
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways
- AI-powered brand monitoring now tracks mentions, sentiment, and citations across social, web, and generative AI engines like ChatGPT and Perplexity.
- Traditional social-listening tools fall short because they rely on keyword matching and cannot reliably parse paragraph-length AI answers.
- Leading platforms must excel across six dimensions: research quality, speed, cost, scalability, governance, and data security.
- End-to-end AI research platforms that combine social listening, LLM citation tracking, and qualitative voice-of-customer data outperform siloed solutions.
- Book a demo with Listen Labs to unify your brand monitoring across traditional and AI channels and surface citation gaps your current stack is missing.
Why Traditional Tools Fall Short for AI Visibility
Conventional social listening platforms are built around keyword matching against short-form social posts and discrete web mentions. Specialized AI monitoring platforms parse complex, paragraph-length answers for brand mentions, a task that keyword-centric tools cannot perform reliably. Traditional tools return mention counts and engagement metrics, while AI citation monitoring measures visibility frequency, response accuracy, and positioning within blended narrative answers.
A McKinsey study found that 50% of consumers now intentionally seek out AI-powered search engines to guide their buying decisions and evaluate brands, and Pew Research Center data shows Google users are 46% less likely to click a traditional search result when an AI summary is present. Brand teams relying solely on legacy social listening are therefore blind to a growing share of the consumer decision journey.
These market shifts expose specific operational gaps when evaluated against the six-dimension framework. Research quality suffers because keyword sampling misses paragraph-level citations. Speed is constrained by manual prompt-checking workflows. Cost escalates when teams bolt on separate LLM-tracking tools. Scalability is limited by tools designed for social post volume rather than prompt-set breadth. Governance gaps emerge when AI-generated brand descriptions contain factual errors that go undetected. Data security risks increase when monitoring data flows through multiple disconnected vendors.
AI citation monitoring must also account for response variability based on user location, conversation history, and context. These inconsistencies sit outside the design assumptions of conventional social listening data collection.
Six Core Dimensions for Evaluating AI Monitoring Platforms
The six-dimension framework provides a structured way to evaluate any monitoring platform. Each dimension addresses a specific operational requirement for insights and brand teams.
Research quality requires platforms to track not just whether a brand appears in an AI answer, but whether the description is accurate, with correct features, pricing tier, and positioning. Meltwater research highlights that 90% of PR teams now integrate AI, which raises the bar for methodological rigor.
Speed reflects how quickly a platform surfaces sentiment spikes or citation drops. AI sentiment analysis tools now outperform earlier manual and keyword-based methods, which enables faster and more reliable alerting when brand narratives shift.
Cost and scalability work together as teams expand coverage. A strong platform runs large prompt sets across multiple engines without proportional cost increases. A practical measurement approach runs 100–200 prompts across ChatGPT, Gemini, Perplexity, Claude, and Google AI Overviews, tracking entity-based share of voice and citation-based visibility separately.
Governance requires platforms to flag when AI-generated answers misrepresent a brand and to trigger a documented remediation workflow. Example prompts to monitor include: “What do customers say about [brand] vs. competitors in 2026?” and “Which [category] brand is most recommended for [use case]?” Real-time alerts should fire on a 30% increase in negative sentiment above a 7-day baseline or a measurable drop in citation frequency.
Data security evaluation should confirm SOC 2 Type II, GDPR, ISO 27001, and ISO 27701 certifications at minimum. Teams should also secure explicit confirmation that monitoring data is not used to train third-party AI models.
