
Written by: Anish Rao, Head of Growth, Listen Labs | Last updated: July 26, 2026
Key Takeaways
- Automated customer-insight workflows compress traditional 4–8 week qualitative cycles into under 24 hours by connecting design, recruitment, AI-moderated interviewing, analysis, and activation into a single pipeline.
- Four readiness conditions, including team oversight, data governance, scalable sample planning, and updated budget baselines, must be in place before launching automated studies.
- The four-stage framework (Design, Recruit & Moderate, Analyze, Activate) uses AI co-design tools, real-time quality monitoring, emotional-signal analysis, and instant report generation to deliver stakeholder-ready outputs in minutes.
- Real-world deployments, such as global CPG concept tests and Microsoft’s 50th-anniversary user-story collection, show that 200–250 simultaneous AI-moderated interviews with emotional intelligence can be completed and synthesized within a single day.
- Listen Labs operationalizes the entire workflow on one compliant platform; see how your team can replace slow research cycles with 24-hour results.
Readiness Requirements Before You Automate Research
Four readiness conditions create the foundation for a reliable automated insight workflow.
- Team readiness. At least one researcher or insights lead must own study design and final interpretation. This ownership is operationalized through a human-in-the-loop oversight model, where AI suggests themes and researchers validate them, which is the gold standard for maintaining accuracy in automated qualitative analysis.
- Data governance. Confirm that your platform of choice holds the certifications your legal team requires. Listen Labs maintains SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 compliance, and customer data is never used for AI model training.
- Sample-size planning. Traditional qualitative studies typically involve small sample sizes of 5–15 participants. Automated platforms remove this ceiling. A 200-interview study is operationally equivalent to a 20-interview study in terms of researcher effort while delivering far greater statistical confidence.
