
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways for Enterprise Research Leaders
- ML market research software removes the traditional tradeoff between quantitative scale and qualitative depth by running adaptive, LLM-powered interviews at survey-like volumes.
- Enterprise platforms should be evaluated across eight dimensions, including research speed, sample quality, global reach, emotional intelligence, and security compliance.
- Listen Labs stands out through its 30M+ verified panel, real-time Quality Guard monitoring, and AI-moderated interviews in 100+ languages with full emotional-signal analysis.
- Automated analysis via the Research Agent replaces weeks of manual coding while producing auditable, bias-reduced insights and branded deliverables in under a minute.
- Listen Labs delivers end-to-end enterprise research, from study design to final report, in under 24 hours; see the 24-hour workflow in action for your team.
Eight Dimensions for Evaluating ML Research Platforms
Enterprise teams evaluating ML research platforms should assess eight connected dimensions before committing to a vendor. Research speed measures the elapsed time from study brief to final deliverable, which directly affects how many projects a fixed team can complete each quarter. That speed only matters when the insights are substantive, so insight depth captures whether the platform produces adaptive, probing conversations or static question sets. Speed and depth both depend on trustworthy inputs, which makes sample quality and fraud prevention foundational for any verified and actively monitored participant pool.
Global reach then determines how broadly those high-quality participants can be accessed across countries, languages, and audience segments without relying on third-party recruitment vendors. Methodological flexibility covers whether the platform supports IDIs, usability testing, concept testing, diary studies, and mixed-method designs within a single environment. Analysis automation evaluates how much manual coding, tagging, and synthesis the platform removes from the workflow, which shapes both turnaround time and consistency.
Emotional intelligence capability distinguishes platforms that capture only transcript data from those that also analyze tone, micro-expressions, and subconscious signals. Finally, security and compliance, including GDPR, SOC 2, and ISO certifications, combine with total cost of ownership, including the number of vendors replaced, to determine long-term enterprise fit. The following sections examine each dimension in detail, starting with how different platform types handle study design and setup as the first point where research speed and methodological flexibility diverge.
Study Design and Setup Across Traditional, Survey, and ML Tools
Traditional qualitative research relies on a specialist who manually drafts a discussion guide, submits it for internal review, iterates across stakeholders, and then hands it to a separate moderation team. This process alone can consume one to two weeks before a single interview occurs. Survey platforms like Qualtrics and SurveyMonkey accelerate setup but constrain design to pre-set question formats with no adaptive follow-up capability, which produces structured data that often misses the reasoning behind responses.
ML platforms replace this manual process with AI-assisted co-design. On Listen Labs, a researcher describes objectives in natural language and the platform drafts structured goals, interview questions, and probing context in seconds. Advanced stimuli support for images, video, audio, PDFs, live URLs, and prototypes, combined with branching logic, skip logic, quotas, and monadic randomization, allows one platform to handle concept testing, usability studies, and brand perception research without switching tools. Auto-QA flags issues in the guide before launch, and teams can clone and adapt past studies, which compounds institutional knowledge over time.
