
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways for Enterprise Research Leaders
- Legacy platforms like Forsta and Discuss.io create trade-offs in cycle time, participant quality, moderation depth, and analysis speed that slow enterprise qualitative research in 2026.
- Listen Labs compresses the full research cycle to under 24 hours with AI-assisted design, parallel AI moderation, and automated deliverables while preserving research rigor.
- Listen Atlas and Quality Guard improve participant quality using a verified 30-million-respondent panel across 45+ countries with real-time fraud detection and behavioral matching.
- Emotional Intelligence analysis captures micro-expressions, tone, and word choice with timestamp traceability across 50+ languages, revealing insights transcripts alone miss.
- See how Listen Labs closes legacy gaps and accelerates your research output.
Research Cycle Time and Study Design Bottlenecks
Enterprise qualitative projects on legacy stacks typically run four to six weeks from brief to final deliverable. Internal prioritization queues, budget approvals, and vendor coordination often stretch that to six months in large organizations. Forsta’s Decipher platform powers 40,000+ studies per year and more than one billion surveys annually, which proves scale, yet design and reporting still depend on analysts. Discuss.io supports live virtual depth interviews and focus groups with built-in observation tools, automated transcription, tagging, and clip creation, but human scheduling and moderation still cap throughput and slow feedback loops.
Continuous customer intelligence in 2026 requires research that runs as an always-on function, not a sequence of one-off projects. Manual-first workflows hit a ceiling under that model because every phase queues behind people. Listen Labs compresses the full cycle to under 24 hours through AI-assisted study co-design, auto-QA before launch, cloning of past studies, and branching logic that configures in minutes instead of days. Anthropic’s Claude Code team ran 300+ user interviews in 48 hours and surfaced churn drivers five times faster than prior methods using Listen Labs.