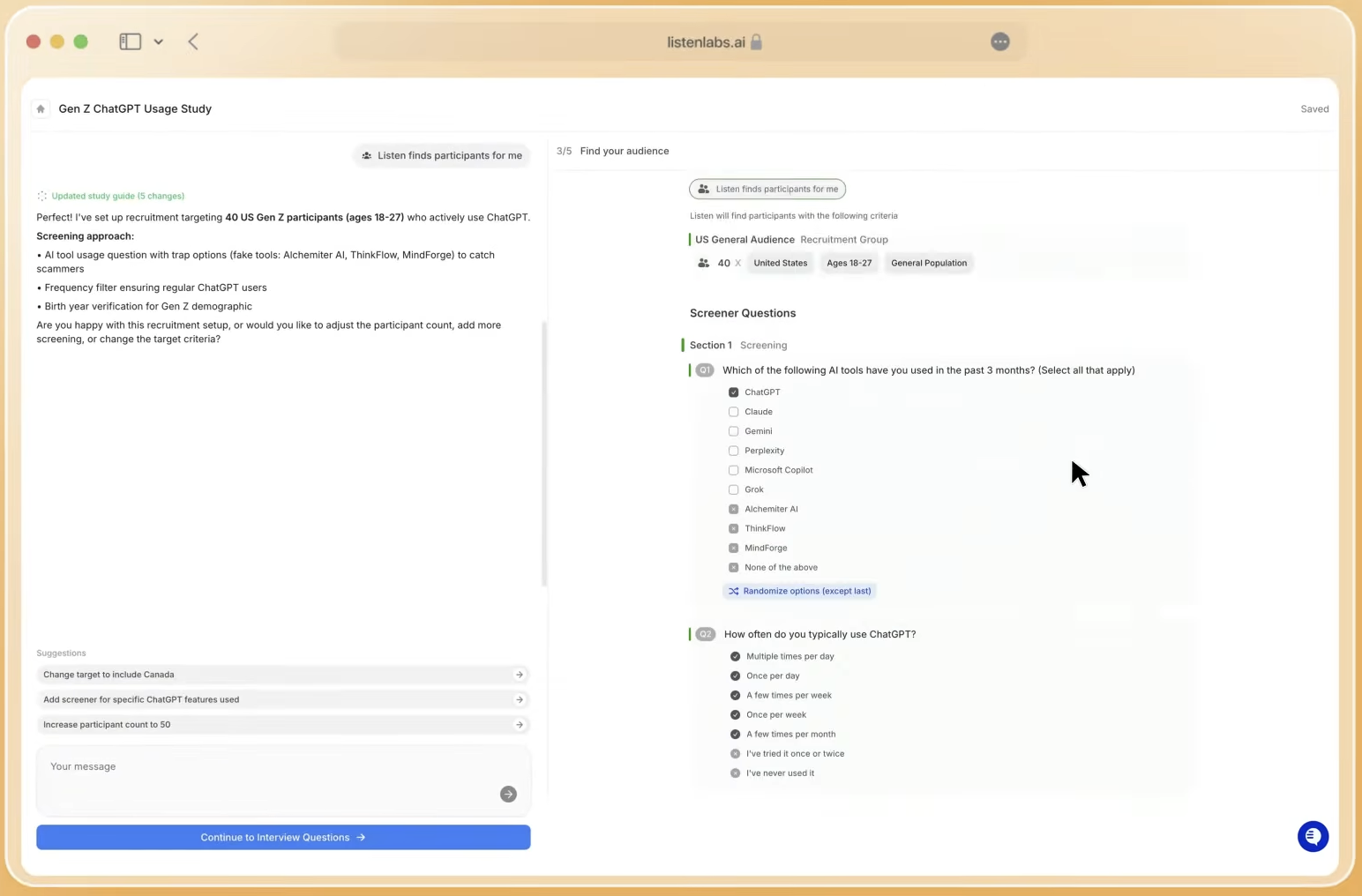
2026 Tool Landscape: Three Platform Categories
Three broad categories have emerged. Social-listening extensions add LLM-tracking modules to existing platforms. They score reasonably on speed and cost for teams already licensed, but research quality and scalability against AI-specific metrics remain limited because the core architecture was built for social post volume. Governance coverage is partial.
Dedicated LLM trackers such as Otterly.ai, Profound, and Peec AI are purpose-built to run prompt sets across generative engines. These tools should be configured to deliver change alerts so teams can move from monthly manual checks to continuous monitoring. They score well on AI-specific research quality and speed, but most do not integrate traditional social channels, which creates siloed data and governance gaps.
