
Written by: Anish Rao, Head of Growth, Listen Labs
What Enterprise Teams Need to Know Right Now
- AI-moderated platforms like Listen Labs complete full research cycles in under 24 hours versus the 4–6 weeks (or longer) required by traditional agency workflows.
- Listen Labs preserves qualitative depth at scale through adaptive AI moderation and an Emotional Intelligence layer that quantifies emotional signals across 50+ languages.
- Enterprise-grade fraud controls, including Quality Guard, participant caps, and reputation scoring, reduce fraudulent responses far below the 30–40% rates common in traditional online panels.
- Listen Labs replaces multiple vendors with a single platform that delivers traceable, auditable outputs while cutting costs by roughly two-thirds and supporting 100+ languages globally.
- Teams ready to modernize their research programs can schedule a platform walkthrough with Listen Labs to experience these capabilities in action.
Research Speed for Modern Enterprise Timelines
Traditional qualitative research cycles run four to six weeks from study design to final report delivery. In large enterprises, internal prioritization queues, budget approvals, and vendor coordination routinely extend that timeline to three to six months. By the time findings land, product roadmaps have shifted and campaign windows have closed.
AI-moderated platforms compress the same lifecycle to the sub-24-hour timeframe. Platforms like Listen Labs layer on auto-recruiting, transcription, sentiment tagging, and insight summarization so teams jump from question to findings in hours, not weeks. For UX teams running two-week sprints, traditional research timelines mean findings arrive after decisions have already been made, so research documents choices instead of shaping them. This timing mismatch explains why many enterprises are shifting to continuous intelligence programs, where insights feed product, brand, and pricing decisions on a rolling basis. These programs are structurally impossible under four-to-six-week cycles and become routine once cycles compress to under a day.
Depth of Insight with AI-Moderated Interviews
The speed advantage naturally raises a concern about depth. Many leaders worry that compressing research cycles from weeks to hours will sacrifice the qualitative nuance that makes research valuable. The persistent criticism of AI-moderated research is exactly that it trades nuance for speed. That criticism applied to first-generation survey automation tools. It does not apply to adaptive AI interview platforms. Qualitative data methods make up for their traditional limitations in speed and sample size tenfold in their ability to uncover nuance and complexity in human decision-making, and AI now preserves that advantage at scale.
Listen Labs’ Emotional Intelligence layer extends depth beyond what any transcript captures by addressing a core limitation of traditional research: participants often cannot or will not articulate their true emotional responses. Emotional Intelligence analyzes tone of voice, word choice, and subconscious micro expressions, surfacing emotional states that participants never verbalize. Every emotion is quantified per question and concept, with every label traceable to the exact timestamp, verbatim quote, and AI reasoning behind it. The framework is built on Ekman’s universal emotions framework, the same standard used in clinical psychology and UX research, covering anger, disgust, fear, happiness, sadness, surprise, and neutral states across 50+ languages. Human moderators capture emotional cues inconsistently and rarely quantify them. The AI captures them at every timestamp, across every participant, simultaneously.
Sample Quality and Fraud Controls That Scale
An estimated 30–40% of online survey responses are fraudulent or unusable, driven by human click farms, coordinated fraud rings, and increasingly sophisticated AI agents. AI agents can now complete full 25-minute surveys, including screeners, attention checks, and image-based items, while appearing attentive and human-like using only commercially available tools. Traditional attention checks and trap items no longer provide sufficient defense.
Fraud in qualitative research is accelerating with bots, duplicate accounts, VPN submissions, AI-assisted responses, and organized fraud rings now appearing in interviews and focus groups. The most effective way to fight fraud is recruiting real people through a panel created with a methodology that makes fraud extremely difficult from the start.
Listen Labs addresses this through three compounding layers that work together to filter fraud at different stages. Quality Guard monitors every interview in real time across video, voice, content, and device signals, catching fraudulent behavior during the session itself. Participants are capped at three studies per month, which removes professional survey-takers who might otherwise appear legitimate in any single session. A dedicated recruitment ops team adds human review for hard-to-reach segments where automated screening alone is not enough. The platform’s reputation scoring compounds with every study completed, creating a quality flywheel that commodity panels cannot replicate.
