
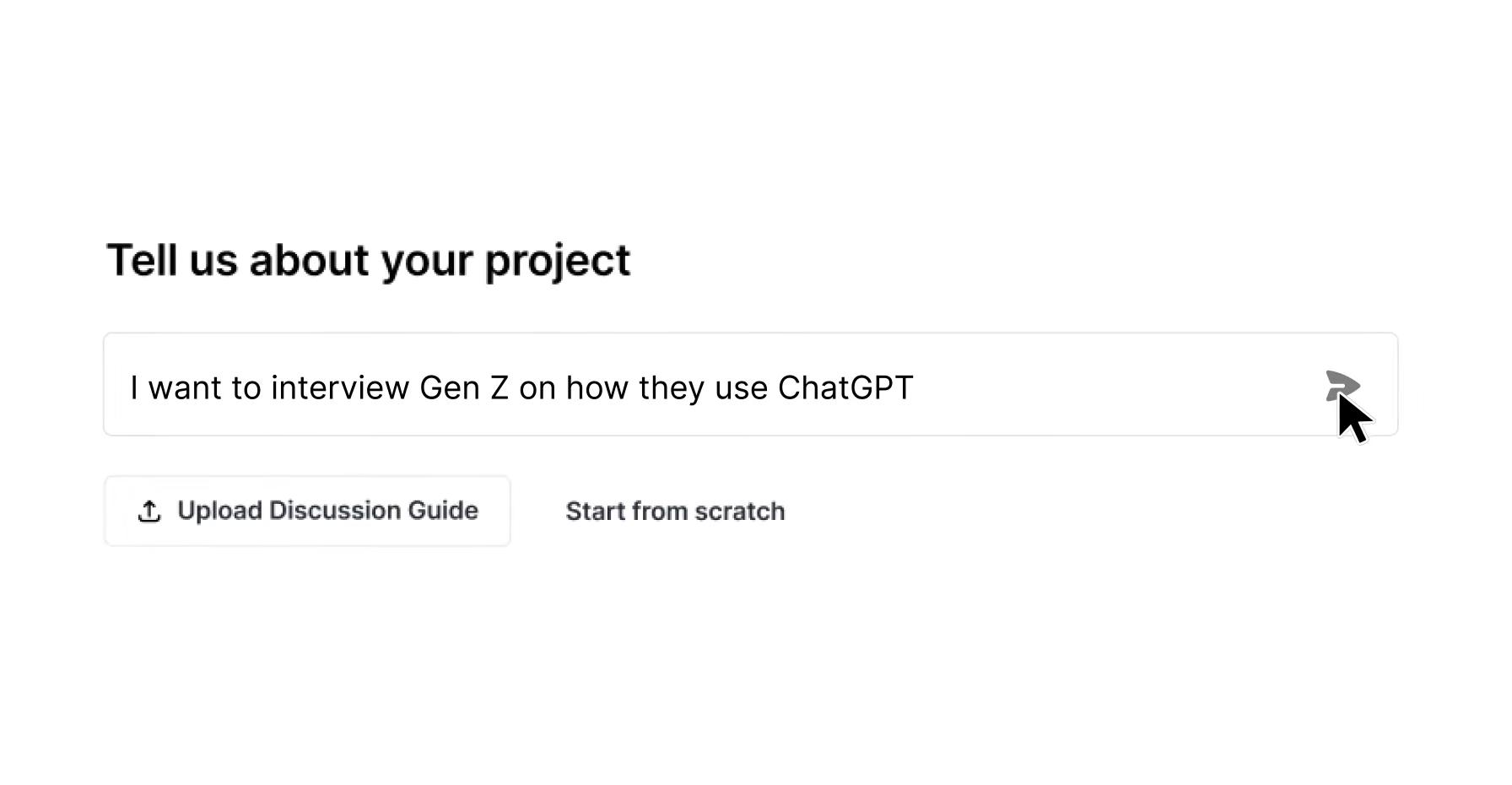
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways
- Generative AI qualitative research methods combine large language models with structured frameworks to conduct, transcribe, code, and synthesize interviews at enterprise scale while preserving interpretive depth.
- Enterprise teams can now run hundreds of adaptive interviews simultaneously and receive consultant-quality findings in under 24 hours instead of the traditional 4–6 week cycle.