- Budget baseline. A traditional agency charged $147,000 for a 20-interview study, while an equivalent 200-interview study on an AI-moderated platform costs under $10,000. Plan budgets accordingly and retire legacy line items for moderator fees, transcription, and manual analysis.
With these four readiness conditions in place, you can configure a four-stage automated workflow that compresses traditional research cycles from weeks to hours.
Four-Stage Automated Insight Workflow
Stage 1 – Design Your Study in Under 90 Minutes
Inputs: A plain-language research brief stating the business decision, target audience, and success criteria. Include stimuli such as images, video, PDFs, or live URLs when concept testing.
Decision points: Choose study type (IDI, diary, usability, concept test), question structure (open-ended, Likert, MaxDiff), branching logic, and quota definitions by segment or market.
Typical timeline: 30–90 minutes. Listen Labs’ AI co-design tool drafts structured objectives, questions, and probing context from a natural-language brief, then auto-QA flags issues before launch.
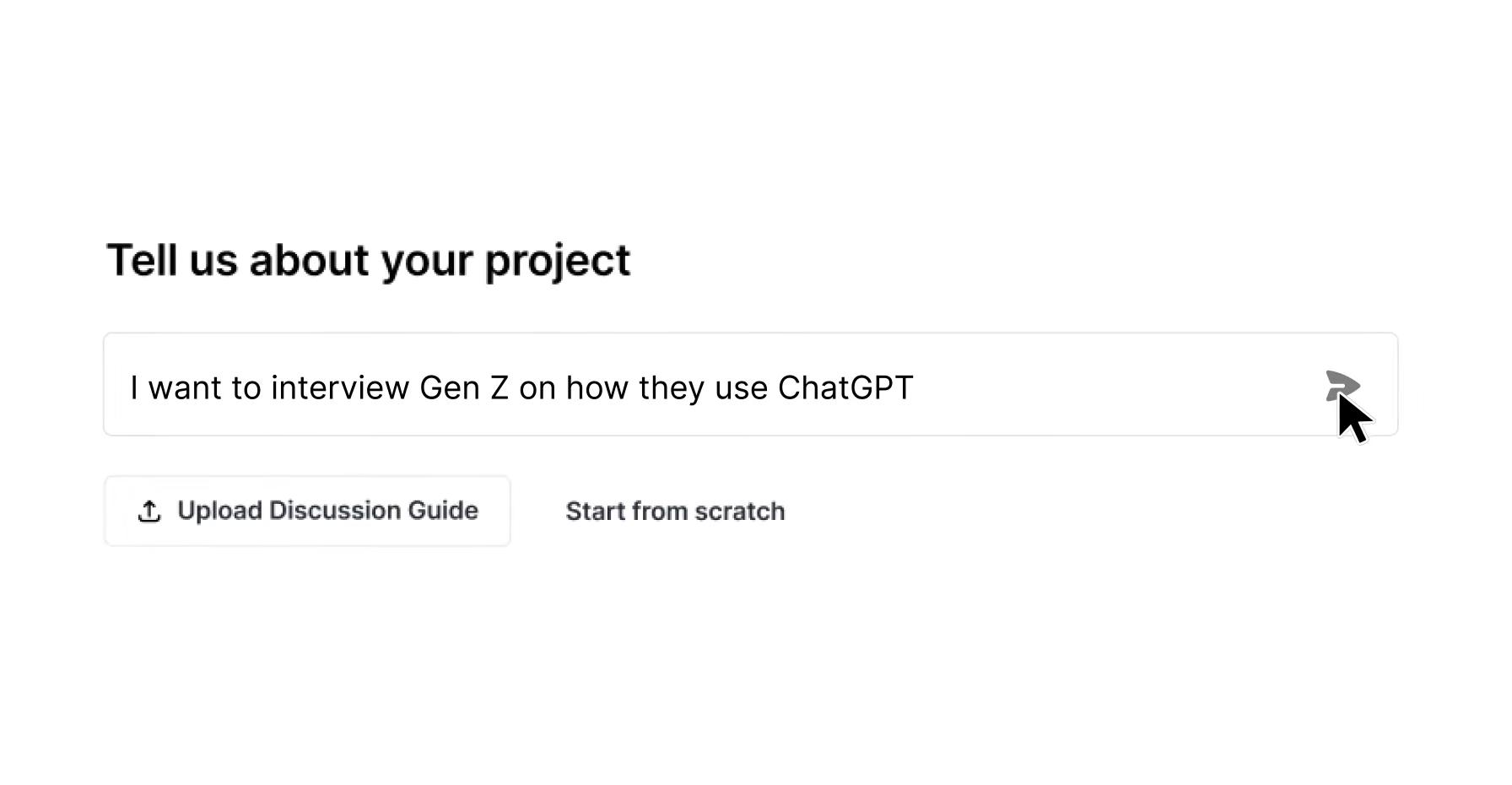
Cost drivers: Internal researcher time, though AI-moderated research can substantially reduce the time researchers spend per study compared with traditional methods, which makes this stage’s cost relatively small.
Stage 2 – Recruit and Moderate at Scale
Inputs: Finalized screener criteria, quota targets by segment, incentive structure, and estimated interview length.
Decision points: Select panel source (platform network vs. bring-your-own participants), incidence rate, geographic spread, and language requirements. For audiences below 1% incidence, such as enterprise decision-makers or healthcare workers, a dedicated recruitment operations team adds a human sourcing layer.
Typical timeline: Recruitment completes quickly via automated panel deployment, which enables many simultaneous AI-moderated conversations. Participant fraud is a documented risk in online research. Listen Labs addresses this through Quality Guard, which applies real-time AI monitoring across video, voice, content, and device signals, limits participants to three studies per month, and excludes commodity panel sources entirely.