See Quality Guard in action during a live platform demonstration.
Participant Sourcing Reach for Niche Audiences
Traditional agency recruitment is constrained by geography, incidence rate, and recruiter networks. Studies targeting sub-1% audiences such as enterprise decision-makers, healthcare specialists, or highly specific consumer segments can take weeks to fill and frequently miss quotas. Qualitative recruitment often relies on nonprobability, opt-in sources such as social media ads, online intercepts, and loosely vetted databases, which can increase bias and vulnerability to fraud.
Listen Labs’ Listen Atlas network covers 30 million verified respondents across 45+ countries and 100+ languages, with an AI orchestration layer that matches participants on behavioral and intent data rather than self-reported demographics alone. A dedicated recruitment ops team sources audiences below 1% incidence rate. Listen Labs has run over 1 million AI-powered customer interviews for companies including Microsoft, Perplexity, and Sweetgreen, demonstrating that global reach at this scale is operational, not theoretical.
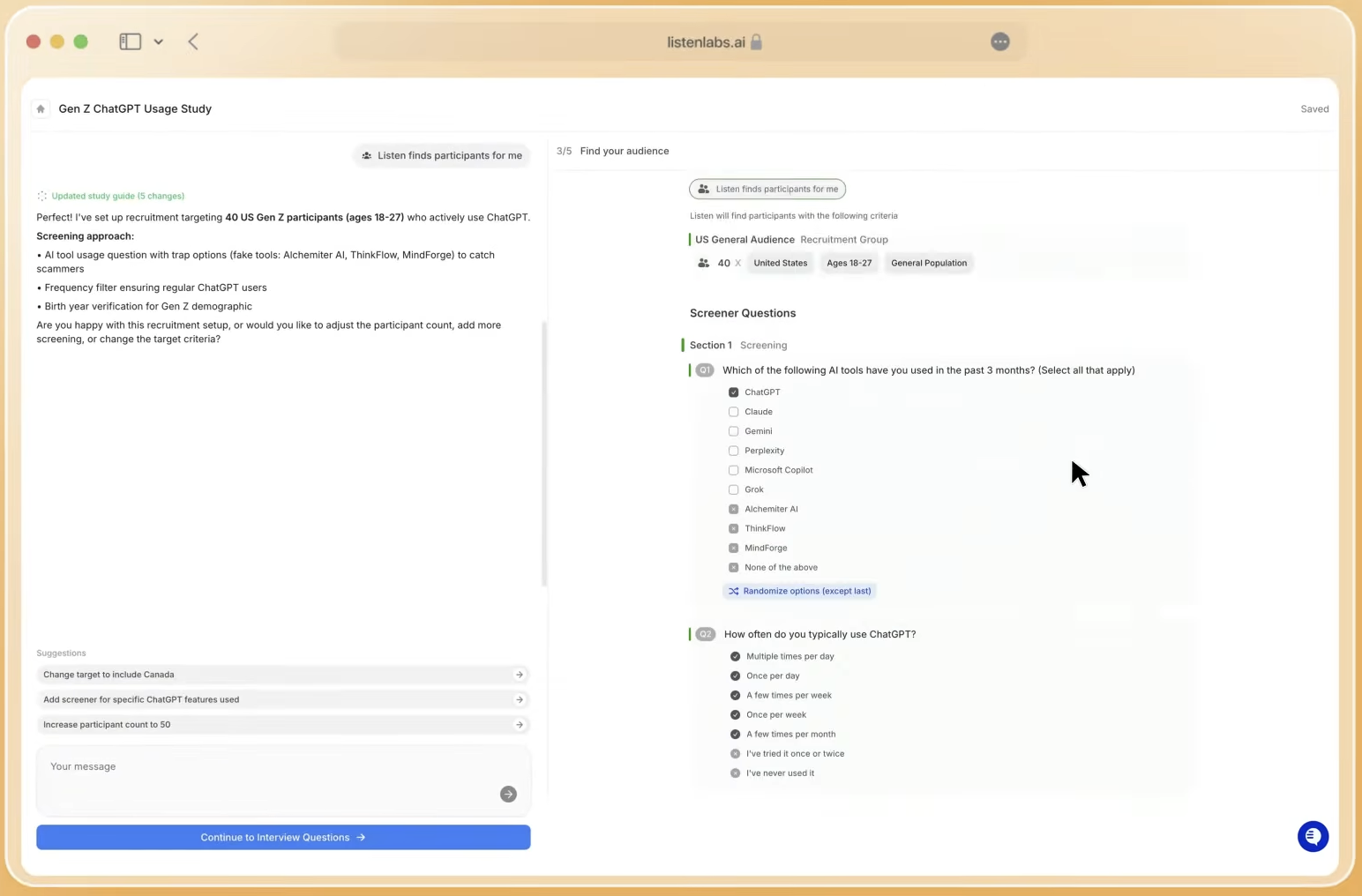
Methodological Flexibility Across Study Types
Traditional agencies offer deep customization through experienced moderators who adapt discussion guides in real time. That flexibility carries a cost, because each customization requires moderator briefing, pilot sessions, and manual QA cycles that add days to the timeline.
AI-moderated platforms now support comparable flexibility through AI-assisted co-design, template libraries, stimuli logic for images, video, audio, PDFs, and live URLs, monadic and sequential randomization, branching, skip logic, piping, and mixed-methods formats that combine qualitative depth with Likert scales, NPS, MaxDiff, and sliders. AI can schedule and conduct the interview, analyze transcripts for themes, and generate quantitative insights from those interviews within a single study design.