- Responsible AI-assisted analysis follows an assist-and-review model where AI generates traceable code and theme suggestions that human researchers must validate and finalize.
- Compliance with GDPR, SOC 2 Type II, and ISO 42001, along with explicit consent language and privacy-preserving data architecture, is required for ethical AI-moderated research.
- Listen Labs delivers this end-to-end infrastructure with verified panels, real-time fraud detection, and traceable emotional intelligence—Book a demo to compress your next study from weeks to hours.
Transcription & Data Familiarization That Prevent Downstream Errors
The first stage in a generative AI qualitative workflow converts raw interview recordings into structured, searchable text and builds initial familiarity with the data. A disciplined approach here prevents downstream coding errors and reduces hallucination risk during analysis.
Enterprise teams that skip structured transcription workflows face coding mistakes and unreliable AI outputs later. The following four-step process establishes the data quality foundation that makes reliable AI-assisted analysis possible:
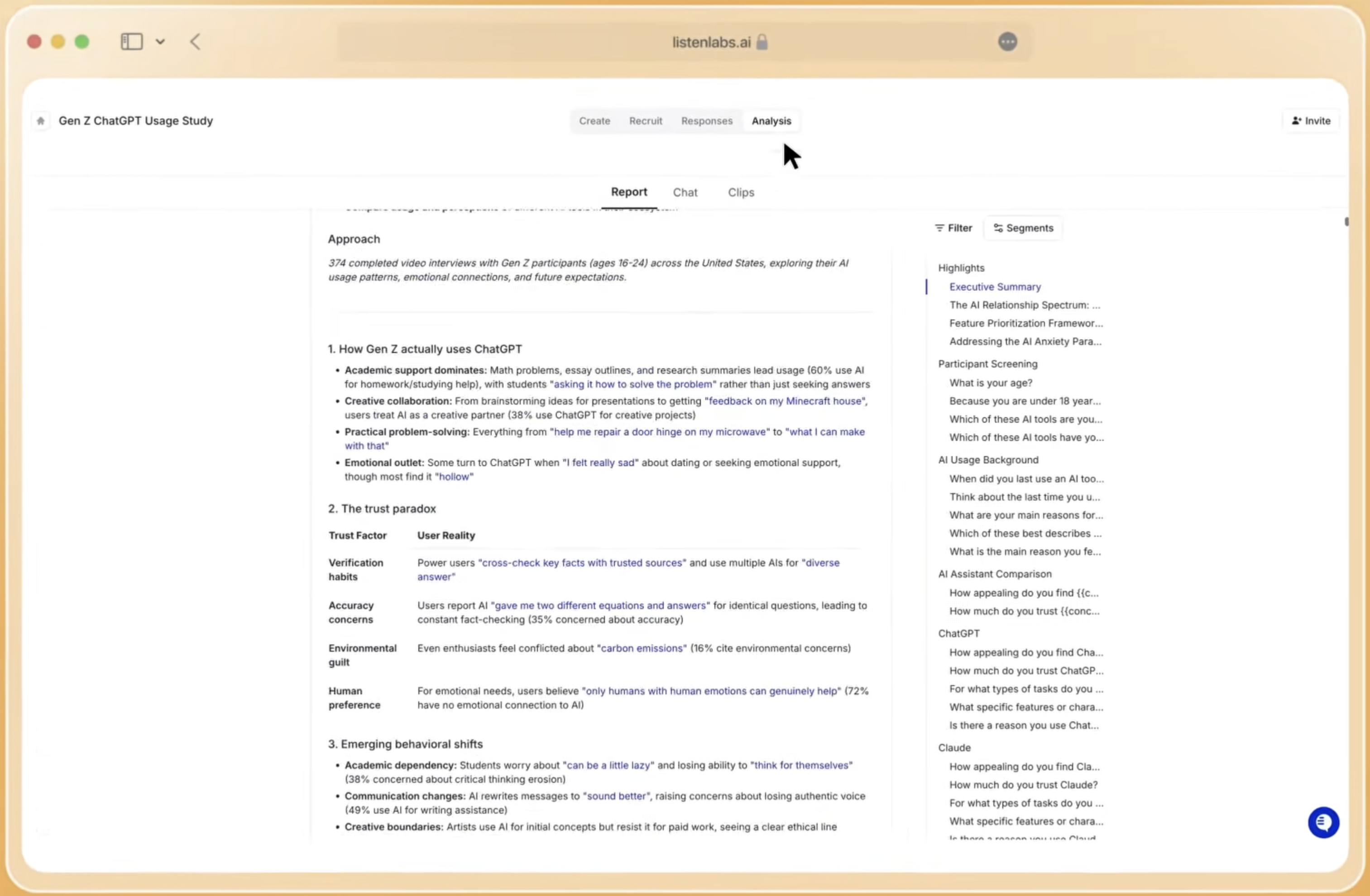
- Automated transcription: Run all video and audio recordings through a purpose-built transcription engine that preserves speaker turns, timestamps, and response boundaries. Platforms like Listen Labs layer auto-recruiting, transcription, sentiment tagging, and insight summarization so teams move from question to findings in hours, not weeks.
