly untenable.
Five Criteria for Evaluating AI Market Research Tools
Five criteria determine whether a tool category is fit for enterprise-grade research in 2026. Speed measures how quickly a team moves from study brief to actionable deliverables. Depth vs. scale evaluates whether the tool can deliver adaptive, conversational insight across large sample sizes simultaneously. Participant quality reflects the rigor of fraud prevention, behavioral verification, and audience targeting. Emotional signals capture whether the platform records tone, micro expressions, and nonverbal cues beyond self-reported text. Security covers enterprise certifications, data handling practices, and compliance with global privacy regulations. Every category below is assessed against these five criteria, starting with the most established options.
Traditional Research Agencies and Consultancies
Traditional agencies deliver genuine methodological rigor for complex qualitative work. Experienced moderators, carefully designed discussion guides, and analyst-written reports remain the gold standard for depth. The tradeoffs are severe for teams that need speed and scale. Study setup alone takes weeks. Participant sourcing runs through third-party panels with variable quality controls. Moderation quality varies by individual researcher.
Traditional focus groups cost $4,000–$12,000 per 90-minute session and take 3–5 weeks to complete. Analysis is manual, subjective, and prone to confirmation bias. Emotional signals beyond what participants explicitly state are rarely captured. Cross-study knowledge management depends on individual researchers’ memories and scattered slide decks. Against the five criteria, agencies score well on depth, but only at small sample sizes and long timelines.
Quantitative Survey Platforms for Scale
Platforms such as SurveyMonkey and Qualtrics solve the scale criterion for many teams. Surveys reach thousands of respondents quickly and generate statistically significant data. Every other criterion suffers in comparison. Pre-set questions cannot adapt to unexpected answers. There is no probing, no follow-up, and no ability to uncover motivations that participants did not anticipate sharing.
Emotional signals are entirely absent from standard survey flows. Panel quality depends on whichever opt-in source the platform uses, which often introduces the same fraud risks described earlier. The result is broad data that answers “how many” but rarely answers “why.” For teams that need to understand behavior, not just measure it, survey platforms serve as a starting point rather than a complete solution.
Panel and Recruitment Tools for Finding Participants
Platforms such as Prolific, User Interviews, and Respondent focus on one specific problem: finding participants. They provide access to pools of potential respondents and handle scheduling logistics. They do not conduct interviews, analyze responses, or deliver findings. A team using a recruitment platform still needs a separate moderation tool, a transcription service, an analysis workflow, and a reporting process.
Fraud prevention varies significantly by provider, which introduces uneven risk across studies. Emotional intelligence sits entirely outside the scope of these tools. Panel and recruitment platforms function as a necessary component of a research stack, not as a complete solution for enterprise insights teams.
Analysis Repositories and Human-Moderated Interview Platforms
Tools such as Dovetail organize and analyze research that teams have already collected elsewhere. These systems are valuable for organizations managing large archives of past studies that need cross-study search or tagging. They cannot conduct new research, recruit participants, or capture emotional signals. Their value appears after data collection, not during it.
Human-moderated platforms such as UserTesting rely on a human-dependent moderation model that limits parallelization, slows turnaround, and caps the number of simultaneous interviews. Neither category resolves the depth-versus-scale tradeoff or delivers results in under 24 hours. They support research operations but do not transform the underlying speed and scale constraints.
Emerging AI Interview Solutions for Qual-at-Scale
The emerging category of AI-moderated interview platforms addresses speed and scale simultaneously for qualitative work. With qual-at-scale, the old tradeoff between depth and scale is no longer a barrier, because AI can conduct hundreds of adaptive, personalized interviews in parallel, analyze transcripts for themes, and generate quantitative insights from qualitative data. The category varies widely in execution, which matters for enterprise buyers.
Many platforms in this space rely on commodity opt-in panels with limited fraud prevention. Emotional intelligence is absent from most offerings. Enterprise security certifications appear inconsistently across vendors. Analysis capabilities range from basic transcript summaries to sophisticated multi-signal reporting. The critical differentiator within this category is whether the platform is truly end-to-end, covering recruitment, moderation, emotional analysis, and deliverable generation, or whether it handles only one or two steps and requires external vendors for the rest.