Global and Multilingual Research at Consistent Quality
Global programs test both methodological flexibility and operational reach. Running a multi-market study through traditional agencies requires coordinating local vendors in each country, managing translation quality across teams, and reconciling inconsistent moderation styles. A six-country study can involve six separate vendor relationships and six separate quality standards.
Listen Labs conducts interviews in 100+ languages with automatic translation and transcription built into the platform. Emotional Intelligence operates across 50+ languages, so emotional signal capture stays consistent whether the participant speaks English, Mandarin, Portuguese, or Arabic. The Microsoft engagement illustrates the practical outcome: the team collected global customer stories for Microsoft’s 50th anniversary within a single day, and leadership described the speed and scale as outcomes they had not previously considered achievable.
Analysis Effort, Bias, and Institutional Memory
Researchers spend the bulk of their time in analysis: finding patterns, quantifying insights, testing significance, adding macro context, and formatting results for stakeholders who each need something different. Human coding of qualitative data is time-intensive and subject to confirmation bias, because analysts unconsciously weight findings that confirm existing hypotheses.
Research Agent handles the full analysis workflow from raw data to final output, generating automated key findings, theme analysis, segmentation breakdowns, statistical significance tests, and stakeholder-ready deliverables. One researcher ran a full buying intent analysis across three user segments in under a minute. Every insight links back to the underlying response data, making the analysis auditable rather than opaque. Mission Control then stores all findings as a queryable institutional knowledge base, so teams stop re-researching questions already answered in prior studies.