- Summarization pass: Generate a per-interview summary that captures the participant’s core narrative, key moments of emphasis, and notable hesitations or emotional signals flagged by multimodal analysis.
- Familiarization review: Assign a human researcher to review a stratified sample of full transcripts, not just summaries, before coding begins. This step preserves the interpretive grounding that Ayik et al. (2026) in Qualitative Inquiry identify as the primary differentiator between AI-generated and human-generated thematic outputs.
- Timestamp anchoring: Link every transcript segment to its source timestamp and verbatim quote so any claim made during analysis traces back to the original recording.
Before moving to the coding stage, verify that your data meets these five quality gates. Each one prevents a specific category of analysis error:
- All recordings transcribed with speaker-turn accuracy confirmed, which protects attribution reliability in the final report.
- Timestamps preserved at the segment level, which enables traceable claims in the analysis phase.
- Human researcher has reviewed at least 15–20% of full transcripts, which establishes interpretive grounding before AI coding begins.
- Summaries cross-checked against source recordings for accuracy, which catches AI summarization errors early.
- Sensitive or emotionally charged passages flagged for careful handling in the coding stage, which prevents ethical missteps during automated analysis.
AI-Assisted Coding & Thematic Analysis With GAITA
Structured prompting frameworks significantly improve the reliability of AI-assisted coding. Kien Nguyen-Trung’s Guided AI Thematic Analysis (GAITA) framework, introduced in November 2025 and adapted from King et al.’s Template Analysis, positions the researcher as the reflexive instrument and intellectual leader. Generative AI serves as a guided tool rather than a replacement for interpretation. GAITA structures the workflow into four stages: data familiarization, preliminary coding, template formation and finalization, and theme development.
The following GAITA-inspired workflow translates that structure into concrete steps for enterprise teams:
- Preliminary coding: Prompt the AI to generate an initial code list restricted explicitly to the provided dataset. Ayik et al. 2026 showed that reasoning models produced lower factual accuracy (hallucinations) under strict dataset-only constraints, while non-reasoning models maintained accuracy but frequently violated the constraints. Dataset-only prompting therefore becomes a critical safeguard for enterprise research integrity.
- Template formation: Cluster preliminary codes into candidate themes using the AI, then have a human researcher evaluate whether each cluster reflects genuine interpretive meaning or surface-level frequency patterns. The interpretive grounding gap identified earlier manifests here as AI’s tendency to rely on frequency patterns rather than deeper meaning, which makes human review at this stage non-negotiable.
- Template finalization: Revise, merge, or reject AI-proposed themes based on researcher judgment. Record every decision with a short rationale note.
- Theme development: Write theme narratives that integrate verbatim evidence, emotional signal data, and researcher interpretation. Link every insight directly to the underlying response data.
The GAITA workflow depends on prompt discipline at every stage. Use this five-point checklist to structure your AI requests; each item addresses a documented failure mode from the Ayik et al. study:
- Restrict the AI explicitly to the provided dataset in every prompt, which reduces hallucinations and scope creep.
- Embed the study’s theoretical framework directly into zero-shot or few-shot classification prompts, as Garcia Quevedo and Kuri (2026) recommend, which aligns outputs with your analytic lens.
- Request traceable outputs that include code label, supporting verbatim, and timestamp reference, which enables efficient auditing.
- Validate AI outputs against at least one alternative method before finalizing themes, which guards against single-model bias.
- Document all prompt iterations and output revisions in a decision log, which creates an audit trail for regulators and stakeholders.