See how Listen Labs runs hundreds of emotionally intelligent AI interviews in under a day.
How Listen Labs Resolves Every Tradeoff
Listen Labs has conducted over 1 million AI-powered customer interviews for enterprises including Microsoft, Perplexity, and Sweetgreen, compressing research cycles that previously took weeks into the sub-24-hour delivery described earlier. The platform covers the entire research lifecycle in a single system.
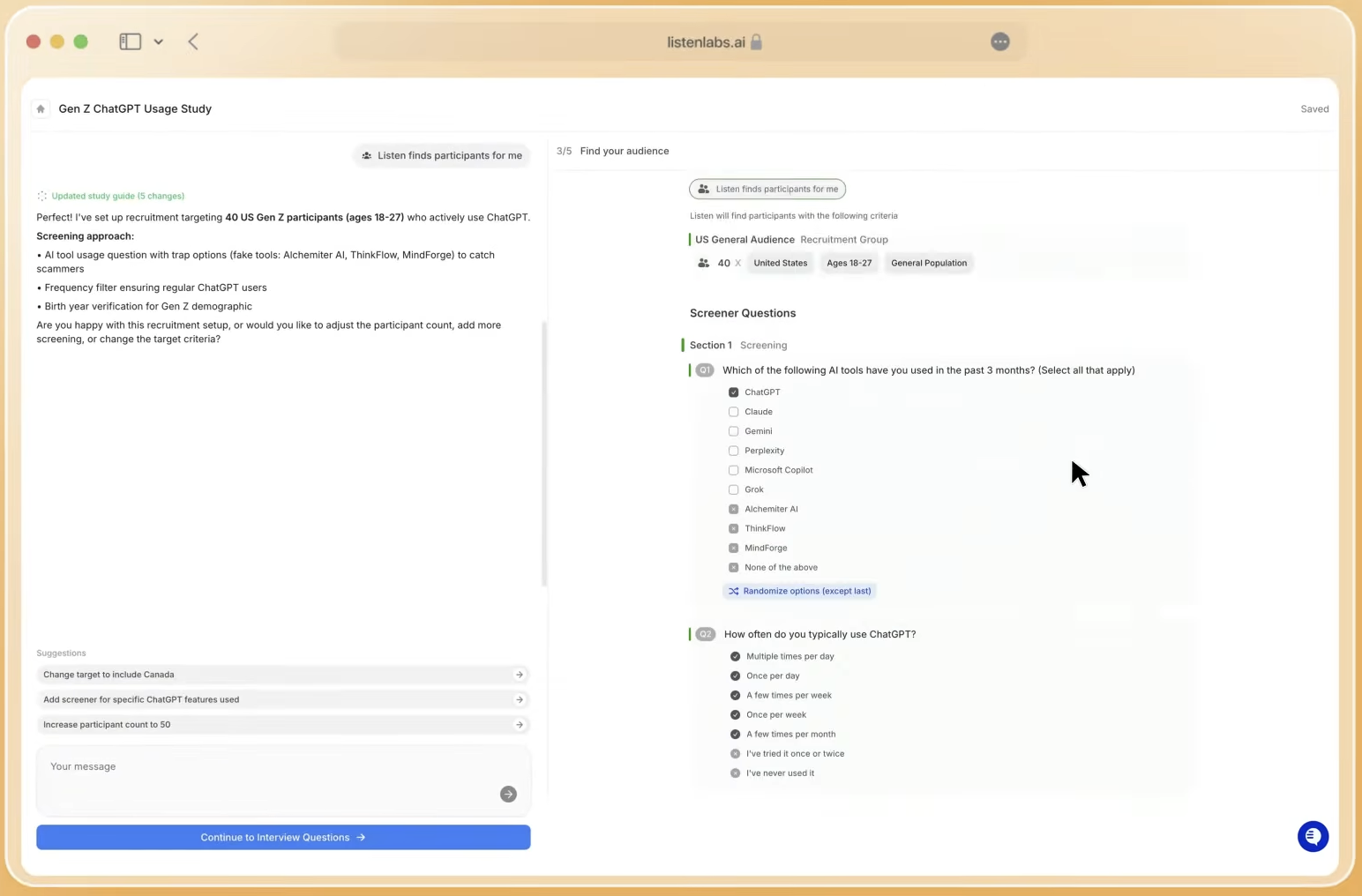
Participant quality starts with Listen Atlas, a global panel of 30M verified respondents across 45+ countries and 100+ languages. An AI orchestration layer matches participants on behavioral and intent data, not just self-reported demographics. Quality Guard monitors every interview in real time across video, voice, content, and device signals to detect fraud, low-effort responses, AI-generated scripts, and mismatched profiles. Participants are capped at three studies per month, which eliminates professional survey-takers. A dedicated recruitment operations team handles hard-to-reach segments such as enterprise decision-makers, healthcare workers, and audiences below 1% incidence rate. Organizations can also self-recruit from their own user base at reduced cost.