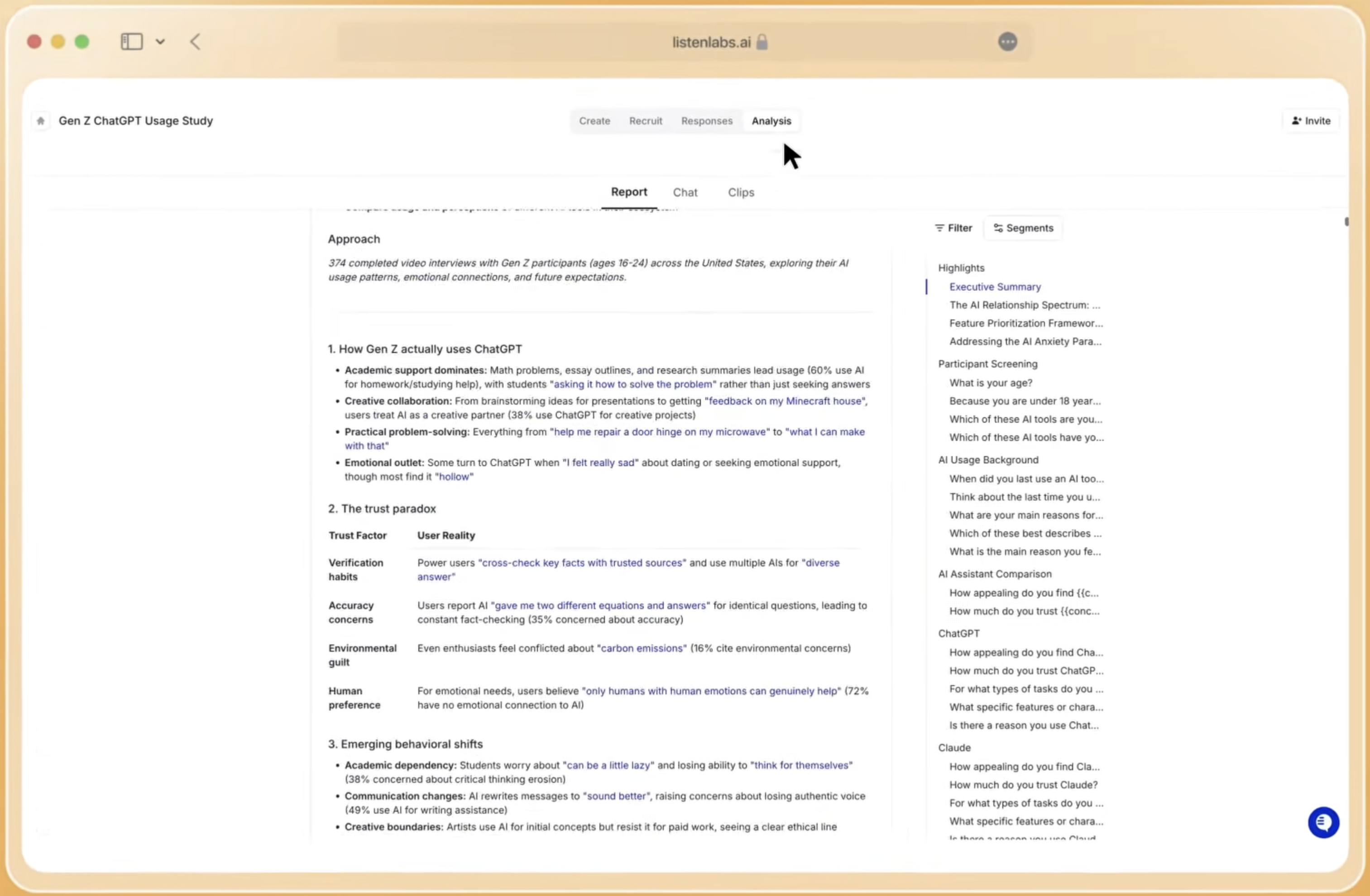
Reporting Transparency and Governance for Enterprises
Traditional agency reports are narrative documents. The reasoning behind a finding is rarely traceable to specific participant responses, and the methodology is often summarized rather than documented. For enterprise compliance teams and legal reviewers, that opacity creates risk.
Listen Labs produces outputs where every insight links to the verbatim quote, timestamp, and AI reasoning that generated it. The platform holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. Customer data is never used for AI model training. Enterprise SSO is supported. For regulated industries and global enterprises with data residency requirements, that governance stack functions as a prerequisite, not a differentiator.
Scalability and Operational Load on Research Teams
Scaling traditional qualitative research requires proportional increases in moderator headcount, panel spend, transcription vendors, and analyst capacity. A team running ten studies per quarter cannot run forty without roughly quadrupling its operational infrastructure.
