
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways for Enterprise Research Leaders
- AI-moderated interviews replace human moderators with conversational AI that delivers adaptive follow-ups, captures multimodal signals, and compresses traditional 4–6 week research cycles into under 24 hours.
- Enterprise teams begin every study with a structured briefing that sets objectives, participant criteria, and behavioral guardrails; Listen Atlas then matches respondents from a 30-million-person verified network across 45+ countries.
- Real-time RAG-based probing, automatic transcription in 50+ languages, and AI-driven theme synthesis deliver consultant-quality outputs while maintaining full traceability from theme to verbatim quote to timestamped video.
- Quality Guard combines high-quality panel sources, real-time behavioral monitoring, and human review to block fraud and low-effort responses, while Emotional Intelligence captures tone, word choice, and micro-expressions for deeper insight.
- Listen Labs enables always-on, multi-market research programs that scale qualitative depth to quantitative sample sizes; see how leading enterprises run AI-moderated interviews end to end.
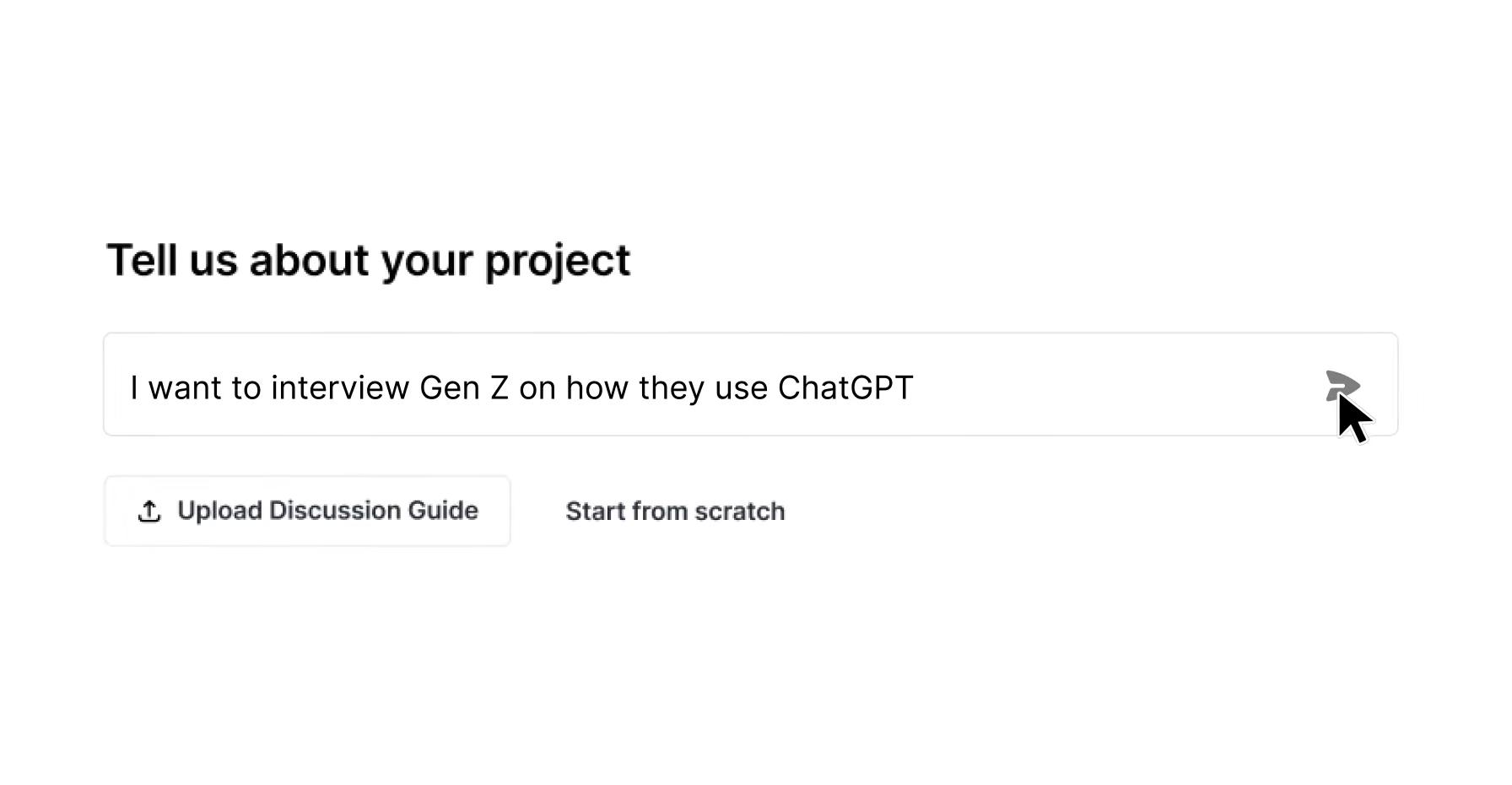
Step 1: Briefing and Study Setup for AI Moderation
Every AI-moderated study starts with a structured briefing that locks in research objectives, participant criteria, and behavioral guardrails. In Listen Labs, researchers describe goals in natural language, and the platform’s AI co-design layer drafts structured objectives, seed questions, and probing context. Auto-QA then flags gaps, misalignments, or feasibility issues before the study launches.