The third category addresses these integration limitations directly. End-to-end AI research platforms combine conventional channel monitoring with LLM visibility, participant-sourced voice-of-customer data, and automated analysis. This category scores highest across all six dimensions because it removes the handoff between social listening, AI citation tracking, and qualitative insight generation. Listen Labs has run over 1 million AI-powered customer interviews for companies including Microsoft, Perplexity, and Sweetgreen, positioning it as a leading platform in this category.
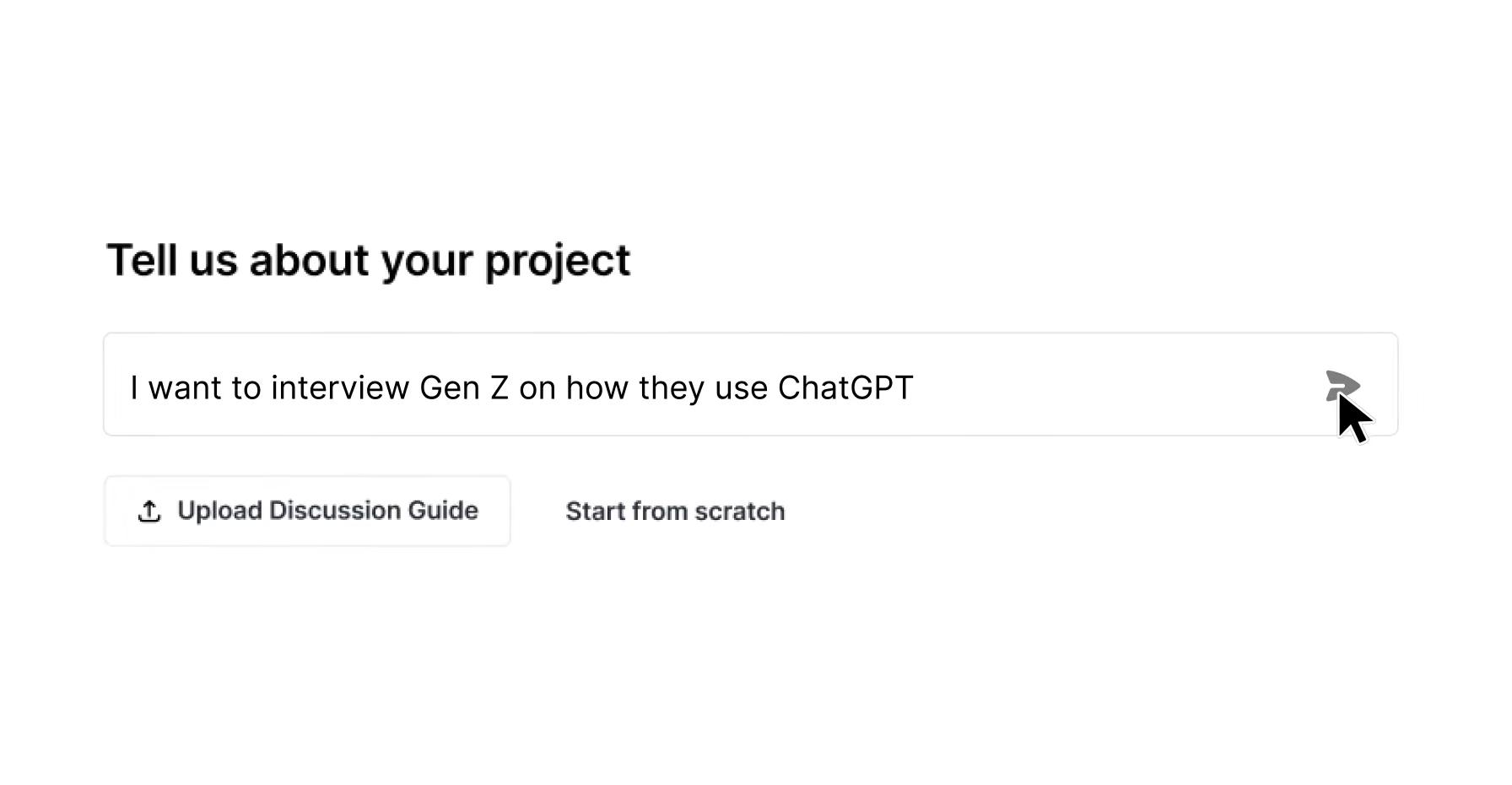
7-Step Implementation Checklist for Insights Teams
These seven steps translate the six-dimension evaluation framework into an operational rollout, from internal assessment through baseline measurement to full integration.