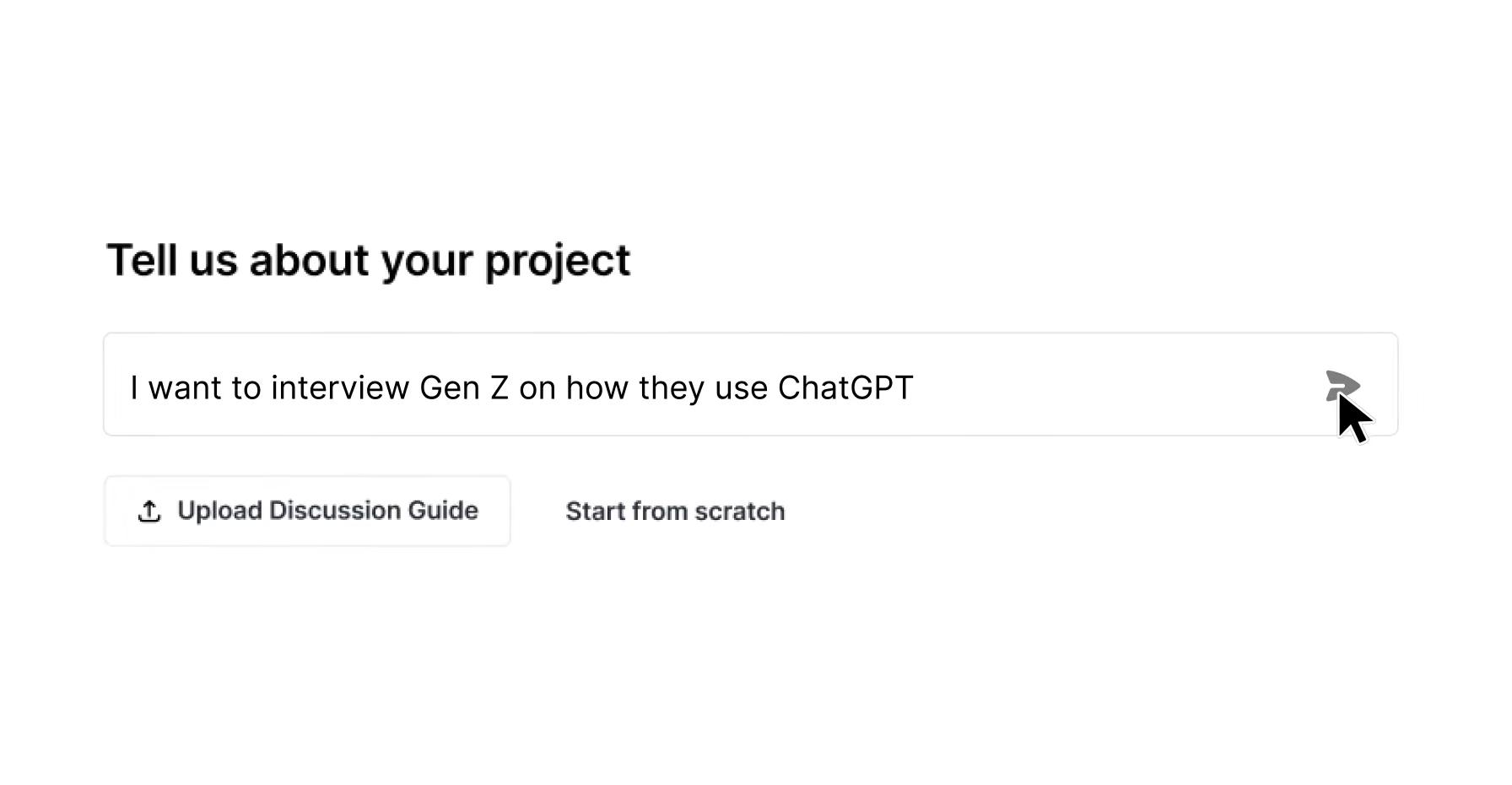
See a live study launch from brief to fielding in under ten minutes.
Participant Recruitment, Sampling, and Fraud Controls
Speed only matters when participant quality holds up. Participant quality becomes structurally vulnerable when platforms depend on third-party commodity panels. Proprietary panels often recruit faster but can narrow sample diversity, while open platforms using third-party panels broaden reach but demand heavier quality management. Forsta’s Decipher integrates server-to-server connections with panel providers and quality tools such as Dynata’s Qualityscore and Research Defender. These controls help at the survey layer, yet they do not monitor live interview behavior, and sourcing still depends on external panels. Discuss.io follows a similar model, relying on third-party recruitment without a proprietary panel tuned for qualitative depth.
Listen Labs addresses this structural risk with an integrated quality stack. Listen Atlas, an AI orchestration layer, matches participants using behavioral and intent signals, not only self-reported demographics, across a verified network of 30 million respondents in 45+ countries. To keep those matches reliable over time, Quality Guard monitors every interview in real time across video, voice, content, and device signals. Even strong participants can degrade when overused, so Listen Labs caps each person at three studies per month to prevent professional survey-takers. A dedicated recruitment operations team supports audiences below 1% incidence rate, including enterprise decision-makers, healthcare workers, and engineers. Each completed study feeds back into the reputation scoring system, which creates a compounding quality advantage that externally sourced panels cannot match.
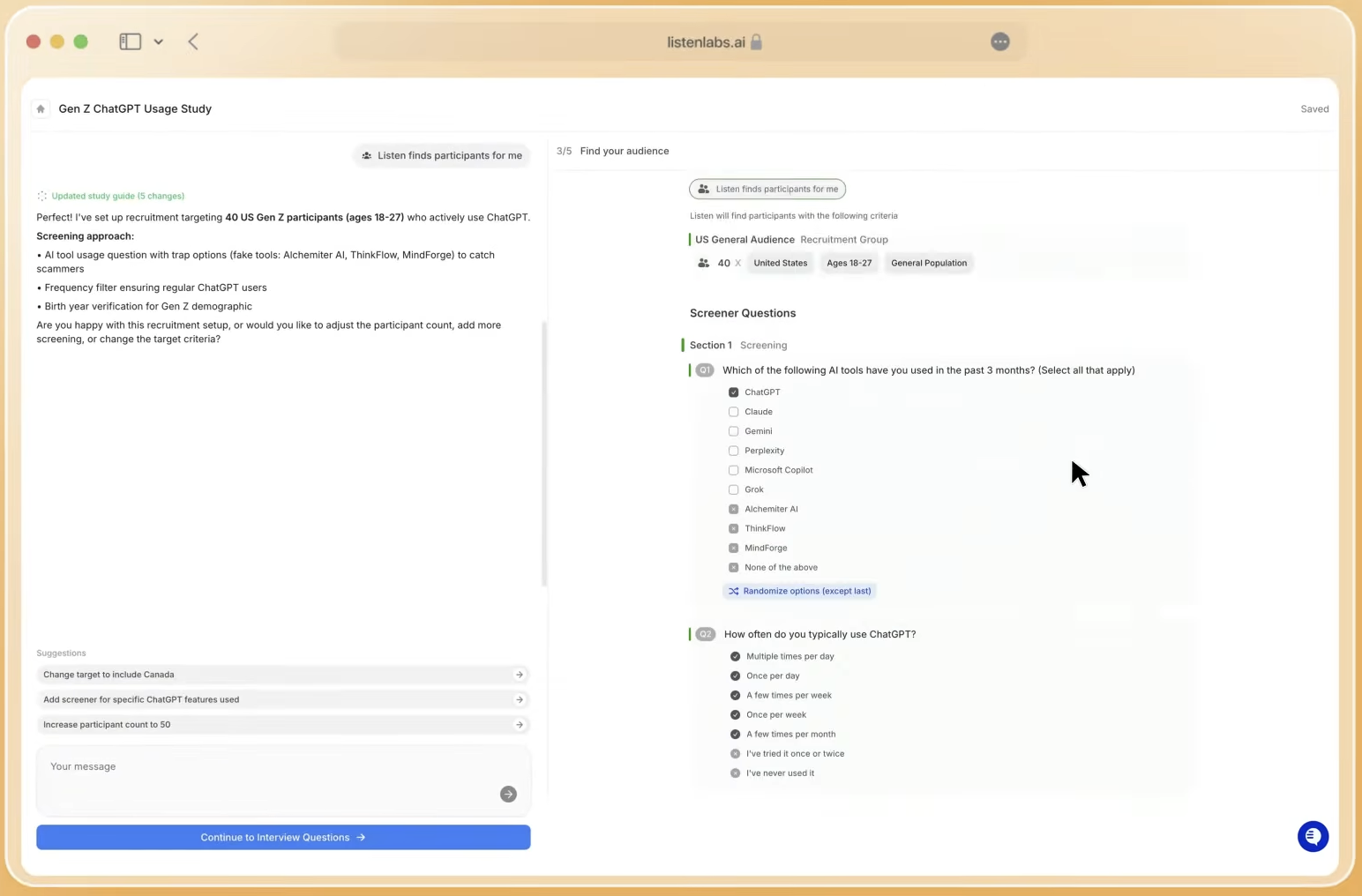
Moderation Depth, Adaptability, and Emotional Signal Capture
Discuss.io centers on live human-led sessions with virtual backroom collaboration and browser-based access for observers. Forsta InterVu, built on FocusVision’s legacy, recreates traditional facility setups in a virtual environment with recording and session management. Both models depend on moderator calendars, introduce scheduling friction, and produce inconsistent depth across interviewers and markets.