Participant matching criteria are also set at this stage. Listen Atlas, the platform’s AI orchestration layer, matches across behavioral and intent data, not just self-reported demographics, drawing from this verified network. Sample size decisions depend on two variables: audience incidence rate and research objective type. General population studies with broad incidence rates support larger samples at lower cost per complete. Hard-to-reach segments such as enterprise decision-makers, healthcare workers, or consumers below one percent incidence rate require dedicated recruitment operations and carry higher credit costs.
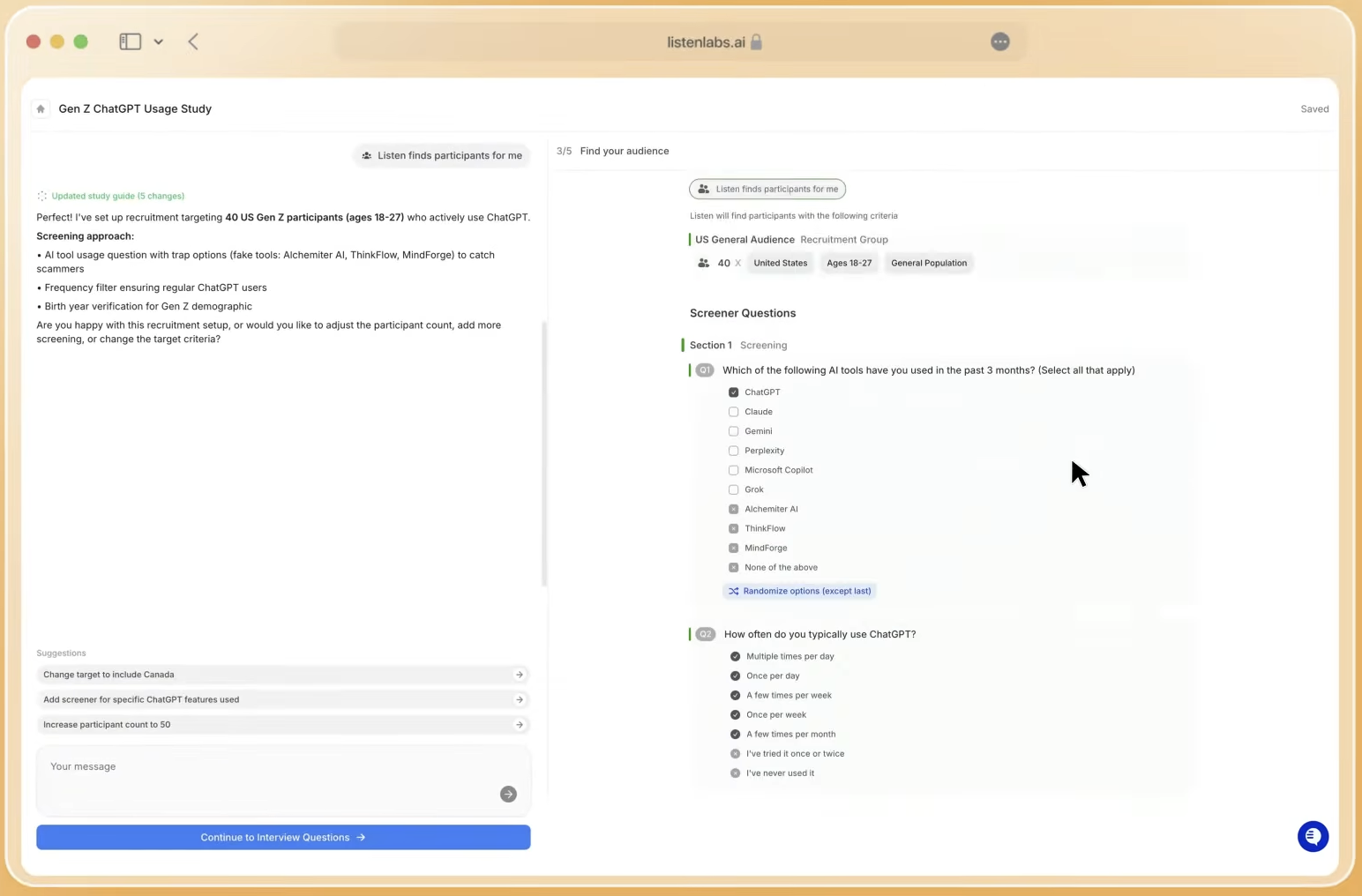
Beyond participant matching, the briefing stage also defines study design inputs. These inputs include stimuli configuration (images, video, PDFs, live URLs, or prototypes), branching and skip logic, quota controls, and version randomization for monadic or sequential concept tests. Each input constrains or expands what the AI moderator can do during live interviews. Together, they define the moderator’s behavioral envelope: which topics to probe, which to treat as structured closed-ended items, and where to allow open conversational exploration.
Step 2: Dynamic Interaction and Follow-Up Generation in Session
Once a participant enters the interview, the AI moderator delivers seed questions and evaluates each response in real time. AI can probe vague answers, follow up dynamically, and capture contextual nuance at survey-like scale, which clearly separates AI moderation from static survey instruments.