Depth at scale comes from AI-moderated video interviews that conduct personalized, adaptive conversations with dynamic follow-up questions. 92% of participants report top comfort levels in AI-moderated sessions, and 32% explicitly state they feel less judged by AI moderation, which creates a structural advantage for sensitive topics where social desirability bias distorts human-moderated results. Listen Labs enables teams to jump from question to findings in hours rather than the multi-week cycles described earlier, with hundreds of simultaneous one-on-one conversations running in parallel.
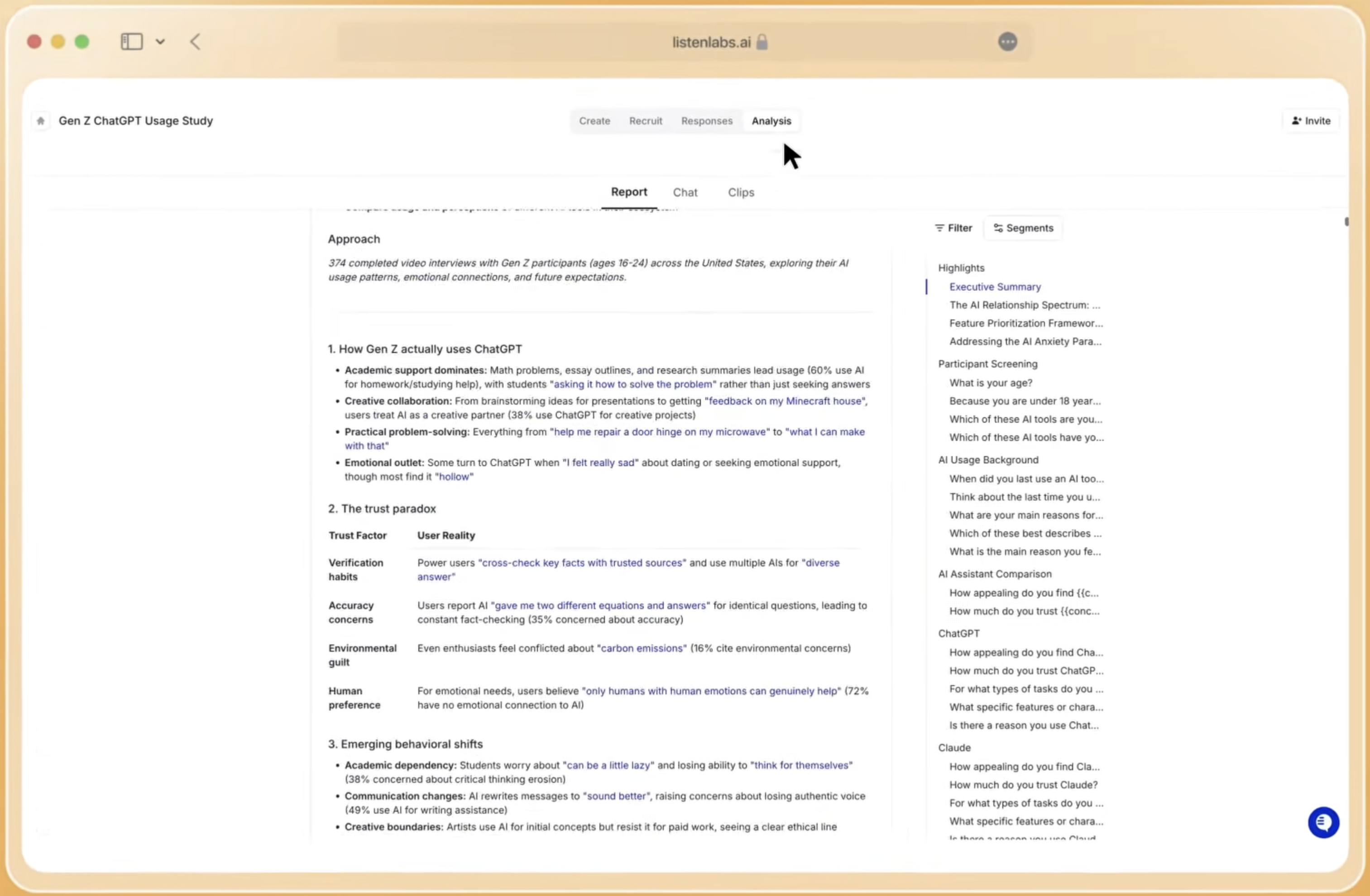
Emotional signals are captured through the Emotional Intelligence layer, which analyzes three signals, including tone of voice, word choice, and subconscious micro expressions, to surface emotions that transcripts alone miss. The framework is built on Ekman’s universal emotions standard used in clinical psychology and UX research, tracking anger, anticipation, disgust, fear, joy, sadness, trust, and surprise. Every emotion is quantified per question and concept, with every label traceable to the exact timestamp, verbatim quote, and AI reasoning behind it. Available across 50+ languages, the layer integrates directly with the Research Agent for natural-language queries, charts, and highlight reels.
Deliverables are generated by the Research Agent, which produces consultant-quality slide decks, memos, video highlight reels, statistical charts, segmentation breakdowns, and custom reports based on any natural-language question. All of these outputs arrive in under a minute. These outputs then feed into Mission Control, which serves as the organization’s permanent source of truth. This architecture enables cross-study queries, trend tracking, and institutional knowledge building, so teams stop re-researching questions already answered.
Security is covered by SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications, with 256-bit encryption and a strict policy against using customer data for AI model training. Enterprise SSO is supported for centralized access control.
Scenario-Based Best-Fit Guidance for Teams