- Define the six-dimension scorecard. Assign internal weights to research quality, speed, cost, scalability, governance, and data security before evaluating any vendor.
- Establish a baseline Share of Model (SoM). Run 10–15 golden prompts weekly across AI platforms, balanced as 20% branded, 60% solution, and 20% comparison queries.
- Map citation sources. Identify the top 20 citation sources shaping AI answers about your brand and conduct a citation gap analysis.
- Audit traditional channel coverage. Confirm existing social listening tools cover forums, review platforms, and community discussions that AI engines use as consensus signals.
- Layer in qualitative voice-of-customer data. Use Listen Labs to source verified participants from its network and conduct AI-moderated interviews that surface emotional nuance through multimodal analysis.
- Configure real-time alerts. Set thresholds for sentiment spikes, citation drops, and AI summary inaccuracies, with assigned owners and documented remediation workflows for each alert type.
- Integrate monitoring data into the content calendar and review management program. Alerts are only valuable when they trigger action. Connect monitoring outputs directly to content planning and review response workflows so insights automatically drive remediation rather than remaining siloed in a dashboard.
90-Day Rollout Playbook for AI Brand Monitoring
Days 1–30: Audit. Inventory all current monitoring tools against the six-dimension framework. Run a baseline SoM measurement across ChatGPT, Gemini, and Perplexity. As of early 2026, 73% of B2B buyers use AI tools during their research process, so establishing a competitive benchmark becomes the critical first milestone. Identify citation gaps and governance risks, focusing on AI answers that misrepresent brand positioning. Deliverable: a six-dimension gap report with prioritized remediation items.
Days 31–60: Pilot. Deploy a dedicated LLM tracker or end-to-end platform on a single product line or market. Run parallel qualitative interviews through Listen Labs to validate whether AI-generated brand descriptions match actual customer language. AI can schedule and conduct interviews, analyze transcripts for themes, and generate quantitative insights from qualitative data, compressing a process that previously took 4–6 weeks into under 24 hours. Deliverable: pilot SoM delta, sentiment accuracy rate, and a validated prompt set for scale.
Days 61–90: Scale. Expand the prompt set to 100–200 queries across all target markets. Automate alert workflows and integrate monitoring outputs into quarterly brand health reporting. Consistent improvements in AI SOV typically appear within 60 to 90 days of a focused content and citation program. Deliverable: a continuous intelligence dashboard covering both traditional and LLM channels, with governance sign-off on data security certifications.
See how Listen Labs compresses the audit-to-insight cycle and surfaces AI citation gaps your current stack is missing, and schedule a platform walkthrough.
Common Pitfalls and Evidence-Based Mitigations
Over-reliance on automation degrades research quality when alert thresholds are misconfigured or prompt sets are too narrow. Mitigation: run 3–5 phrasing variations of each target prompt, because ChatGPT responses are highly sensitive to prompt phrasing. Assign a human reviewer to validate automated findings monthly.
Siloed data is the most common scalability failure. When AI citation data, social listening data, and qualitative interview data live in separate systems, governance breaks down and speed advantages disappear. Mitigation: select a platform that unifies all three data streams, or establish a documented integration protocol with assigned data owners. Listen Labs’ end-to-end platform supports this unified view.