The technical mechanism for follow-up generation uses retrieval-augmented generation (RAG). In this setup, the system matches the participant’s response against the study’s objective context and generates a contextually grounded probe. RAG-based systems dynamically adapt conversational scenarios by matching individual inputs with specific contextual requirements. This capability enables the AI to ask the next most relevant question instead of marching through a fixed script.
Research shows that AI-moderated interviews can produce qualitative data of comparable richness to human-moderated interviews. The AI asks open, curious follow-ups that often generate some of the richest responses observed, while avoiding the leading questions that human moderators sometimes introduce.
These exploratory versus structured distinctions, set during the briefing stage in Step 1, determine how the AI moderator behaves during live interviews. Exploratory objectives such as unmet needs discovery or journey mapping benefit from wider probing latitude, which allows the AI to follow unexpected threads. Structured objectives such as concept ranking or claim evaluation use tighter guardrails that keep the conversation on predefined stimuli while still permitting one to two levels of follow-up per response.
Step 3: Real-Time Transcription and Synthesis You Can Audit
Listen Labs captures video, audio, and text simultaneously during each session. Transcription runs in real time across 50-plus languages with automatic translation, which makes multi-market studies executable within a single fielding window.
After each interview, the Research Agent processes all transcripts to identify themes, patterns, and anomalies across the full sample. AI can analyze transcripts for themes and generate quantitative insights from qualitative interviews. Outputs include automated key findings, persona clusters, verbatim evidence, and statistical breakdowns by segment.