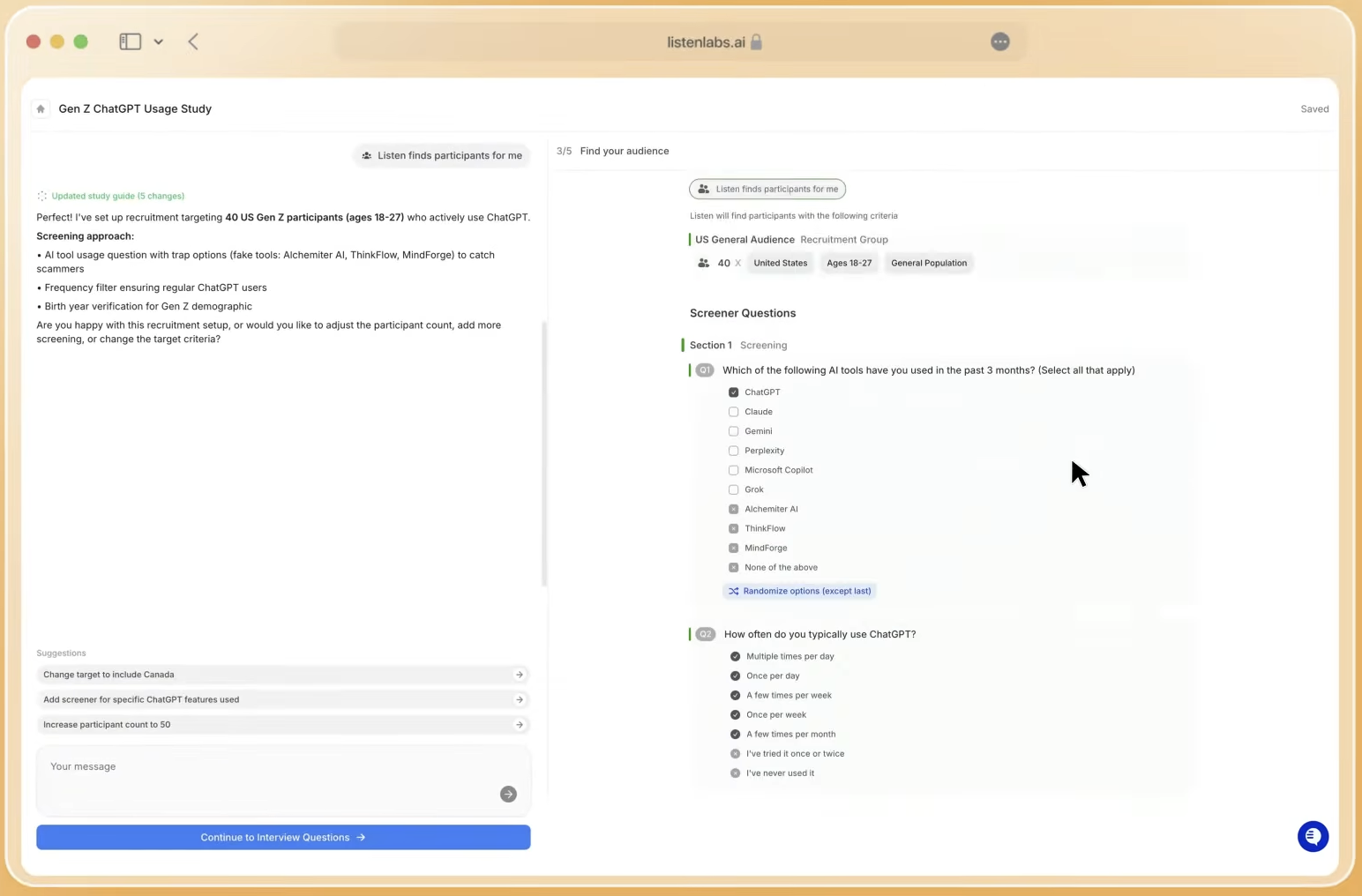
Cost drivers: Audience incidence rate and geographic complexity. General-population studies cost fewer credits than niche segments. AI-moderated interviews for multi-market qualitative work can be completed more quickly and at significantly lower cost than traditional IDI studies.
Ready to compress your recruitment and moderation timeline from weeks to hours? See the recruitment and moderation workflow in action.
Once recruitment completes and all interviews are recorded, the workflow moves immediately into automated analysis, where AI processes hundreds of hours of video in minutes.
Stage 3 – Analyze Interviews in Minutes
Inputs: Completed interview recordings, transcripts, and quantitative response data from the moderation stage.
Decision points: Decide which segments to compare, which stimuli to evaluate side-by-side, and whether emotional-signal analysis is required in addition to thematic coding.
Typical timeline: Automated theme identification and reporting both complete in minutes. One researcher ran a full buying-intent analysis across three user segments in under a minute using Listen Labs’ Research Agent.