Low-quality sampling undermines research quality at the foundation. Commodity panels filled with professional survey-takers produce incentive-driven answers that distort brand sentiment baselines. Listen Labs addresses this through Quality Guard, which uses its verified participant network with real-time checks and a participation frequency limit of three studies per month to reduce panel fatigue. Platforms like Listen Labs layer on auto-recruiting, transcription, sentiment tagging, and insight summarization so teams move from question to findings in hours, not weeks.
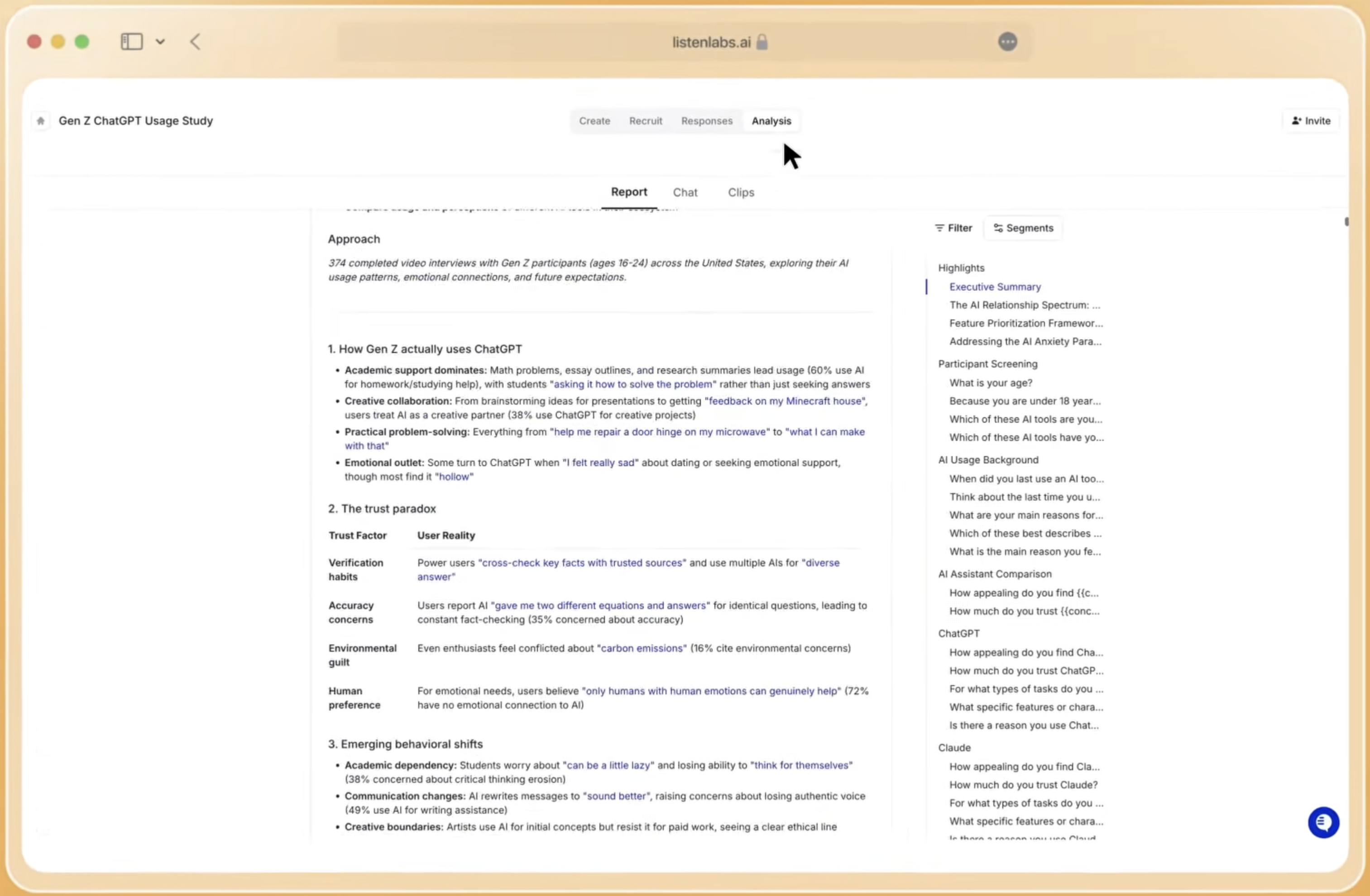
Ignoring citation source attribution creates a governance blind spot. Citation pathing traces the specific URLs an LLM used to construct a response that included a brand, identifying which publishers or review sites shaped the model’s knowledge. Without this, remediation efforts remain untargeted.