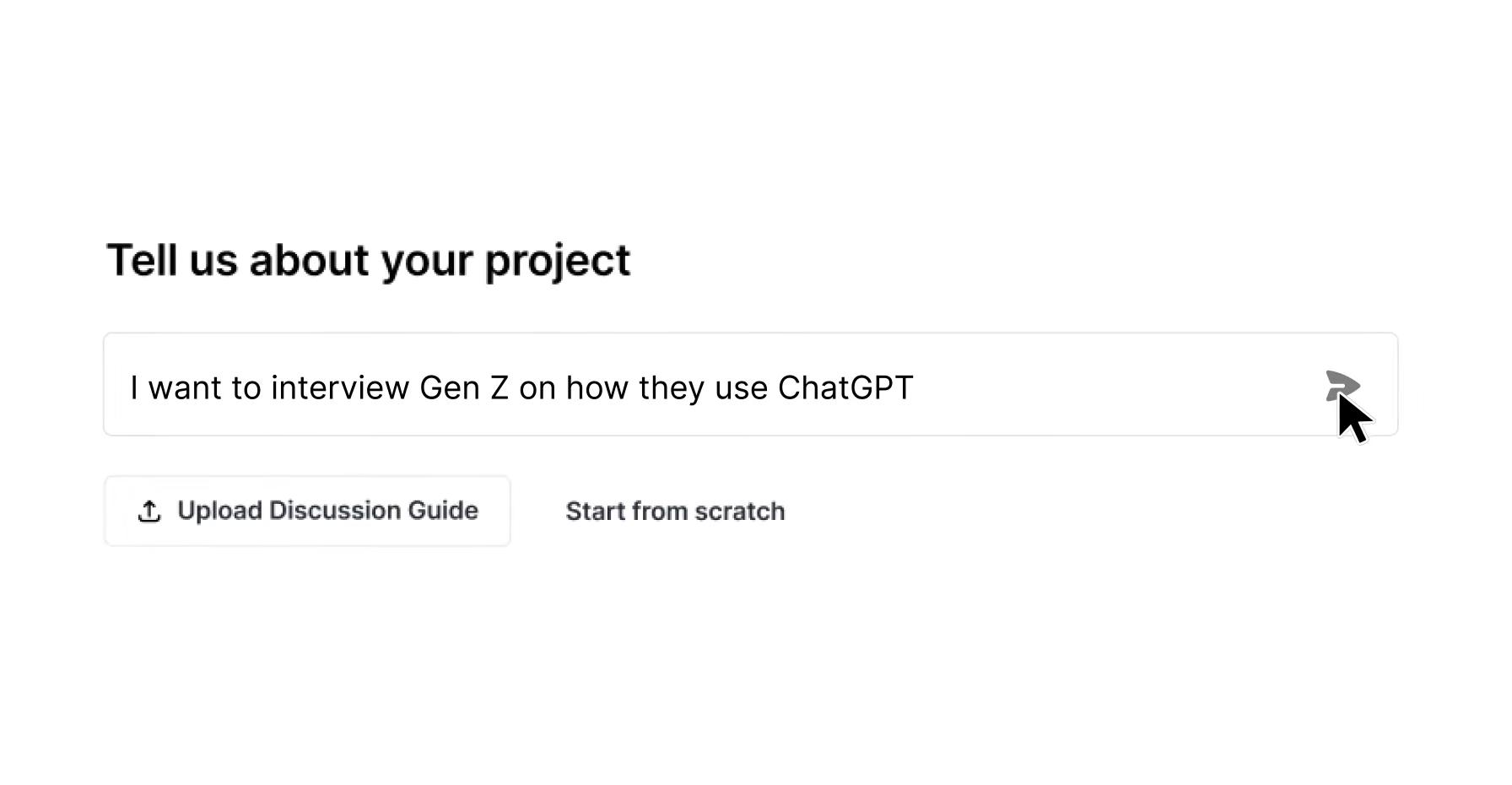
Participant Sourcing and Quality Controls Across Platforms
Commodity panel providers introduce well-documented risks such as professional survey-takers optimizing for incentives, bot-generated responses, and repeat respondents who distort findings. Several platforms apply AI-driven quality layers, including Qualtrics AI capabilities that support data quality by automatically identifying unmotivated respondents, fraud, and bots, and Attest checks that automatically filter out low-quality or biased survey responses. These controls, however, operate on top of commodity panels rather than replacing them.