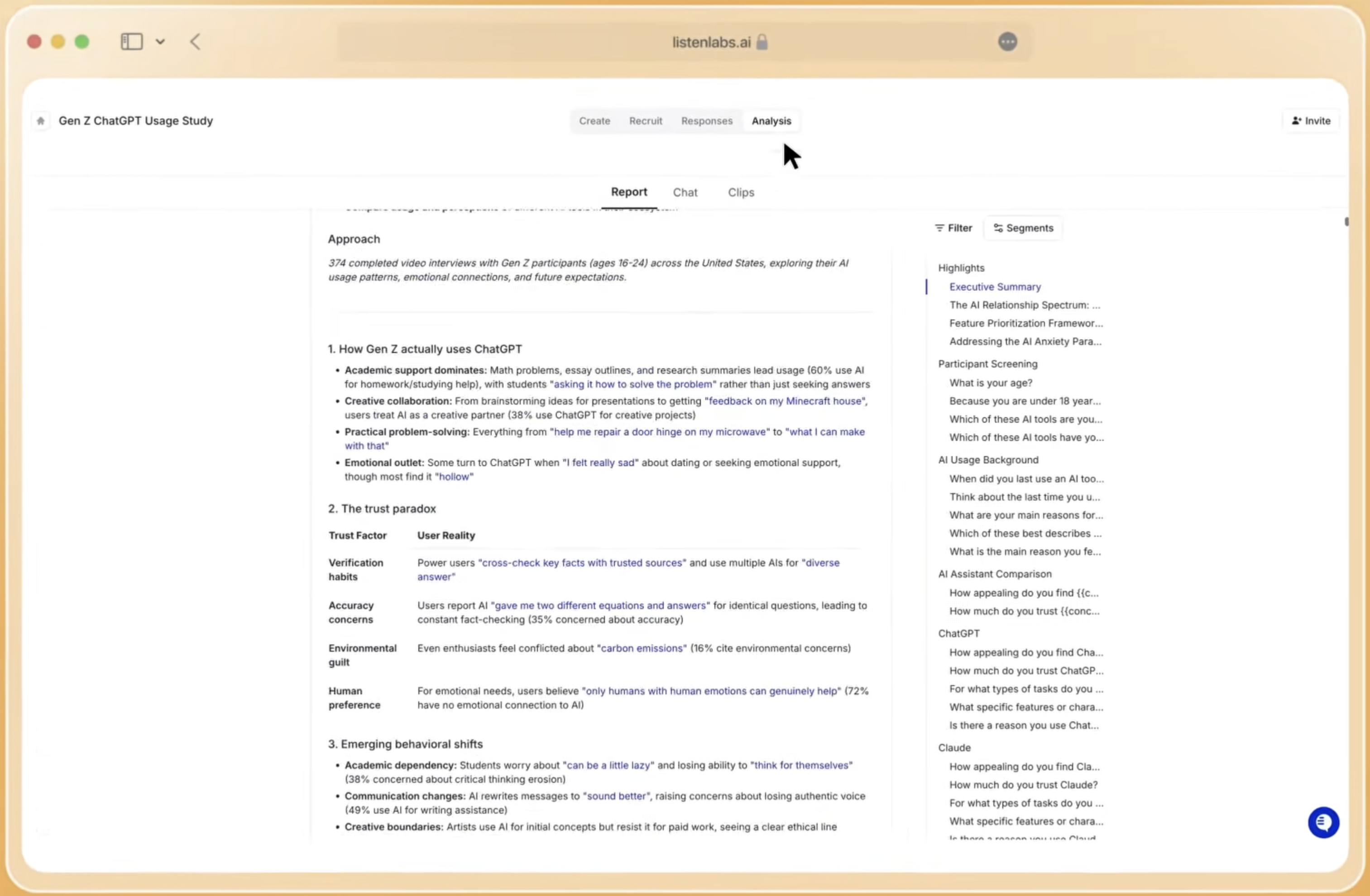
Cost drivers: Complexity of segmentation and number of stimuli. AI-moderated research can produce more actionable insights at a lower cost per insight compared with traditional agency studies.
Stage 4 – Activate Insights with Instant Deliverables
Inputs: Research Agent outputs, including slide decks, memos, highlight reels, statistical charts, and segmentation breakdowns.
Decision points: Match deliverable format to each stakeholder audience, such as executive memo, branded deck, or video reel, and decide which findings feed directly into a product, brand, or campaign decision.
Typical timeline: Research Agent generates a slide deck in a company’s branded template and a downloadable report in under a minute. Findings stored in Mission Control are queryable across all past studies, which prevents institutional knowledge loss.