Consumer Insights leaders at Fortune 500 companies facing growing backlogs and limited headcount need a platform that multiplies research output without proportional cost increases. Listen Labs compresses the full cycle to under 24 hours and delivers at a third of the cost of traditional agency research, which enables teams to run significantly more studies per quarter with the same team size. Microsoft’s Director of Data Science highlighted the ability to reach hundreds of users at one third of the cost, with leadership “very thrilled at both the speed and the scale.”
UX Research leads who need faster feedback loops for sprint cycles benefit from Listen Labs’ ability to test with 50–100+ participants instead of 5–10. Screen sharing and usability testing capabilities are built in. No-show rates and scheduling logistics disappear because interviews run asynchronously.
Product managers and marketing leaders without dedicated research teams can describe goals in natural language and have the platform handle study design, recruitment, moderation, and analysis automatically. This workflow removes the need for deep methodology expertise while still producing rigorous outputs.
Agencies and consultancies with client timelines measured in days rather than weeks can use Listen Labs to conduct rapid bespoke research across 45+ countries. These teams can reach niche audiences that standard panels cannot access and still deliver polished outputs on tight deadlines.
Decision Framework and Checklist for AI Research Platforms
Enterprise teams evaluating AI market research tools in 2026 should confirm several non-negotiables before committing to a platform. The platform must cover the full research lifecycle, including study design, recruitment, moderation, analysis, and deliverables, in a single system rather than relying on external vendors for key steps. It must operate a verified, non-commodity panel with real-time fraud prevention, behavioral matching, and participant frequency limits. It needs to conduct hundreds of adaptive, conversational interviews simultaneously instead of distributing only static surveys.
The platform should capture emotional signals beyond self-reported text, with traceable methodology and timestamp-level precision. It must hold SOC 2, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. It should build institutional knowledge across studies rather than treating each project as isolated. It also needs to support 100+ languages and 45+ countries for global programs. Any platform that cannot answer yes to all seven requirements forces teams to accept at least one of the tradeoffs described in this guide.