Listen Labs takes a structurally different approach. Listen Atlas, its AI orchestration layer, matches and bids across multiple high-quality consumer and B2B panel partners alongside Listen Labs’ proprietary database of 30M verified respondents across 45+ countries and 100+ languages. Quality Guard monitors every interview in real time across video, voice, content, and device signals to detect fraud, low-effort responses, AI-generated scripts, and mismatched profiles. Participants are capped at three studies per month, which removes professional survey-takers by design. A dedicated recruitment operations team adds a human review layer for hard-to-reach segments such as enterprise decision-makers, healthcare workers, and audiences below 1% incidence rate that automated matching alone cannot reliably source.
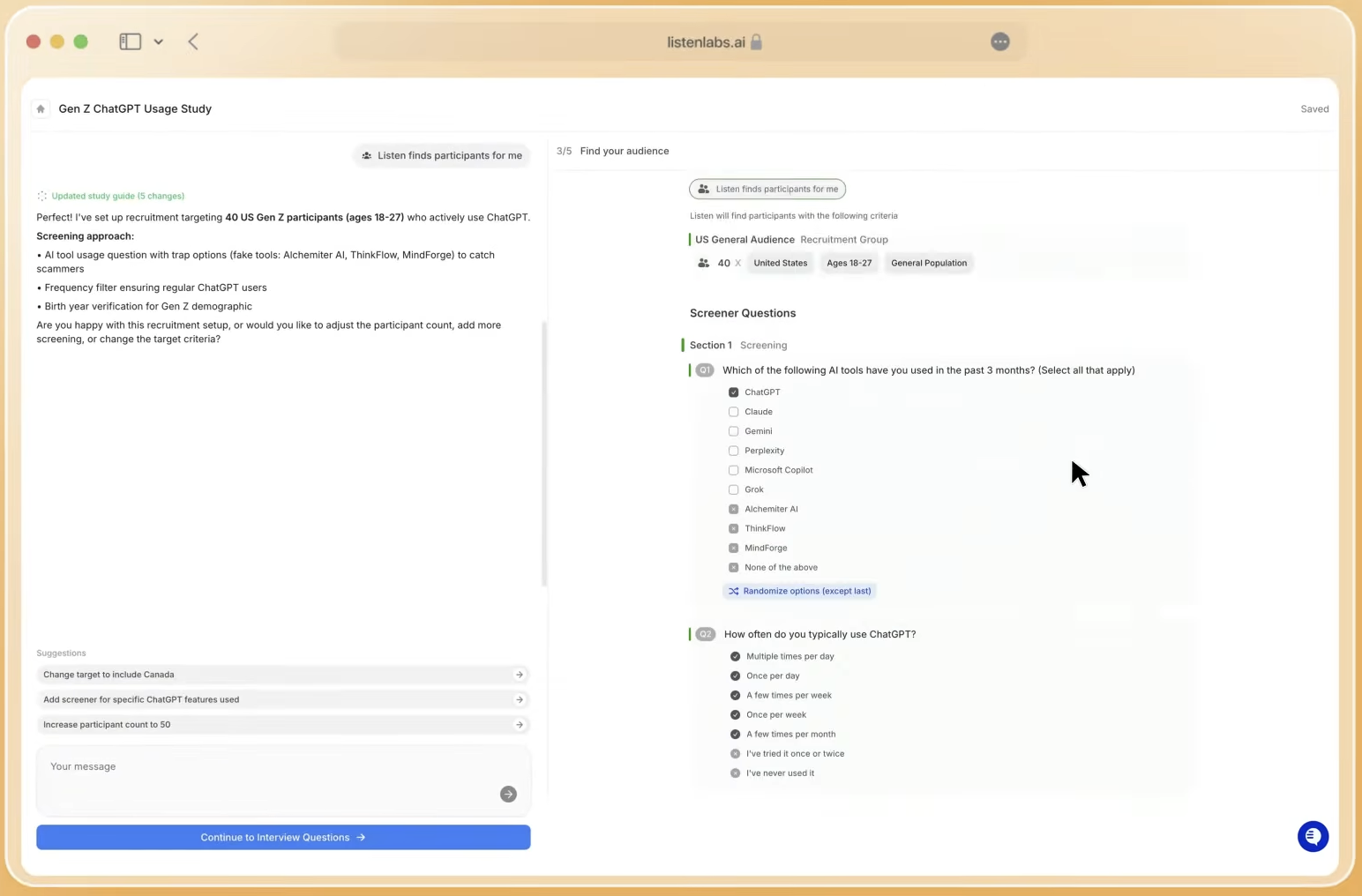
Moderation: Adaptive AI Interviews Versus Surveys and Human-Led Sessions
Static surveys ask every participant the same questions in the same order, which makes it structurally impossible to probe an unexpected answer or follow a thread the study designer did not anticipate. Human-led moderation solves this problem but introduces scheduling overhead, no-show risk, interviewer inconsistency, and a hard ceiling on how many sessions can run simultaneously.