Listen Labs’ Research Agent handles the full analysis workflow from raw data to final output, with every insight linking directly to the underlying response data. This makes traceable, auditable thematic analysis available at scale without manual overhead.
Ethical & Consent Standards for AI-Moderated Qualitative Research
The 2026 regulatory environment for generative AI in qualitative research is defined by three overlapping compliance frameworks: GDPR, SOC 2 Type II, and ISO 42001, the international standard for AI management systems. Enterprise teams operating across multiple jurisdictions must satisfy all three simultaneously, which requires consent language and data handling protocols designed specifically for AI-moderated research contexts.
George Mason University’s AI ethics guidelines require researchers to fully and explicitly include any use of AI in research processes involving human subjects in their IRB protocols. They also prohibit uploading personally identifiable information into AI tools that lack approved protected environments. The same guidelines identify six core AI ethics principles applicable to qualitative research: human oversight, transparency, compliance, data privacy, critical thinking, and accuracy.
University of Virginia’s generative AI ethics guidance adds that transparency requires researchers to disclose any use of generative AI tools and to maintain clear accountability for AI-assisted decisions. This requirement maps directly onto the need for traceable coding outputs described in the previous section.
Consent language for AI-moderated interviews should explicitly state four elements. First, that the interview will be conducted by an AI moderator. Second, how video, audio, and transcript data will be stored and processed. Third, whether emotional signal analysis will be applied. Fourth, the data retention period and deletion rights under applicable law. Susanne Friese’s 2026 analysis argues that participant consent alone is insufficient justification for feeding interview data into generative AI tools; the data handling architecture itself must be privacy-preserving by design.
Listen Labs maintains GDPR, SOC 2 Type II, ISO 27001, ISO 27701, and ISO 42001 certifications, with 256-bit encryption and a policy that customer data is never used for AI model training. These measures satisfy the structural privacy requirements that consent language alone cannot address and establish the infrastructure foundation for ethical AI research.
Human Validation Protocols That Keep Researchers in Control
The “assist-and-review” model is the methodological standard for responsible AI-assisted qualitative analysis in 2026. Under this framework, AI generates traceable suggestions for codes and themes that researchers can accept, revise, or reject, which keeps interpretive decisions with the human analyst, as the MAXQDA AI Assist approach documented by Ayik et al. (2026) demonstrates.
The risk of overreliance on AI is well-documented. Dell’Acqua et al. (2023) describe a “jagged technological frontier” in which generative AI substantially improves productivity on tasks within its capability boundary but reduces performance on tasks just beyond it because users trust plausible but incorrect outputs. This dynamic applies directly to qualitative coding when researchers accept AI theme labels without interrogating their interpretive basis.
Garcia Quevedo and Kuri (2026) caution that overreliance on LLMs risks epistemic homogenization, or the flattening of diverse, context-dependent meanings. They require researchers to maintain critical oversight, document analytical decisions, and validate AI outputs against human interpretation.
A practical human validation protocol for enterprise teams includes five steps:
- Assign a senior researcher to review all AI-generated theme labels before any deliverable is drafted.
- Cross-check a random sample of AI-coded segments against the source transcript and timestamp.
- Run a secondary coder on 10–15% of the dataset and calculate agreement rates.
- Document every instance where AI output was revised or rejected, with a written rationale.
- Flag emotionally sensitive passages for mandatory human review before inclusion in reports.
Timestamp-level traceability forms the technical foundation for this framework. When every AI-generated code or emotion label links to an exact timestamp, verbatim quote, and the reasoning behind it, human reviewers can audit the analysis efficiently without re-reading entire transcripts.
Scaling Qualitative Research to Hundreds of Interviews
The structural barrier to qual-at-scale has historically been threefold: recruiting verified participants at volume, maintaining interview quality across hundreds of simultaneous sessions, and processing the resulting data without proportional increases in analyst headcount. Qual-at-scale works best when research requires large sample sizes or broad geographic reach, because AI tools can engage hundreds or thousands of participants remotely and asynchronously, collapsing the old trade-off between depth and scale.
Listen Labs addresses the recruitment barrier through Listen Atlas, an AI orchestration layer that matches across behavioral and intent data within a global panel of 30M verified respondents spanning 45+ countries and 100+ languages. Quality Guard monitors every interview in real time for fraud, low-effort responses, and repeat respondents, with participants limited to three studies per month to eliminate professional survey-takers. Switching to AI-moderated interviews let Chubbies capture hundreds of candid, one-to-one conversations overnight, which illustrates the practical turnaround that verified panel infrastructure enables.