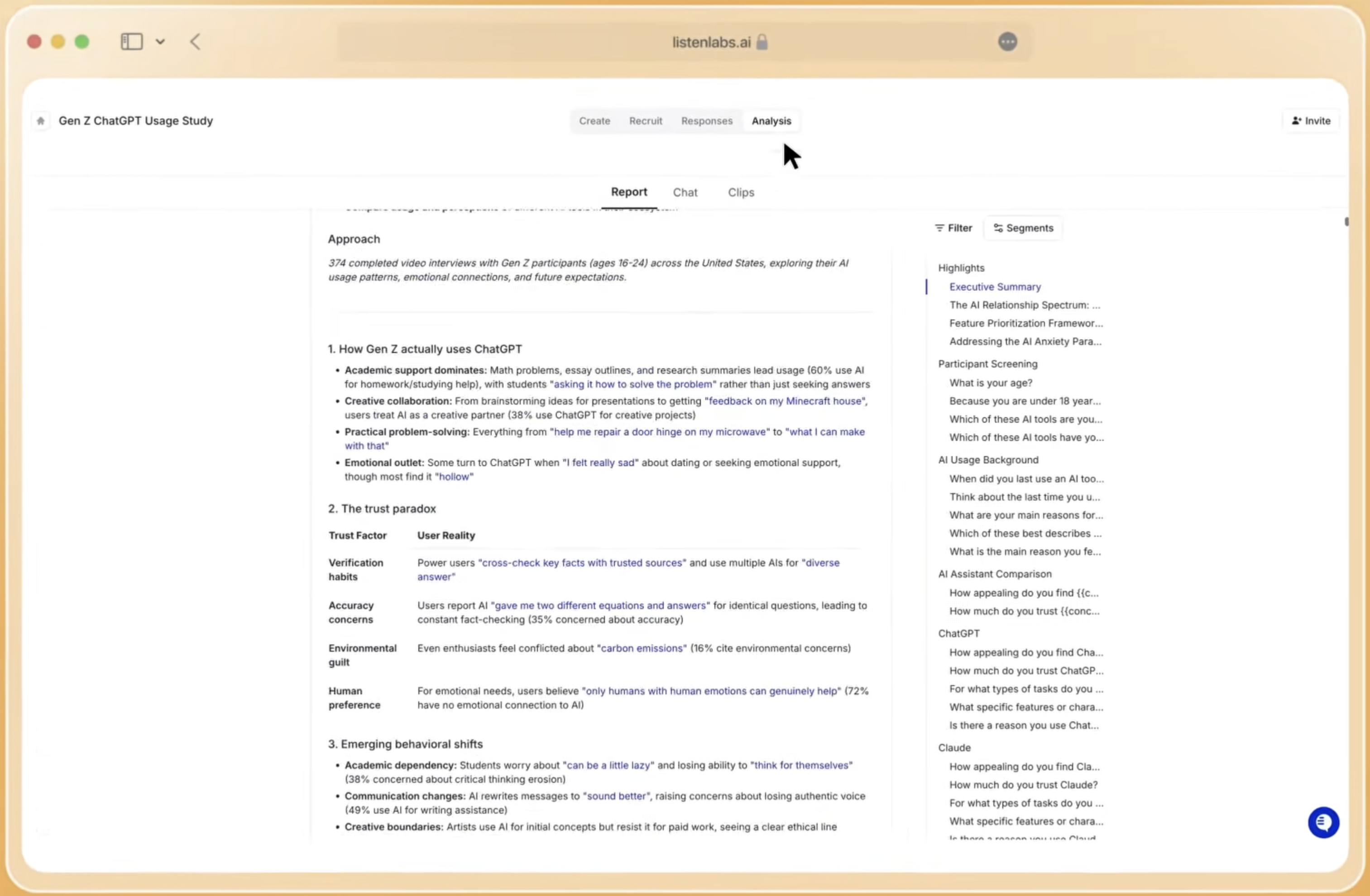
The Research Agent’s synthesis outputs must meet enterprise traceability standards to be actionable. Without a unified chain of compliance, from AI theme to verbatim quote to timestamped video clip to participant metadata, AI research findings can be challenged or rejected by procurement, legal, or senior stakeholders. Listen Labs’ Research Agent maintains this chain, so any stakeholder can move from a high-level theme to the exact quote and video timestamp that supports it.