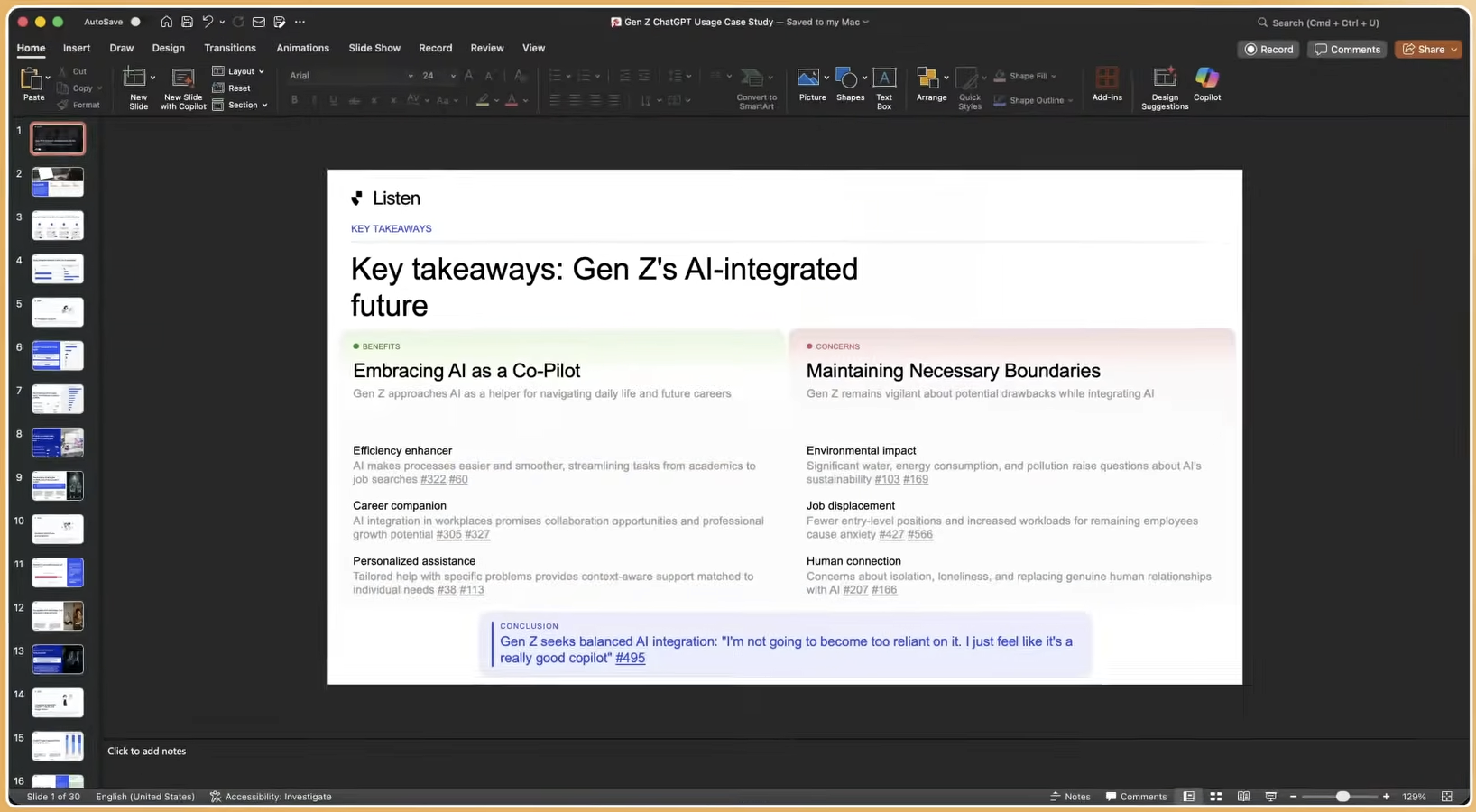
Cost drivers: Stakeholder alignment time, not platform cost. Linking every insight to timestamped video clips and verbatim quotes shifts stakeholder review from trusting researcher interpretation to evaluating primary evidence directly.
Real-World Workflows: Two Enterprise Examples
The four-stage workflow may sound abstract at first. Two enterprise deployments show how the complete pipeline performs in production, one focused on cross-market concept testing and the other on rapid story collection for brand content.
Global CPG concept test. A consumer packaged goods team needs to evaluate three product claims across five markets before a launch decision. Using an automated workflow, the team designs a monadic concept test with randomized stimulus exposure, recruits 50 participants per market overnight, and runs 250 simultaneous AI-moderated interviews. Emotional-signal analysis surfaces which claim triggers genuine enthusiasm versus polite acceptance, a distinction that transcript-only analysis would miss. Listen Labs’ Emotional Intelligence analyzes three signal layers, including tone of voice, word choice, and subconscious micro-expressions, to surface nuanced emotions that transcripts alone miss. Every emotion identified is quantified per question and concept, with every label traceable to the exact timestamp, verbatim quote, and AI reasoning behind it. The full cycle, from brief to cross-market synthesis, completes within 24 hours.