Listen Labs runs AI-led video interviews that adapt in real time. The AI moderator asks dynamic follow-up questions that probe short or unexpected answers the way a trained human would. Because the moderator can adjust on the fly, researchers can combine screen sharing, mobile screen recording on iOS, and mixed-method formats with qualitative questions, Likert scales, NPS, MaxDiff, and sliders in a single session. This adaptive moderation works across 100+ languages without separate localization vendors, which keeps global programs consistent.
Emotional signals often reveal what participants cannot or will not say directly. Hesitation can signal confusion, enthusiasm can contradict neutral ratings, and polite language can mask frustration. The Emotional Intelligence layer captures these signals at scale. Built on Ekman’s universal emotions framework, it analyzes tone of voice, word choice, and subconscious micro-expressions at the same time. Every emotion is quantified per question and concept, with each label traceable to the exact timestamp, verbatim quote, and reasoning. This runs across 50+ languages and connects directly to the Research Agent for natural-language queries and highlight reels of emotionally significant moments. Two concepts can receive identical verbal ratings yet trigger very different emotional responses, which transcript-only analysis cannot detect.
Analysis Workflow, Bias Reduction, and Deliverables
Research teams increasingly turn to AI for analysis because manual synthesis cannot keep pace with modern study volume. Legacy platforms acknowledge this need but still center analysis on human interpretation. Forsta highlights integration between Decipher and Visualizations that cuts time to insight through automated PowerPoint output. The slides arrive faster, yet the underlying analysis still depends on human judgment and remains vulnerable to confirmation bias. Discuss.io automates transcription and clip creation, which reduces tagging effort but leaves theme generation, persona building, and deliverable creation manual.