Emotional signal capture at scale is addressed through Listen Labs’ Emotional Intelligence feature, which analyzes three layers of signal: tone of voice, word choice, and subconscious micro expressions. This approach surfaces emotions that transcripts alone miss. Built on Ekman’s universal emotions framework, the same standard used in clinical psychology and UX research, every emotion is quantified per question and concept, with every label traceable to the exact timestamp, verbatim quote, and AI reasoning behind it. A researcher can query which concept triggered the most confusion at a specific timestamp across a demographic segment and receive a side-by-side emotional breakdown across stimuli, segments, and markets.
This level of technical capability is precisely what many marketing teams lack the training to build themselves. Kantar’s January 2025 qualitative GenAI study found that a majority of marketers feel unprepared for GenAI due to lack of role-specific training, a gap that purpose-built platforms with embedded methodological guardrails are designed to close without requiring teams to develop AI expertise from scratch.
Common Pitfalls in AI Qual & How to Avoid Them
Overreliance on AI outputs without human interpretive oversight is the most frequently documented failure mode in 2026. Ayik et al. (2026) found that AI tools in their comparative study often required revision or rejection by a trained researcher. Treating AI output as final analysis rather than a structured first draft remains the primary source of methodological error.
Cultural nuance presents a second category of risk. Tone in AI is subjective and culturally dependent; what sounds neutral in one context may feel rude or inappropriate in another, depending on platform norms, user sentiment, power dynamics, and regional idioms. Enterprise teams conducting multi-market research must validate AI-generated themes against local cultural context, not just translated verbatims. Listen Labs supports 100+ languages for interview moderation with built-in localization, but cultural interpretation of findings still requires researcher judgment grounded in market knowledge.
Data quality degradation is a third pitfall specific to panel-based research at scale. Commodity panels introduce professional survey-takers, fraudulent profiles, and incentive-driven responses that corrupt thematic analysis regardless of how sophisticated the AI coding layer is. 92% of participants report top comfort levels in AI-moderated sessions, and 32% explicitly state they feel less judged with AI moderation. These honesty benefits only materialize when the underlying participant pool is verified and fraud-controlled.
Mitigation steps for each pitfall include four targeted actions:
- Overreliance: Implement the assist-and-review protocol described above and never publish AI-generated themes without documented human review. This addresses the interpretive depth gap that AI tools cannot close on their own.
- Cultural nuance: Assign market-specific researchers to review findings from non-home-market studies and use localized probing questions rather than direct translation of home-market guides. Local context prevents the meaning-flattening that pure translation introduces.
- Data quality: Use platforms with real-time fraud detection, behavioral matching, and participant frequency limits rather than commodity panel sources. Verified participants form the foundation, because sophisticated analysis cannot rescue corrupted input data.
- Emotional limitations: Supplement transcript-based analysis with multimodal emotion capture for studies where emotional response is a primary research objective. Transcripts alone miss the tonal and non-verbal signals that reveal true sentiment.
Evaluation Framework & Next Steps for Enterprise Teams
Before deploying generative AI qualitative research methods at enterprise scale, teams benefit from an internal readiness audit that maps current capabilities against the workflow requirements described in this playbook.
Use this internal readiness checklist to structure that audit:
- Transcription infrastructure supports timestamp-level traceability, enabling audit-ready analysis.
- Coding workflow follows an assist-and-review model with documented human oversight.
- Consent language explicitly discloses AI moderation and emotional signal analysis.
- Data handling architecture satisfies GDPR, SOC 2, and ISO 42001 requirements.
- Participant recruitment uses verified, fraud-controlled panel sources with frequency limits.
- Cultural review process exists for multi-market studies.
- Analysis outputs link every claim to a source timestamp and verbatim quote.
- Deliverable generation is automated but reviewed by a senior researcher before distribution.
Teams that pass this audit are ready to pilot generative AI qualitative research methods on a bounded study, ideally a concept test or brand perception study with a defined sample size and a clear comparison point against a previous traditionally conducted study. The pilot should measure time-to-insight, analyst hours per study, and stakeholder satisfaction with deliverable quality.