Step 4: Quality and Fraud Controls at Scale
Participant fraud creates structural risk in large-scale research, especially when incentives are meaningful. Fraud detection systems that combine automated risk scoring with manual review by trained operations staff can catch most likely fraud before it affects researchers.
Listen Labs’ Quality Guard operates across three layers. First, the platform works exclusively with high-quality, non-commodity panel sources, which excludes professional survey-takers by design. Second, real-time AI monitoring evaluates video, voice, content, and device signals during each session, flagging low-effort responses, AI-generated scripts, mismatched profiles, and behavioral anomalies. Behavioral red flags include applying immediately after a study launches, applying at unusual hours for the target time zone, refusing to turn video on when requested, and delayed responses that may indicate chatbot use. Third, a dedicated recruitment operations team adds human review, and participants are capped at three studies per month to eliminate panel fatigue and incentive-driven respondents.
Within the real-time AI monitoring layer, early-warning indicators for low-effort responses include response length below study-specific thresholds, vocabulary inconsistent with stated professional profile, and sentiment patterns that mirror social desirability rather than genuine opinion. AI moderators probe every response with equal curiosity and zero social pressure, which reduces social desirability bias at the data-collection stage. Even with this advantage, some participants still provide low-effort responses that pass real-time moderation. Post-interview quality scoring provides a second filter for these edge cases, where responses avoid fraud detection during the session but show low engagement signals upon review.
Step 5: Emotional Intelligence Capture Across Markets
Emotional Intelligence analyzes three signals: tone of voice, word choice, and subconscious micro-expressions. This multimodal combination separates what participants say from what they actually feel. Two concepts can receive identical verbal ratings while generating measurably different emotional responses, and without signal capture at this layer, that distinction stays invisible to the research record.
Listen Labs built Emotional Intelligence using Ekman’s universal emotions framework, tracking anger, anticipation, disgust, fear, joy or happiness, sadness, trust, and surprise. This standard also appears in clinical psychology and UX research. Grounding in an established framework ensures that emotional labels carry methodological defensibility across research contexts, from CPG creative testing to financial services usability studies.
Every emotion is quantified per question and concept, with every label traceable to the exact timestamp, verbatim quote, and AI reasoning behind it. A product team testing two packaging concepts can ask the Research Agent which concept triggered the most confusion, receive a side-by-side emotional breakdown by segment and market, and pull video highlight reels of the specific moments driving that signal. Teams achieve this workflow without manual clip review.
Emotional Intelligence is available across 50-plus languages, so global multi-market studies can run on a single workflow instead of separate localized analysis tracks.
Step 6: Choosing AI, Human, or Hybrid Moderation
AI moderation does not fit every scenario, and objective criteria clarify when human oversight adds measurable value. These criteria help teams standardize decisions instead of debating preferences on a project-by-project basis.
Use AI moderation when the research objective is well-defined, the audience is consumer or mid-level professional, sample size exceeds 30 participants, and the topic does not involve acute emotional sensitivity. 92% of participants report top comfort levels in AI-moderated sessions, and 58% of participants preferred AI moderation for discussing political and religious views, where reduced social judgment produces more candid data.
Use human moderation when the topic requires real-time empathic navigation, such as acute health disclosures or bereavement. Human moderators also fit best when the audience is C-suite executives who expect peer-level dialogue, or when the research question is highly ambiguous and requires iterative hypothesis refinement mid-session.
Use a hybrid approach when a study needs both breadth and depth rather than a binary choice. In this structure, AI moderates a large-sample discovery phase, then human moderators run deep follow-up on emergent themes with a small purposive sample. This approach captures statistical pattern identification at scale while preserving the interpretive depth that complex or ambiguous findings require. High-stakes or highly ambiguous studies still benefit from human oversight even when the majority of data collection is AI-led.