Qual-at-scale is ideal when research requires large sample sizes or broad geographic reach, as AI tools can engage hundreds or thousands of participants remotely and asynchronously. Listen Labs replaces multiple disconnected vendors for recruitment, scheduling, moderation, transcription, analysis, and reporting with a single platform at one-third the cost of the traditional approach. The Microsoft team reported reaching hundreds of users at that reduced cost compared with their previous process.
Best-Fit Use Cases Across Four Research Contexts
The platform serves four distinct research contexts, each with different speed, scale, and ownership requirements. Enterprise consumer insights leaders at organizations like P&G and Skims use Listen Labs when they need to compress multi-week agency cycles into days while maintaining sample sizes in the hundreds. P&G used the platform to conduct 250+ interviews evaluating how men respond to new product claims, delivering quantified themes and verbatim proof in hours. Skims validated campaign direction with thousands of high-income buyers overnight, generating board-level confidence before a global launch.
UX research leads at companies like Anthropic use Listen Labs to close feedback loops within sprint cycles. Anthropic’s Claude Code team completed 300+ user interviews in 48 hours to surface churn drivers, identify where former users migrate, and produce a prioritized list of ten must-fix items, five times faster than their previous process.
Product and marketing leaders without dedicated research teams use the platform’s self-serve study design to describe research goals in natural language and receive structured findings without methodology expertise. Robinhood used Listen Labs to assess whether prediction markets feel on-brand and to identify user segments driving highest re-engagement, revealing that users who view the product as entertainment drive 2.4x higher weekly re-engagement.
Agencies and consultancies use Listen Labs to compress client research timelines from weeks to days, reaching niche audiences that traditional recruitment cannot fill within project windows.
Evaluate Listen Labs for your research program and map these use cases to your own organization.
Operational and Long-Term Considerations for Adoption
Understanding where the platform fits solves only half of the adoption challenge. Teams also need a clear view of the organizational and operational shifts required to implement it successfully. Adopting an AI-moderated platform requires stakeholder alignment on what constitutes acceptable research quality, particularly for organizations with established agency relationships. Change management is real, because research teams accustomed to human moderation need time to calibrate trust in AI-generated outputs. Listen Labs addresses this through an in-house research team with 50+ years of combined expertise that reviews and refines methodology continuously, and through fully traceable outputs that allow researchers to verify every finding independently.
For ongoing and global programs, the compounding advantages of a single platform become significant. Mission Control builds institutional knowledge across every study, enabling cross-study queries and trend tracking that fragmented vendor relationships cannot support. Participant reputation scoring improves with every study completed, so panel quality increases over time rather than degrading as commodity panels do.
Risks, Limitations, and Common Misconceptions
Several misconceptions distort the AI vs traditional market research evaluation. The first claims that AI interviews produce shallow, rigid data. Adaptive AI moderation with dynamic follow-up questions generates comparable depth to human moderation for the majority of research objectives. The second claims that traditional methods are inherently higher quality. Human fraud respondents frequently rely on simple heuristics such as over-agreement, producing well-documented biases including acquiescence bias and responses about fictitious products, and the fraud rates documented earlier affect traditional panels as severely as AI-moderated ones when fraud controls are absent.
The third misconception claims that faster tools produce better research. Speed functions as an operational advantage, not a quality guarantee. The quality of AI-moderated research depends on study design rigor, participant sourcing methodology, and the sophistication of fraud controls, not on the speed of delivery alone. The fourth claims that automation eliminates the need for research expertise. With AI-moderated interviews, talking to users at scale is no longer the hard part, and the challenge is understanding what they mean. Strategic interpretation remains a human responsibility.