Walk through how Listen Labs scores on every item in this checklist for your specific research program.
Frequently Asked Questions
Can AI match human nuance in qualitative interviews?
AI-moderated interviews on a purpose-built platform can maintain the same level of methodological rigor as a well-resourced in-house research team. Listen Labs’ AI interviewer probes deeper on short or interesting answers, adapts dynamically to each participant’s responses, and conducts personalized conversations rather than following a fixed script. The platform is built by researchers with 50+ years of combined expertise who continuously refine the methodology.
For the vast majority of research objectives, including concept testing, usability studies, brand perception, churn analysis, and creative testing, AI-moderated interviews deliver comparable qualitative depth at dramatically greater speed and scale. Human moderation retains advantages in highly complex medical discussions and deeply empathy-driven topics, but these represent a small fraction of enterprise research needs.
How is participant fraud prevented at scale?
Listen Labs uses three reinforcing layers to prevent fraud. First, the platform works exclusively with high-quality, non-commodity panel sources, avoiding opt-in panels where anyone can self-enroll. Second, Quality Guard monitors every interview in real time across video, voice, content, and device signals, detecting fraudulent profiles, AI-generated scripts, low-effort responses, and mismatched participant characteristics before they contaminate the dataset. Third, participants are limited to three studies per month, which structurally eliminates professional survey-takers.
A dedicated recruitment operations team adds a human review layer for hard-to-reach segments. The Quality Guard reputation scoring system compounds over time. As more studies run on the platform, audience verification grows stronger, which creates a flywheel that point-in-time fraud checks cannot replicate.
Does an AI platform replace or augment existing research teams?
Listen Labs is designed as a force multiplier, not a replacement for researchers. The platform handles the logistics-intensive steps, including recruitment, scheduling, moderation, transcription, and initial analysis, that consume the majority of a research team’s time. This shift frees researchers to focus on strategic interpretation, stakeholder communication, and study design rather than operational execution.
Teams that previously ran a limited number of studies per quarter due to capacity constraints can run significantly more with the same headcount. The Research Agent generates consultant-quality deliverables automatically, while researchers retain full access to the underlying data, transcripts, and emotional signal breakdowns to conduct their own analysis.
What emotional signals do most tools miss?
Most research tools, including surveys, standard interview platforms, and basic AI tools, capture only what participants explicitly say. This approach leaves out three critical signal layers. Tone of voice reveals hesitation, confidence, or discomfort that words alone do not convey. Word choice patterns surface emotional framing and sentiment beyond surface-level sentiment scoring. Subconscious micro expressions are involuntary facial movements that occur in fractions of a second and reflect genuine emotional reactions before participants have time to self-censor.
Two concepts can receive identical positive ratings in a survey while triggering completely different emotional responses, with one generating genuine delight and the other producing flat or confused expressions. Without capturing these signals, teams make decisions on incomplete data. Listen Labs’ Emotional Intelligence layer captures all three signal types, quantifies them per question and concept using Ekman’s universal emotions framework, and makes every label traceable to a specific timestamp and verbatim quote.
Conclusion: Choosing the Right Platform for Continuous Intelligence
Every tool category assessed in this guide solves part of the problem. Traditional agencies deliver depth without speed or scale. Survey platforms deliver scale without depth or emotional signals. Panel tools deliver sourcing without moderation or analysis. Repository tools organize past research without conducting new research. Emerging AI platforms vary widely in panel quality, fraud prevention, emotional intelligence, and enterprise security.
Listen Labs is the only platform that eliminates the depth-versus-scale tradeoff while delivering emotional intelligence, enterprise-grade security, and a 30M verified panel in a single end-to-end system. Backed by Sequoia Capital, Ribbit Capital, and Conviction at a valuation over $500 million, and trusted by Microsoft, Perplexity, and Sweetgreen, Listen Labs turns a 4–6 week research cycle into the sub-24-hour delivery and cost advantage described earlier.
Enterprise teams ready to move from one-off research projects to continuous customer intelligence programs have one platform that resolves every tradeoff on the evaluation checklist.