Because LLM-based conversations are adaptive, conversational AI is positioned as stronger than static survey formats for probing follow-up questions and uncovering deeper context and emotional nuance. Listen Labs conducts AI-led video interviews that ask dynamic follow-up questions based on each participant’s specific responses, mirroring the behavior of a trained human interviewer while running in parallel across hundreds of sessions. AI-moderated interviews can also outperform human interviewers on sensitive topics because participants report less fear of judgment, engage in less impression management, and disclose more openly. The platform supports 100+ languages for moderation, with automatic translation and transcription, which enables global studies without separate localization vendors.
Data Capture and Emotional Intelligence in ML Research
Most research platforms, including transcript repositories, survey tools, and basic AI interview products, capture only what participants say. This creates a systematic blind spot because tone of voice, word choice, and subconscious micro expressions carry emotional signals that transcripts alone miss.
Listen Labs’ Emotional Intelligence feature analyzes all three signal layers simultaneously. It is built on Ekman’s universal six emotions framework, the same standard used in clinical psychology and UX research, tracking anger, disgust, fear, happiness, sadness, surprise, and neutral states. Every emotion is quantified per question and concept, with each label traceable to the exact timestamp, verbatim quote, and AI reasoning behind it. This traceability separates it from black-box sentiment tools that return a score without explaining why. Use cases span creative testing, concept comparison, usability testing, and brand research, and the feature works across 50+ languages while integrating directly with the Research Agent for natural-language queries and highlight reel generation.
Analysis Workflow, Bias Reduction, and Deliverables
Human analysis of qualitative data is slow, subjective, and prone to confirmation bias. Analysts working through hundreds of interview transcripts manually may unconsciously weight findings that confirm pre-existing hypotheses. This process typically adds one to two weeks to a research cycle after fieldwork closes.
Listen Labs’ Research Agent handles the full analysis workflow from raw data to final output. It identifies patterns, themes, and personas across all interview responses objectively, informed by proprietary data from tens of thousands of studies conducted on the platform. Every insight links directly to the underlying response data, which makes findings auditable rather than asserted. One researcher ran a full buying intent analysis across three user segments in under a minute. The Research Agent generates a slide deck in a company’s branded template and a downloadable report, alongside memos, video highlight reels, statistical charts, and segmentation breakdowns, all in under a minute.