Listen Labs’ end-to-end platform eliminates siloed data and low-quality sampling across both traditional and AI monitoring channels. Request a demo to see the unified dashboard in action.
Frequently Asked Questions
How does prompt variability affect AI brand monitoring accuracy?
AI engines generate different responses to the same underlying question depending on phrasing, user location, and conversation history. This means a single prompt wording produces an unreliable snapshot. Best practice is to run multiple phrasing variations of each target prompt on a consistent weekly schedule and aggregate results across variations before drawing conclusions. Tracking relative momentum over time, rather than a single raw percentage, provides more useful insight than any one-time measurement.
What is the difference between citation tracking and mention tracking in AI outputs?
Mention tracking records whether a brand name appears anywhere in an AI-generated answer. Citation tracking goes further, identifying whether the brand’s content was used as a source URL that shaped the answer, which is often invisible to the end user. Both metrics matter: mentions reflect brand awareness within AI answers, while citations reflect content authority and the ability to influence what AI engines say. Tracking them separately reveals whether a brand has an awareness gap, an authority gap, or both.
What governance requirements should enterprises apply to AI brand monitoring programs?
Enterprise governance for AI brand monitoring should cover four areas. First, data security: confirm the monitoring platform holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications, and verify that monitoring data is not used to train third-party AI models. Second, accuracy auditing: establish a documented workflow for identifying and correcting AI-generated brand descriptions that contain factual errors. Third, alert ownership: assign named owners to each alert type with defined response timelines. Fourth, cross-functional integration: monitoring insights must feed directly into content, PR, and review management workflows rather than remaining in a standalone dashboard.
How does AI brand monitoring integrate with an existing social listening stack?
The most practical integration approach treats social listening and AI citation monitoring as complementary data streams feeding a single brand health report. Social listening covers conversation volume, sentiment trends, and community discussions on traditional channels. AI citation monitoring adds Share of Model, citation source mapping, and AI summary accuracy. Where possible, select a platform that unifies both streams natively. Where integration is required across separate tools, establish a shared data schema that captures platform, mention status, sentiment, competitors mentioned, and cited sources so both data types can be analyzed together and trigger unified workflow actions.