Microsoft 50th anniversary user stories. Microsoft needed to collect global customer stories about how Copilot was empowering users at speed and scale. Using Listen Labs, the team collected those user video stories within a day. The Director of Data Science at Microsoft noted: “Our leadership team was very thrilled at both the speed and the scale that Listen Labs enabled. I can reach out to hundreds of users at one third of the cost.”
Both cases depend on emotional-signal capture going beyond transcripts. Multimodal emotion AI systems demonstrate consistent but modest improvements in accuracy over unimodal approaches.
See how the full four-stage workflow performs on your research questions. Schedule a walkthrough of the complete pipeline.
Common Challenges and How to Address Them
Participant quality degradation. As mentioned in Stage 2, participant fraud is a documented risk. Non-genuine participation in online research falls into five categories: inauthentic participants faking lived experience, repeat responders, eligibility misrepresentation, disengaged responders, and automated bot activity. Mitigation requires layered controls, including behavioral matching on intent data rather than self-reported demographics, real-time AI monitoring across video and device signals, and human recruitment operations review for niche audiences.
Emotional-signal interpretation errors. Automated qualitative analysis can misread sarcasm, contextual nuance, and cultural sensitivity, especially when general-purpose models encounter industry-specific jargon or regional dialects. Treat emotional outputs as probabilistic signals and validate them against verbatim context before drawing conclusions.
Stakeholder alignment. Executives unfamiliar with AI-moderated research often question sample validity. Linking findings directly to timestamped video clips resolves this concern because stakeholders evaluate primary evidence rather than researcher summaries. As one CMI Manager noted: “The video clips make it tangible; it’s not just data anymore, it’s real people with real emotions.”
AI analysis shallowness. Overreliance on AI automation in qualitative analysis can diminish the critical and reflective role of human analysts, since AI cannot fully replicate complex human cognitive processes. A human-in-the-loop review step mitigates this risk. Researchers validate AI-generated theme clusters before activation rather than accepting them as final.
Measuring Success of Your Automated Workflow
Four KPIs govern workflow performance and show whether automation is delivering real business value.
- Cycle time: Measure elapsed hours from approved brief to stakeholder-ready deliverable. Target under 24 hours for standard studies.
- Cost per actionable insight: Track cost per study against the number of decisions directly informed. AI-moderated research can produce insights at a lower cost per insight versus traditional agency studies at equivalent scale.
- Statistical confidence: Track sample size per segment and confirm that theme saturation is reached. Because you have already established the operational capacity to run larger samples, you can now achieve theme saturation with statistical confidence rather than hoping a small sample was sufficient.
- Finding reuse rate: Measure how often past study outputs answer new stakeholder questions without commissioning a new study. Mission Control cross-study queries make this trackable.
Once you have measured baseline performance using these four KPIs, the next step is to evolve from one-off studies to continuous insight programs that compound value over time.
Scaling Into Continuous Insight Programs
Continuous insight programs replace one-off studies with always-on pipelines. Organizations adopting AI-first research workflows shift from quarterly or annual studies to continuous or weekly insight generation, which enables same-day strategic decisions. Longitudinal cohort designs, where you re-interview the same panel of 40–100 customers every 4–6 weeks, enable trend tracking at lower per-interview cost than recruiting fresh samples each cycle.
Retire a study when theme saturation stabilizes across three consecutive waves with no new codes emerging, or when the underlying business question has been resolved. Expand a study when a new market, segment, or stimulus set requires coverage that the existing design cannot accommodate without introducing confounds.
Cross-study knowledge bases compound in value over time. Each completed study enriches the institutional knowledge base, which reduces the proportion of research budget spent re-answering previously answered questions.
To operationalize this workflow in your existing tech stack, the templates below show how to connect Listen Labs to your project management, notification, and reporting tools using n8n or Zapier.
n8n and Zapier Integration Templates
The three templates below are copy-paste starting points. Adapt field names and webhook URLs to match your stack before deploying.