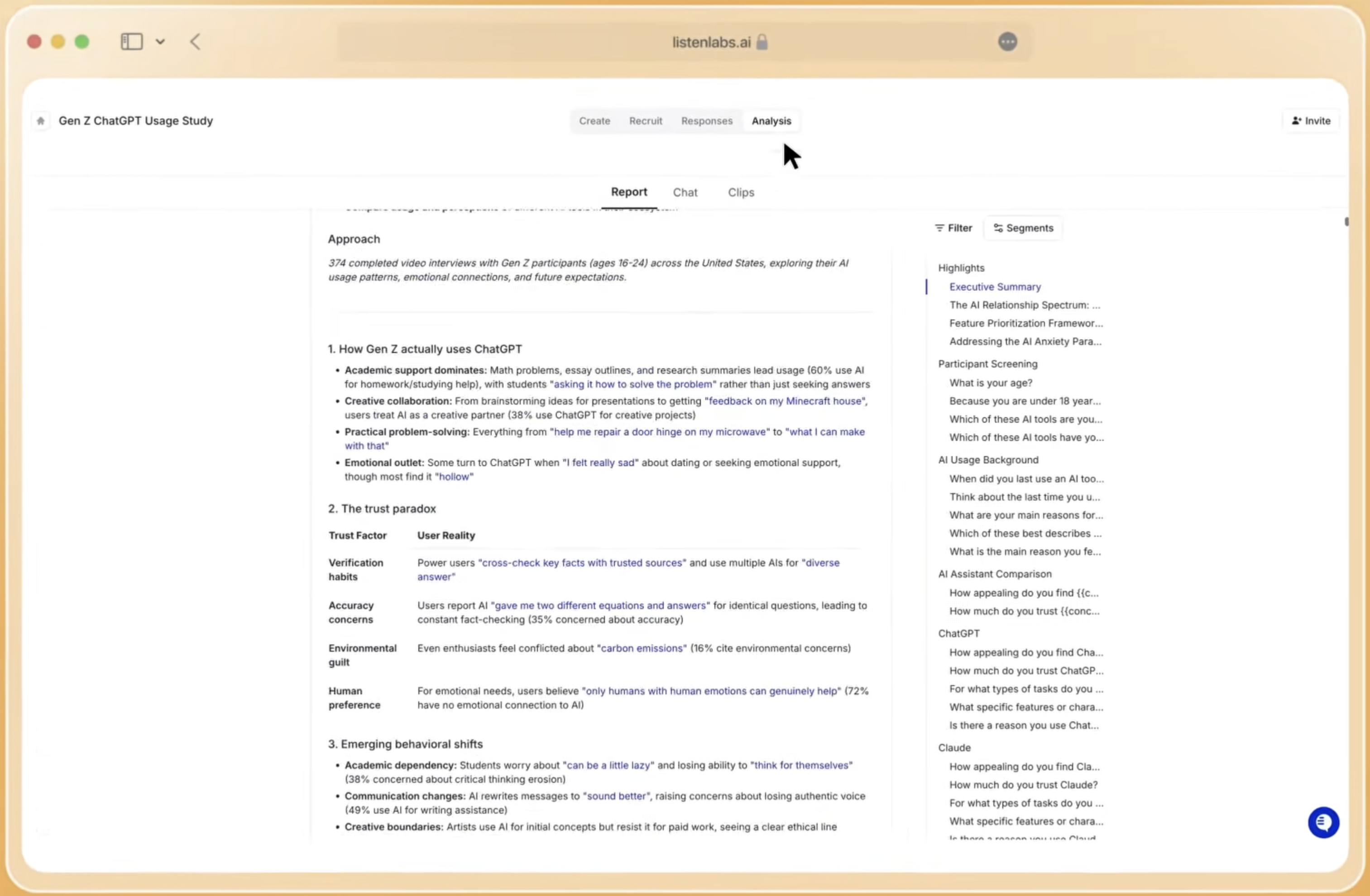
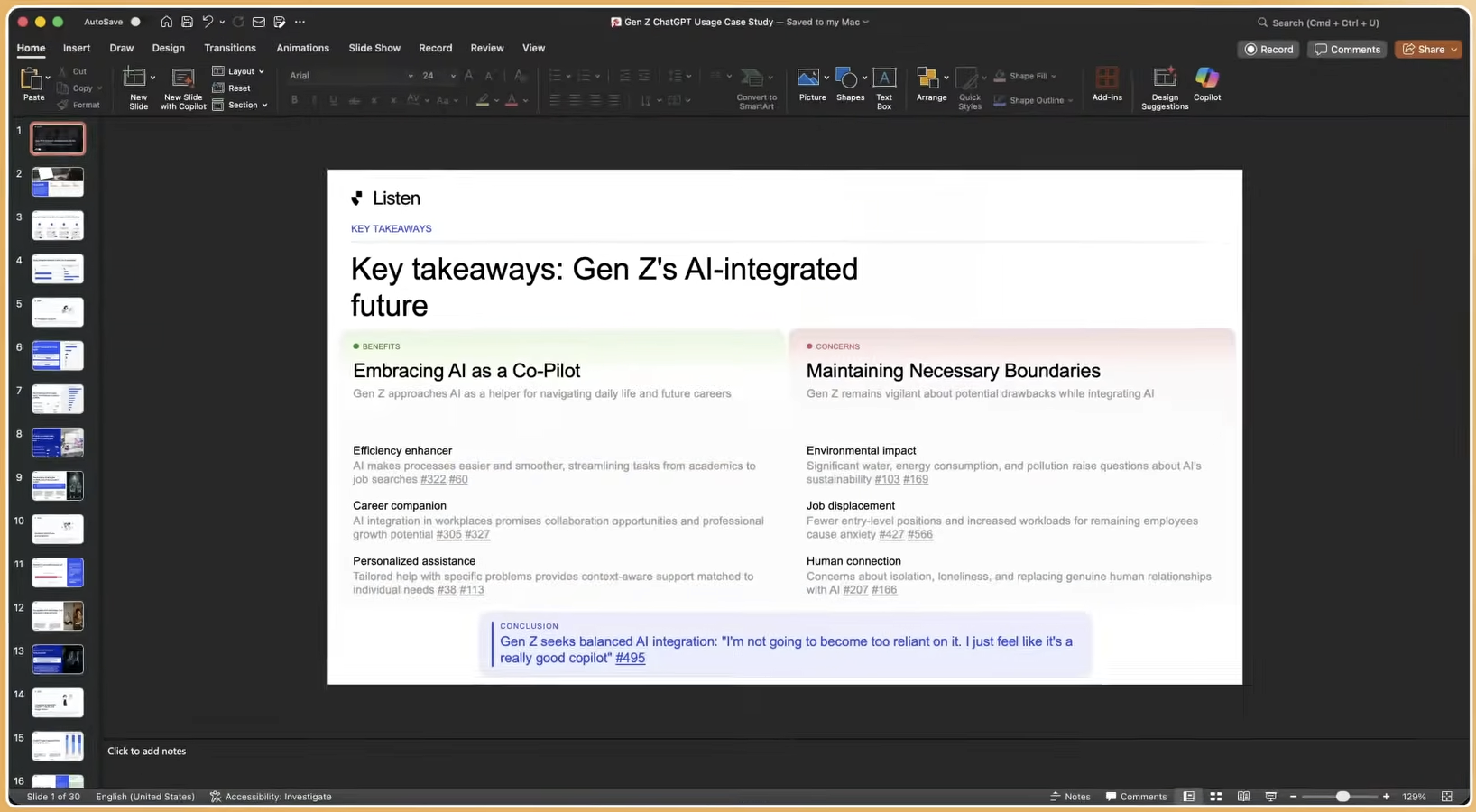
Scenario-Based Fits for Insights, UX, Product, and Agencies
Consumer insights leaders at large enterprises face growing research backlogs with fixed headcount. A unified ML platform allows the same team to run significantly more studies per quarter without proportional cost increases. Listen Labs has run over 1 million AI-powered customer interviews for companies including Microsoft, Perplexity, and Sweetgreen, which demonstrates enterprise-scale reliability. Microsoft used Listen Labs to conduct 250-plus interviews across three audiences in its Frontier Listening program, combining open-ended qualitative depth with quantifiable metrics and surfacing customer nuance in days rather than weeks.