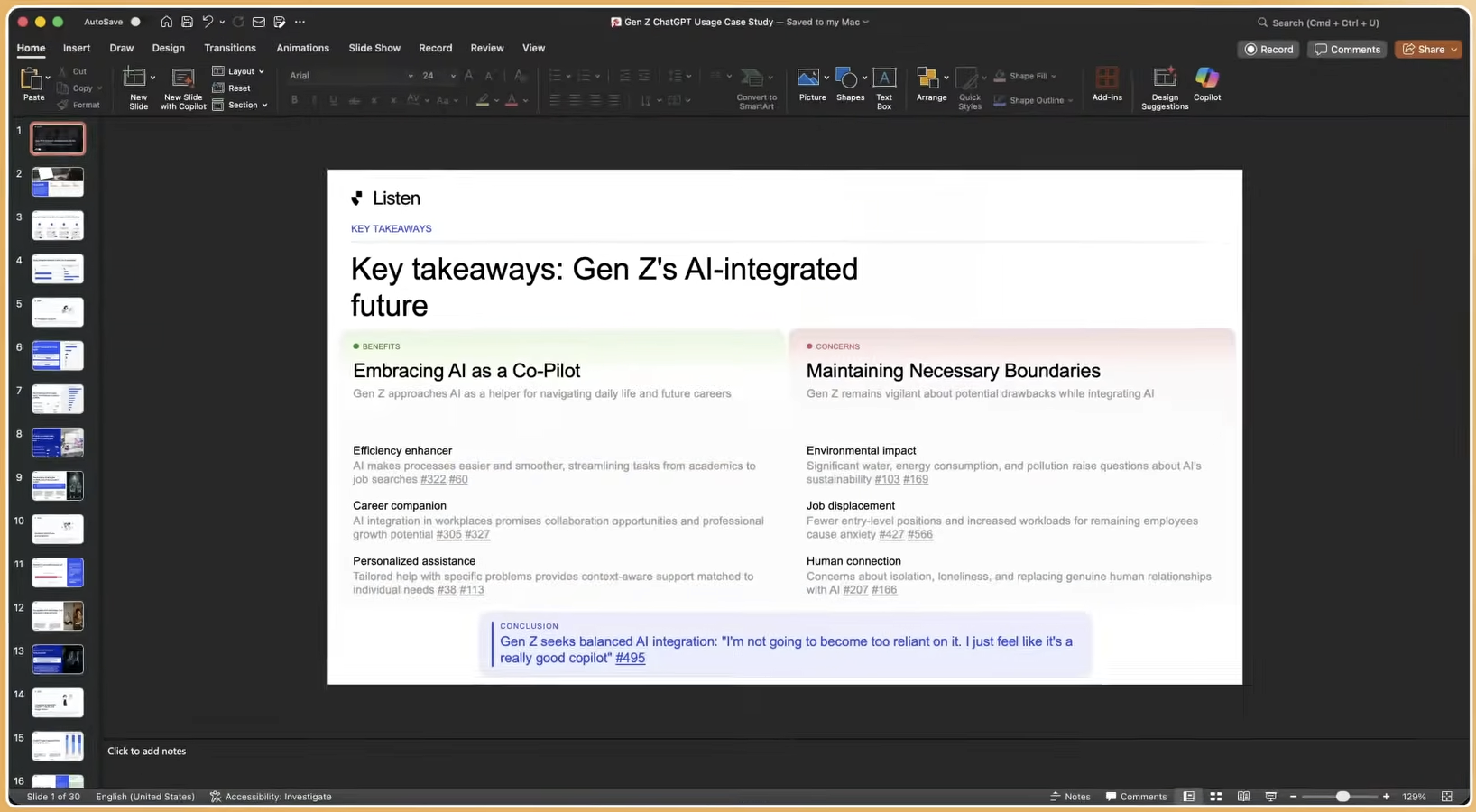
Teams that identify gaps in the audit should prioritize platform consolidation before methodology expansion. Fragmented toolchains, with separate vendors for recruitment, moderation, transcription, and analysis, introduce the same delays and quality risks that generative AI methods are designed to remove. An end-to-end platform that covers the full research lifecycle from study design through verified recruitment, AI-moderated interviews, automated analysis, and deliverable generation is the infrastructure prerequisite for the methods described in this playbook.