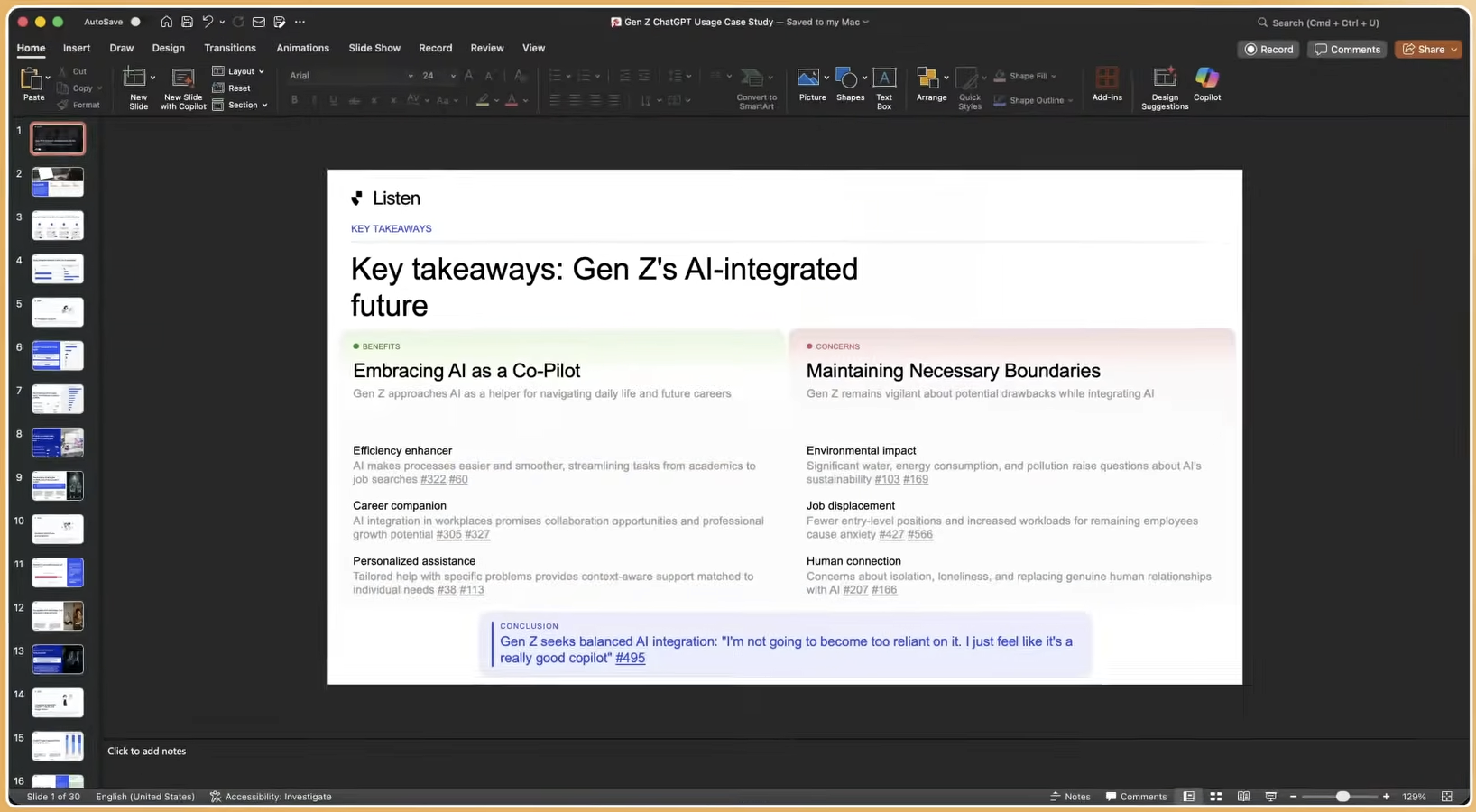
Conclusion: Turning AI Visibility into Actionable Insight
In 2026, brand reputation is increasingly shaped not by what people search for, but by what AI answers. The six-dimension framework of research quality, speed, cost, scalability, governance, and data security provides a neutral basis for evaluating any monitoring solution against that reality.
The recommended next steps are an internal audit against the six dimensions, a 30-day pilot covering both traditional and LLM channels, and a vendor comparison that includes end-to-end AI research platforms alongside social-listening extensions and dedicated LLM trackers. Qual-at-scale is ideal when research requires large sample sizes or broad geographic reach, with AI tools engaging hundreds or thousands of participants remotely and asynchronously, which makes it the right infrastructure for continuous brand intelligence programs, not one-off studies.
Listen Labs compresses the full research cycle, from study design and participant recruitment to AI-moderated interviews, multimodal emotional analysis, and consultant-quality deliverables, into under 24 hours, leveraging the interview infrastructure described earlier. Alfred Wahlforss, CEO of Listen Labs, states: “Companies use it for all kinds of large decisions. This AI interviewer means that you can have hundreds of one-on-one interviews run at scale.”
Book a demo to see how Listen Labs delivers real-time customer voice across traditional channels and generative AI engines and turns that visibility into action in under 24 hours.