UX research leads need faster feedback loops to keep pace with sprint cycles. Listen Labs supports screen sharing, mobile screen recording on iOS, and task-based usability testing, which enables teams to test with 50–100+ users instead of the 5–10 typical of human-moderated sessions. Product managers and marketing leaders without dedicated research teams benefit from the self-serve study design flow, describing goals in natural language and receiving a complete study guide, recruited participants, moderated interviews, and analysis without requiring methodology expertise. Agencies and consultancies with client timelines measured in days rather than weeks gain access to niche audience recruitment and global reach across 45+ countries without building their own panel infrastructure.
Operational Rollout, Security, and Compliance
Adopting an end-to-end ML platform requires change management across research, product, and marketing teams that are accustomed to fragmented vendor relationships. The transition consolidates recruitment, moderation, transcription, analysis, and reporting into a single workflow, which reduces handoff delays and vendor coordination overhead. Teams without prior research methodology experience can operate the platform through AI-assisted study design, while experienced researchers retain full control over study structure, stimuli, and analysis parameters.
For enterprise procurement, Listen Labs holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. Customer data is never used for AI model training, and the platform uses 256-bit encryption. Enterprise SSO is supported. These certifications satisfy the compliance requirements of Fortune 500 procurement processes across regulated industries including financial services, healthcare, and consumer goods.
Risks and Limitations of ML Research Platforms
ML research platforms carry real risks that enterprise teams should evaluate before deployment. Shallow data risk emerges when AI interview guides are poorly constructed, because the platform amplifies the quality of the inputs, so vague objectives produce vague findings. Over-reliance on automation can cause teams to accept AI-generated themes without interrogating the underlying verbatims, especially when deliverables are generated at speed. Hidden recruitment complexity affects platforms that rely on commodity panels without dedicated quality controls, as fraud and professional survey-takers remain a persistent problem across the industry, and AI-agent detection models trained to distinguish human respondents from bots and synthetic actors now represent a baseline requirement rather than a differentiator.
Platforms without verified panels and real-time quality monitoring, even those with strong analysis capabilities, expose enterprise teams to data integrity failures that can invalidate entire studies. The depth-versus-automation tradeoff also persists for highly specialized research contexts, such as expert interviews with C-suite executives or clinical populations, where human moderation may still be warranted alongside AI-led sessions.
Decision Framework and Practical Checklist
Teams selecting machine learning market research software should work through several criteria before committing to a platform. When the research cycle currently exceeds two weeks and the team runs fewer studies than stakeholders request, an end-to-end ML platform fits the problem space. If participant quality is a recurring concern, evidenced by low-effort responses, repeat respondents, or fraud flags, the platform must include real-time quality monitoring and frequency limits, not just post-hoc filtering. This requirement becomes even more critical when the research scope spans multiple countries or languages, because fraud patterns vary by market and third-party panel add-ons rarely apply consistent quality controls across geographies. Verify that the platform’s panel and moderation capabilities cover the required markets natively.
When emotional nuance is material to the research objective, such as creative testing, brand perception, or usability friction, confirm that the platform captures multimodal signals beyond transcripts. If the team needs to justify replacing multiple vendors to procurement, calculate total cost of ownership across recruitment, moderation, transcription, analysis, and reporting tools currently in use. When the organization requires enterprise security certifications, confirm SOC 2, GDPR, and ISO compliance before piloting. For teams that want to build institutional knowledge across studies rather than treating each project as a one-off, evaluate whether the platform includes a cross-study repository with natural-language query capability.
Listen Labs satisfies these criteria as a single platform. Walk through how it maps to your workflow in a personalized demo.
Frequently Asked Questions
How quickly can machine learning market research software deliver results compared to traditional cycles?