Listen Labs’ Research Agent processes the full interview corpus objectively and at scale. It identifies patterns and themes across hundreds of responses without relying on analyst hunches. The system generates slide decks, memos, highlight reels, statistical charts, and segmentation breakdowns in under a minute. Stakeholders can query the data in natural language and receive answers, stat tests, and custom segments without formal research training. A proprietary dataset from tens of thousands of completed studies helps the platform distinguish real signal from noise, which general-purpose LLMs cannot match.
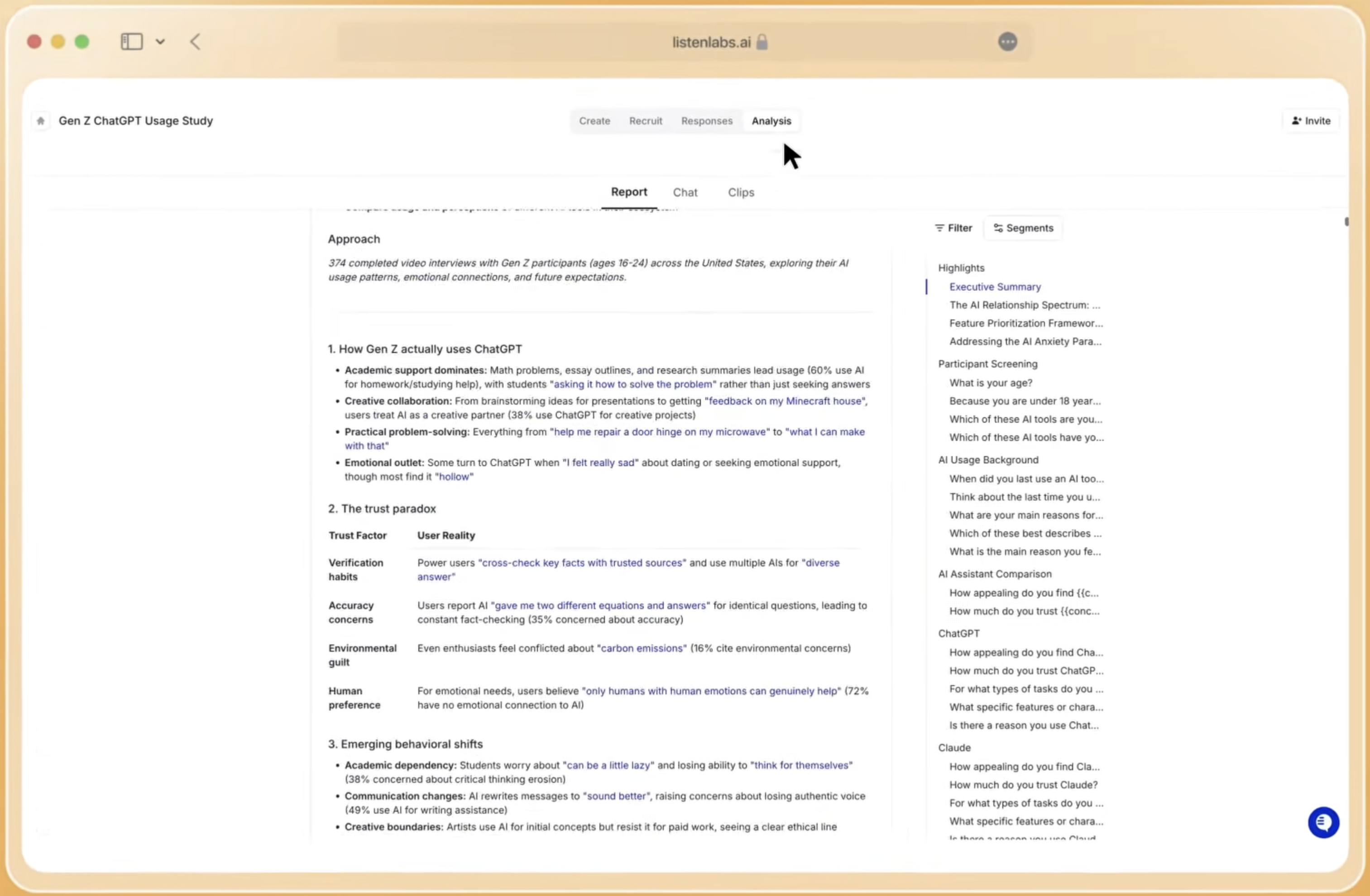
Global and Multilingual Reach with Cross-Study Knowledge
Global teams need more than translated surveys. Forsta’s Decipher supports surveys in multiple languages, which covers survey-layer localization. Qualitative research, however, depends on adaptive, probing conversations in each language, not just translated prompts. Discuss.io’s live moderation model depends on human moderator availability, so practical multilingual reach stays limited to languages covered by available moderators.