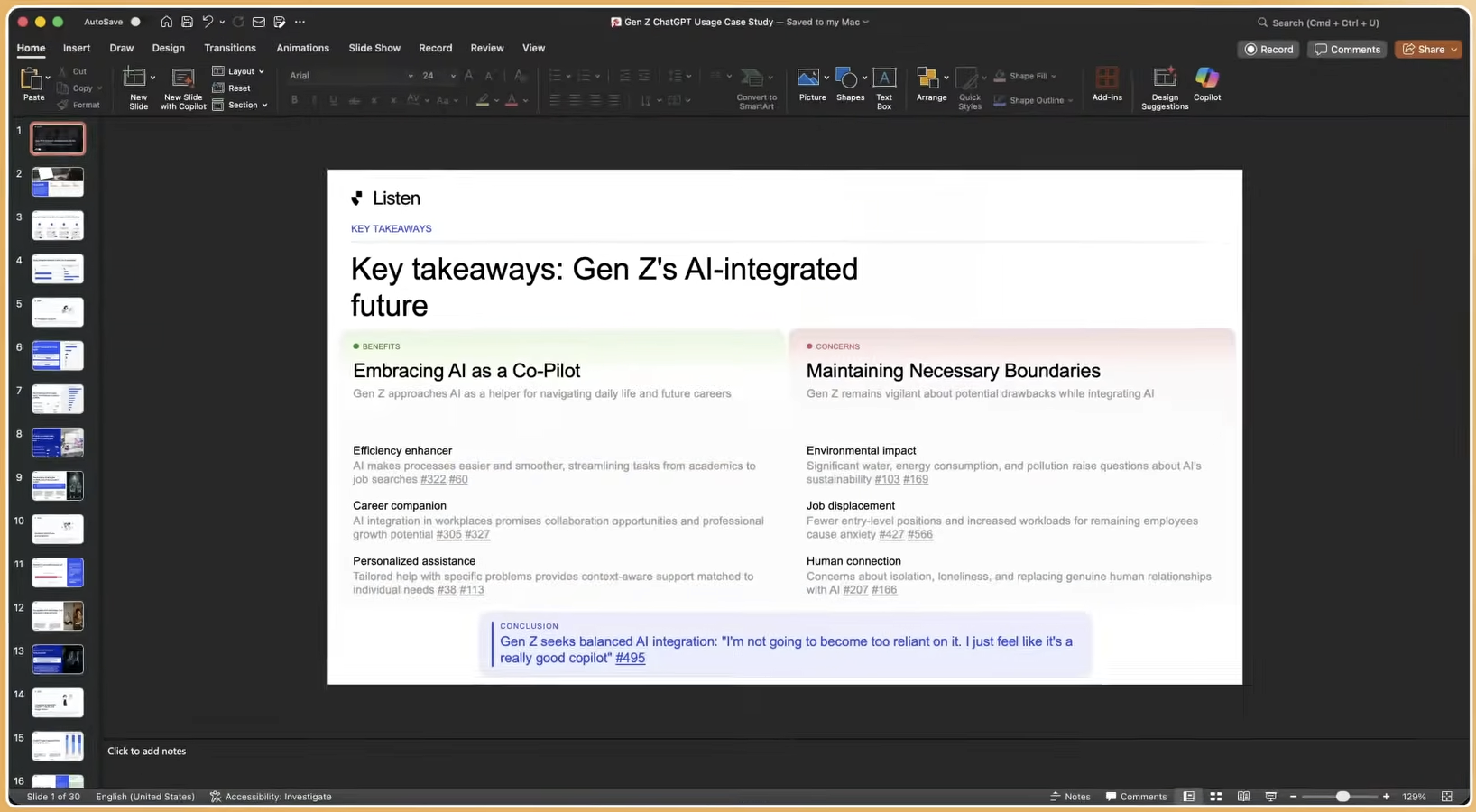
Success Indicators and Advanced Program Design
Clear success indicators help teams evaluate AI-moderated research programs against existing methods. Useful metrics include research cycle time (target under 24 hours from brief to deliverable), interview completion rates as a proxy for participant experience quality, finding consistency across replicated studies, and cost per complete relative to traditional agency benchmarks. Listen Labs clients including Microsoft, P&G, and Anthropic have used the platform to reduce research wait times from weeks to hours while maintaining consultant-quality output.