Traditional qualitative research cycles often run 4–6 weeks from study design to final report, and in large enterprises with internal prioritization backlogs, the timeline can extend to six months. Machine learning platforms compress this by automating every stage of the lifecycle in parallel instead of as sequential handoffs. As noted in the scenario analysis above, Listen Labs compresses the traditional 4–6 week cycle to under 24 hours by running AI-assisted study design, recruitment, AI-moderated interviews, automated analysis, and deliverable generation as a continuous workflow.
What participant quality and fraud prevention features should teams evaluate?
Teams should evaluate four specific capabilities: whether the platform uses verified, non-commodity panels; whether quality monitoring operates in real time during interviews rather than post-hoc; whether participant frequency limits prevent professional survey-takers from contaminating samples; and whether a human review layer exists for hard-to-reach or low-incidence audiences. Listen Labs implements all four through its Quality Guard system, detailed in the participant sourcing section above, which monitors interviews in real time rather than filtering only at the sampling stage. Platforms that apply quality filters only at the sampling stage, without monitoring during the interview itself, remain vulnerable to low-effort and AI-generated responses that pass initial screening.
How does emotional intelligence analysis differ from basic sentiment tools?
Basic sentiment tools classify text as positive, negative, or neutral based on word choice alone. They produce a score without explaining the reasoning, cannot detect discrepancies between what a participant says and how they say it, and miss the nonverbal signals that carry significant emotional information. Unlike basic sentiment tools that score text without context, Listen Labs analyzes tone, word choice, and micro expressions simultaneously using a clinical psychology framework. This matters most when verbal and nonverbal signals conflict, such as when a participant verbally approves of an ad while displaying micro-expressions of confusion, or when usability testing reveals hesitation and frustration that participants do not explicitly report.
What pricing and self-recruitment options exist for enterprise ML platforms?
Listen Labs uses a subscription model in which enterprises pay for platform access covering a set number of studies and credits, then spend credits per participant recruited. Credit cost varies by audience difficulty, so general population studies require fewer credits than niche or low-incidence segments. Organizations can also self-recruit from their own user base at a reduced credit cost, which makes it practical to run continuous research programs against existing customers without incurring full panel fees for every study. Companies with more than 100 employees go through a demo and pilot process, while smaller teams can access the self-serve platform directly. The total cost of ownership is typically a third of the cost of the equivalent traditional research approach when accounting for the elimination of separate recruitment, moderation, transcription, analysis, and reporting vendors.
Which security certifications are standard for compliant research software?
Enterprise procurement teams should require SOC 2 Type II as a baseline, confirming that the platform’s security controls have been independently audited over a sustained period rather than at a single point in time. GDPR compliance is mandatory for any research involving participants in the European Union. ISO 27001 covers information security management, ISO 27701 extends this to privacy information management, and ISO 42001 addresses AI management systems specifically, a certification that has become increasingly relevant as enterprise legal and compliance teams scrutinize AI-generated research outputs. Listen Labs holds all five certifications and supports enterprise SSO. Customer data is never used for AI model training, and all data is protected with 256-bit encryption.
Conclusion: Selecting the Right ML Market Research Platform
The comparison across study design, participant sourcing, moderation, emotional intelligence, analysis automation, and compliance consistently distinguishes end-to-end ML platforms from fragmented tool stacks and survey-only solutions. Fragmented approaches force teams to manage handoffs across recruitment vendors, moderation tools, transcription services, and analysis platforms, with each step introducing delay, cost, and quality risk. Survey platforms scale but cannot probe, follow up, or capture the emotional signals that explain behavior. Human-dependent moderation delivers depth but cannot run at the speed or volume that modern product and marketing cycles require.
Listen Labs resolves these constraints in a single platform. Backed by $69 million in Series B funding led by Ribbit Capital at a valuation of $460 million, Listen Labs is trusted by Microsoft, Sweetgreen, Perplexity, and Robinhood. It is built to multiply research team output without proportional increases in headcount or budget. With qual-at-scale, the old trade-off between depth and scale no longer blocks decision-making.
See how to compress your research cycle from weeks to hours in a live demo.