Listen Labs is trusted by Microsoft, Anthropic, Procter & Gamble, and Skims to deliver that infrastructure, compressing research cycles from weeks to hours while maintaining the methodological credibility that enterprise insights teams require. Book a demo to run your pilot study on Listen Labs and see consultant-quality results in under 24 hours.
Frequently Asked Questions
What is the difference between generative AI qualitative research methods and traditional qualitative research?
Traditional qualitative research relies on human moderators to conduct interviews one at a time, human analysts to code transcripts manually, and human report writers to synthesize findings. This process typically takes 4–6 weeks from study design to final deliverable. Generative AI qualitative research methods automate the time-intensive operational layers of this process. AI moderators conduct hundreds of adaptive, personalized interviews simultaneously. AI coding engines generate traceable theme candidates from transcripts. AI analysis tools then produce structured deliverables in minutes. The human researcher’s role shifts from executing logistics to designing studies, reviewing AI outputs, applying interpretive judgment, and communicating findings to stakeholders. The methodological standards, including rigorous sampling, traceable analysis, ethical consent, and cultural sensitivity, remain unchanged. The speed and scale at which those standards can be applied change dramatically.
How does AI thematic analysis compare to human thematic analysis in terms of accuracy?
Comparisons of AI to human thematic analysis show that AI tools can accelerate the process but typically require human oversight to ensure alignment with human interpretation. Human analysis requires substantial time, while AI tools can generate initial outputs faster. Ayik et al. 2026 showed that reasoning models produced lower factual accuracy (hallucinations) under strict dataset-only constraints, while non-reasoning models maintained accuracy but frequently violated the constraints. The practical implication for enterprise teams is that AI thematic analysis functions as a reliable first-pass tool that substantially reduces analyst time but requires human review and revision before findings can be treated as final. The assist-and-review model, where AI generates traceable suggestions and humans make all final interpretive decisions, is the methodologically sound approach for 2026.
What ethical safeguards are required when using AI-moderated interviews for market research?
Enterprise teams deploying AI-moderated interviews for market research need safeguards at three levels. First, consent: participants must be explicitly informed that the interview is AI-moderated, how their video, audio, and transcript data will be processed, whether emotional signal analysis will be applied, and what their data deletion rights are under applicable law. Second, data architecture: the platform handling interview data must operate in a privacy-preserving environment that does not use participant data for AI model training and must satisfy GDPR, SOC 2 Type II, and ISO 42001 requirements at minimum. Third, fraud and quality control: AI-moderated research at scale is only as reliable as the participant pool. Real-time fraud detection, behavioral matching on intent data rather than self-reported demographics, and participant frequency limits are structural safeguards that protect data integrity regardless of how sophisticated the analysis layer is. Listen Labs addresses all three levels through its consent infrastructure, enterprise security certifications, and Quality Guard fraud detection system.
Can generative AI capture emotional nuance in qualitative research?
Generative AI tools that rely solely on transcript analysis have documented limitations in capturing emotional nuance, particularly for irony, tone, cultural subtext, and non-verbal signals. These limitations are well-recognized in the research community and are the primary reason that transcript-only AI analysis requires human interpretive oversight. Multimodal emotion capture, which analyzes tone of voice, word choice, and facial micro expressions simultaneously, substantially extends AI’s ability to surface emotional signals that transcripts miss. Listen Labs’ Emotional Intelligence feature applies Ekman’s universal emotions framework across all three signal layers, quantifying emotions per question and concept with every label traceable to the exact timestamp and verbatim quote. This approach does not replace researcher interpretation of emotional findings, but it provides a structured, auditable evidence base that makes emotional analysis scalable and reproducible across hundreds of interviews.
How long does it take to complete a qualitative research study using Listen Labs?
Listen Labs compresses the full research lifecycle, including study design, participant recruitment, AI-moderated interviews, analysis, and deliverable generation, to under 24 hours for most study types. The 24-hour turnaround applies to studies drawing from Listen Labs’ 30M verified respondent panel. Studies requiring niche or hard-to-reach audiences may take longer depending on incidence rate and geographic scope. The Research Agent generates slide decks, memos, highlight reels, and statistical charts in under a minute once interview data is collected, which removes the report-writing bottleneck that typically adds days or weeks to traditional research timelines. For real-world benchmarks, see the Anthropic and Microsoft examples in the Scaling section.