Always-on research programs represent the most advanced application of AI moderation at enterprise scale. Instead of running only discrete studies, organizations configure continuous fielding windows that capture customer sentiment, product feedback, and competitive perception on a rolling basis. Mission Control supports these programs by aggregating findings across all studies into a queryable knowledge base, which enables cross-study trend tracking and prevents institutional knowledge loss when insights sit in scattered slide decks.
Global multi-market studies benefit from Listen Labs’ support for 100-plus interview languages with automatic translation, allowing a single study design to field simultaneously across markets in the Americas, Europe, APAC, and MEA. Behavioral and emotional data integration, which connects Quality Guard signals, Emotional Intelligence outputs, and Research Agent theme analysis, produces a unified data layer. This layer supports both tactical decisions such as which ad concept to proceed with and strategic ones such as how brand perception shifts across segments over time.
Schedule a walkthrough to see how enterprise teams at Microsoft, P&G, and Anthropic run AI-moderated research programs on Listen Labs.
Frequently Asked Questions
How long does a full AI-moderated research cycle take on Listen Labs?
The complete cycle, from study brief to final deliverables including slide decks, theme analysis, and video highlight reels, runs in under 24 hours for most studies. Recruitment begins immediately after study launch, interviews field asynchronously, and the Research Agent generates outputs as completions accumulate. Studies requiring hard-to-reach audiences or very low incidence rates may take longer depending on recruitment complexity.
How does Listen Labs prevent fraudulent or low-quality participants from entering a study?
Quality Guard operates across three layers: exclusive use of high-quality, non-commodity panel sources; real-time AI monitoring of video, voice, content, and device signals during each interview; and a dedicated recruitment operations team that adds human review for complex or niche audiences. Participants are capped at three studies per month to eliminate professional survey-takers. The platform holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications, and customer data is never used for AI model training.
Can AI moderation reach niche or hard-to-find audiences?
Yes. Listen Labs’ recruitment operations team partners with niche communities, micro-creators, and specialized networks to source audiences below one percent incidence rate, including enterprise decision-makers, engineers, healthcare workers, and highly specialized consumer segments. Organizations can also bring their own participants or panel providers, fielding AI-moderated interviews against their existing user base at reduced cost.
What compliance and data privacy standards apply to AI-moderated interviews on Listen Labs?
Listen Labs maintains enterprise-grade security with 256-bit encryption and holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. The platform supports enterprise SSO. Participant consent is collected before each interview begins, and organizations can configure data collection on a per-study basis, including video, name, and email, while screen-sharing settings can be set to optional, mandatory, or disabled. Sensitive or personally identifiable information can be masked from recordings post-session.
When should a research team use AI moderation versus a human moderator?
AI moderation works best for the scenarios described in Step 6: well-defined objectives, consumer and mid-level professional audiences, and studies requiring 30 or more participants. The reduced social judgment in AI-moderated sessions improves candor on sensitive topics like personal finances, political views, and health behaviors. Human moderation adds measurable value for C-suite executive audiences, highly ambiguous research questions requiring iterative hypothesis refinement, and topics involving acute emotional sensitivity. A hybrid approach, with AI for broad discovery and humans for deep follow-up on emergent themes, fits studies that combine scale requirements with interpretive complexity.
Conclusion
AI-moderated research interviews resolve the depth-versus-scale trade-off that has constrained enterprise qualitative research for decades. By automating adaptive probing, real-time transcription, multimodal emotional signal capture, and multi-layer fraud detection within a single end-to-end platform, the method resolves the operational constraints that have limited enterprise qualitative research for decades.
The mechanics described in this guide, from RAG-based follow-up generation and Ekman-grounded emotional analysis to Quality Guard fraud controls and hybrid moderation criteria, already support live research programs at enterprises including Microsoft, Procter & Gamble, Anthropic, and Skims. These programs show that AI moderation can meet the evidentiary standards of demanding stakeholders while expanding throughput.
For VP and Director-level consumer insights leaders managing growing backlogs, the implication is direct. The infrastructure now exists to multiply research output without proportional increases in headcount or budget, while still meeting the requirements of procurement, legal, and senior leadership.
Request a demo to see how Listen Labs can compress your next research cycle to under 24 hours.