Listen Labs conducts AI-moderated interviews across 100+ languages with automatic translation and transcription, which enables simultaneous global fieldwork without separate localization vendors or moderator sourcing per market. Mission Control then acts as the organization’s source of truth across all completed studies. Teams can run cross-study queries, track trends over time, and preserve institutional knowledge beyond individual projects. Each study enriches this knowledge base instead of ending as a static deck.
See how Mission Control surfaces cross-study intelligence in seconds.
Total Cost of Ownership and Operational Burden
Legacy qualitative research carries costs that extend well beyond platform licenses. Separate vendors for recruitment, scheduling, moderation, transcription, analysis, and reporting each add fees, handoff delays, and quality risk. Enterprise platforms like UserTesting use custom pricing with a median annual price near $26,000 for access alone, before recruitment, moderation, and analysis. Forsta’s custom pricing and Discuss.io’s per-session structure still require additional vendor spend to complete a full research cycle.
Microsoft’s Director of Data Science reached hundreds of users at roughly one-third of prior costs using Listen Labs, compressing a six-to-eight-week process into a single day. Listen Labs replaces the multi-vendor stack with one subscription that covers study design, recruitment, moderation, analysis, and deliverables. The platform absorbs scheduling, quality assurance, vendor coordination, and report writing, which reduces operational burden on research teams and frees headcount for higher-value work.
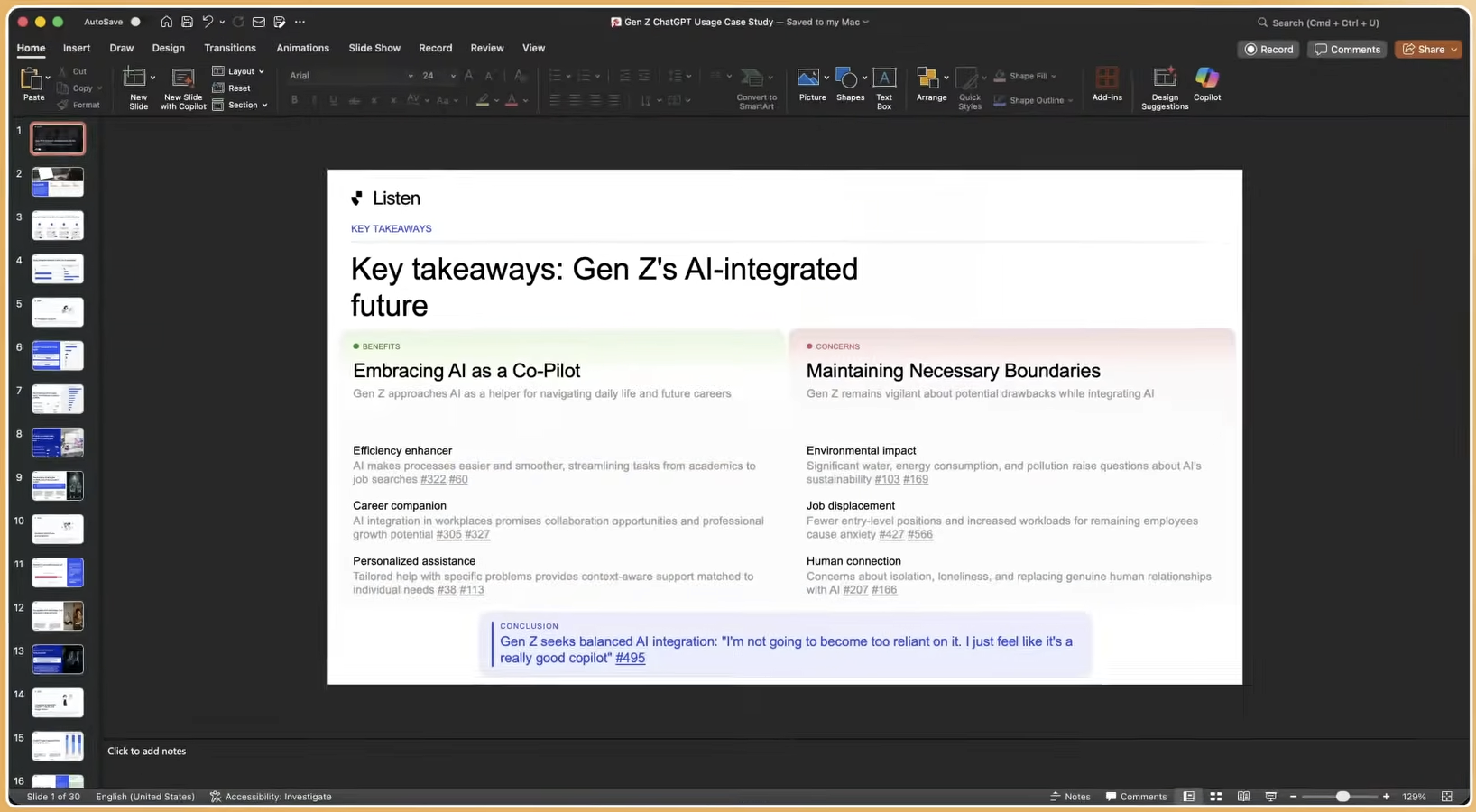
Persona-Specific Fit for Key Stakeholders
VP and Director-level consumer insights leaders at Fortune 500 companies in tech, CPG, retail, and food and beverage face growing backlogs where each study consumes four to six weeks of team capacity. Listen Labs multiplies output without proportional headcount increases, so the same team can run work that previously required agencies. P&G’s Analytics and Insight Leader used Listen Labs to complete 250+ interviews with quantified themes and verbatim proof in hours, shaping product and brand strategy before launch.
UX research leads who must validate concepts and test prototypes within sprint cycles benefit from integrated screen sharing, mobile screen recording, and the ability to run 50–100+ participant usability studies instead of five to ten sessions limited by calendars. Robinhood used Listen Labs to identify experience patterns and user segments that drove 2.4x higher weekly re-engagement, with insights delivered five times faster than earlier methods.