Decision Framework for Choosing AI vs Traditional Methods
Research leaders can use the following criteria to match method to objective, with each criterion acting as a hard constraint that rules out traditional methods when present. When turnaround time is measured in days rather than weeks, AI-moderated platforms are the only viable option because traditional cycles cannot compress below four weeks without sacrificing quality. When sample size requirements exceed what a human moderation team can handle in a single study cycle, AI-moderated platforms become structurally necessary rather than simply faster. When multilingual reach across more than three markets is required simultaneously, AI-moderated platforms with built-in translation provide operational superiority. When emotional signal capture is required beyond self-reported ratings, platforms with multimodal Emotional Intelligence become essential. When governance and auditability are non-negotiable, platforms with traceable outputs and enterprise security certifications are required.
Traditional agency workflows remain appropriate for studies requiring highly specialized human moderator judgment, such as ethnographic immersion, sensitive clinical populations, or contexts where participant trust in a human interviewer functions as a research variable. For all other enterprise research objectives, and particularly for programs requiring both qualitative depth and quantitative scale simultaneously, the old trade-off between depth and scale is no longer a barrier. Listen Labs is the only end-to-end platform that eliminates it.
Frequently Asked Questions
How long does it actually take to get results from an AI-moderated study?
Listen Labs compresses the full research lifecycle of study design, participant recruitment, interview moderation, analysis, and deliverable generation to the same sub-24-hour window described earlier for most studies. Traditional qualitative cycles run four to six weeks, and enterprise approval processes can extend that to several months. This rapid timeline reflects the standard operating model for studies drawing from the 30 million verified respondent network.
How does Listen Labs source participants, and how is quality verified?
Listen Atlas, Listen Labs’ recruitment infrastructure, draws from a global network of 30 million verified respondents across 45+ countries and 100+ languages. An AI orchestration layer matches participants on behavioral and intent data rather than self-reported demographics. Quality Guard monitors every interview in real time across video, voice, content, and device signals. Participants are limited to three studies per month. A dedicated recruitment ops team adds human review for hard-to-reach segments below 1% incidence rate, including enterprise decision-makers, healthcare workers, and engineers.
Is AI moderation as rigorous as human moderation for complex research questions?
For the majority of enterprise research objectives, including concept testing, usability research, brand perception, churn analysis, creative testing, and segmentation, AI moderation with adaptive follow-up questions delivers comparable depth to human moderation. Listen Labs’ in-house research team, with 50+ years of combined expertise, continuously reviews and refines the methodology. The Emotional Intelligence layer adds a dimension of emotional signal capture that human moderation rarely quantifies systematically. For highly specialized contexts requiring human moderator judgment as a research variable itself, traditional methods remain appropriate.
What deliverables does Listen Labs produce, and how quickly?
The Research Agent generates automated key findings and theme analysis, consultant-quality PowerPoint slide decks, memo-style reports, video highlight reels, statistical charts and significance tests, segmentation breakdowns, and custom reports based on natural-language queries. Every deliverable links back to the underlying participant response, timestamp, and verbatim quote. One researcher completed a full buying intent analysis across three user segments in under a minute. Deliverables that previously required days of analyst time are generated in seconds.
How does Listen Labs handle data security and privacy compliance?
Listen Labs maintains SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. All data is encrypted at 256-bit. Customer data is never used for AI model training. Enterprise SSO is supported. The platform is designed to meet the compliance requirements of Fortune 500 enterprises operating across multiple jurisdictions, including regulated industries with strict data residency requirements.
Conclusion: Choosing a Research Stack Built for 2026
The AI vs traditional market research decision in 2026 is not a binary choice between speed and depth. The real question is whether the platform under evaluation can deliver both at once. Traditional agency workflows offer human judgment and established credibility at the cost of time, scale, and operational complexity. AI-moderated platforms offer speed and scale while risking shallow data, fraud exposure, and limited emotional insight unless they are built to address all three.
Listen Labs is the only end-to-end platform that sources participants, conducts adaptive AI-moderated interviews, captures emotional signals through Emotional Intelligence, and delivers auditable, consultant-quality outputs within the sub-24-hour cycle. Microsoft, Anthropic, P&G, Skims, and Robinhood have each validated that the quality holds at enterprise scale. See how Listen Labs can replace your current research stack with a single platform that delivers traditional qualitative depth at AI speed and scale.