Template 1 – Study Brief Generator Prompt
System: You are a senior consumer insights researcher. Generate a structured study brief. User input: [BUSINESS_QUESTION], [TARGET_AUDIENCE], [KEY_DECISIONS_TO_INFORM], [STIMULI_AVAILABLE] Output format: - Research objective (one sentence) - Primary questions (5–8 open-ended) - Probing context per question (2–3 follow-up directions) - Screening criteria - Suggested quota by segment - Recommended n (minimum / preferred)
Template 2 – n8n Workflow JSON for Automated Participant Invites
{ "nodes": [ { "name": "Trigger: Study Approved", "type": "n8n-nodes-base.webhook", "parameters": { "path": "study-approved", "httpMethod": "POST" } }, { "name": "Filter: Quota Check", "type": "n8n-nodes-base.if", "parameters": { "conditions": { "number": [{ "value1": "={{$json.enrolled}}", "operation": "smaller", "value2": "={{$json.quota_target}}" }] } } }, { "name": "Send Invite Email", "type": "n8n-nodes-base.emailSend", "parameters": { "toEmail": "={{$json.participant_email}}", "subject": "You're invited to share your feedback", "text": "Hi {{$json.first_name}}, click here to begin: {{$json.interview_link}}" } } ] }
Template 3 – Slack and Sheets Reporting Webhook
// Zapier: Catch Hook → Google Sheets → Slack // Step 1 – Catch Hook (POST from Listen Labs Research Agent on study completion) // Step 2 – Google Sheets: Create Row // Columns: Study Name | Completion Date | n Completed | Top Theme 1 | Top Theme 2 | Report URL // Step 3 – Slack: Send Channel Message // Text: "Study complete: {{Study Name}} | {{n Completed}} interviews | Top theme: {{Top Theme 1}} | Report: {{Report URL}}"
FAQ
How long does a full four-stage automated workflow actually take?
For a standard study targeting a general or near-general population, the full cycle from approved brief to stakeholder-ready deliverables runs under 24 hours. Study design and AI co-drafting takes 30–90 minutes. Recruitment and parallel AI-moderated interviewing runs 2–24 hours depending on audience incidence rate and quota size. Automated thematic analysis and emotional-signal processing completes in 1–4 hours. Report and slide deck generation takes under a minute. Hard-to-reach audiences, such as enterprise decision-makers, healthcare workers, or consumers below 1% incidence, may extend the recruitment window, but the analysis and activation stages remain the same.
What incentive ranges should I budget for participants?
Incentive levels vary by audience type and study length. General consumer audiences for a 20–30 minute interview typically receive $10–$50. B2B professionals and specialized consumer segments range from $50–$150. Medical specialists and senior enterprise decision-makers can command $150–$500 or more per session. On Listen Labs, incentives are built into the per-participant credit cost rather than managed as a separate line item, which simplifies budget forecasting. Bring-your-own-participant studies reduce credit costs because Listen Labs is not sourcing from its panel.
How does the platform handle privacy compliance and data security?
Listen Labs holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. All data is encrypted at 256-bit. Customer data is never used to train AI models. Enterprise SSO is supported. For studies involving sensitive topics or regulated industries, the platform’s data-governance controls satisfy the requirements of most Fortune 500 legal and compliance teams. Researchers should still confirm jurisdiction-specific requirements, particularly for studies involving health data or participants in the EU, with their own legal counsel before launch.
Can the workflow reach niche or hard-to-find audiences?
Yes. Listen Labs’ dedicated recruitment operations team partners with niche communities, micro-creators, and specialized networks to source audiences below 1% incidence rate. This includes enterprise C-suite and director-level decision-makers, engineers, healthcare workers, and highly specific consumer segments defined by behavior or purchase history rather than demographics alone. The AI orchestration layer (Listen Atlas) matches and bids across multiple panel partners and Listen Labs’ proprietary database simultaneously, which increases sourcing speed for difficult segments. For the most specialized audiences, the recruitment operations team adds a human review layer on top of automated matching.
When should a continuous program replace one-off studies, and when should a study be retired?
A continuous program is appropriate when the business question recurs on a regular cadence, such as brand health tracking, NPS driver analysis, competitive perception monitoring, or sprint-cycle product feedback. The operational cost of running weekly or monthly pulses on an automated platform is low enough that continuous programs are now viable for mid-sized insights teams, not just enterprise research departments. A study should be retired when theme saturation has stabilized across three or more consecutive waves with no new codes emerging, or when the underlying business decision has been made and the question is no longer active. Studies should be archived in a cross-study knowledge base rather than deleted, so future teams can query historical findings without re-running research.