Product managers and marketing leaders without dedicated research teams can describe goals in natural language and receive a structured study, recruited participants, moderated interviews, and a finished deliverable. Agencies and consultancies that need niche global audiences, including enterprise decision-makers, healthcare workers, and consumers below 1% incidence, access the dedicated recruitment operations team alongside the verified global panel mentioned earlier.
Operational and Long-Term Adoption Considerations
Moving from a legacy platform to an AI-native solution requires coordinated change across research, product, and marketing teams. The core question is workflow integration rather than simple feature replacement. Listen Labs functions as a force multiplier for existing researchers, not a substitute for them. A self-serve natural-language interface lowers the training barrier for non-research stakeholders while still giving research professionals the controls they need for methodological rigor.
Enterprises running continuous customer intelligence programs also need repeatability across markets and time. Mission Control’s cross-study query and trend tracking capabilities address the institutional knowledge gaps that arise when findings live in isolated decks. Skims used Listen Labs to validate concepts with thousands of high-income buyers overnight, cutting weeks of recruiting and delivering qualitative clarity that secured board-level buy-in. That pattern then repeats across campaigns because the workflows and templates remain consistent.
Risks and Limitations of Legacy Qual Approaches
Rigid moderation structures in platforms like Forsta InterVu and Discuss.io often produce shallow data when participants give unexpected answers that a fixed guide cannot pursue. Slow turnaround compounds the problem because product and marketing decisions move ahead on partial information. Hidden recruitment complexity, especially for niche audiences sourced through third-party panels, introduces both delay and fraud exposure that quality scoring tools only partially mitigate.
Many teams assume faster tools must sacrifice quality, yet the real trade-off sits in rigidity. An adaptive AI interviewer that probes short answers and follows surprising threads can produce richer data than a human moderator who must stick to a script within a tight time slot. Legacy platforms carry quality risk not because they move too fast, but because they cannot flex to what participants actually say in the moment.
Decision Framework and Practical Checklist
Research leaders can evaluate platforms more clearly by applying a simple set of requirements. When results must arrive in under 24 hours from brief to deliverable, manual-first platforms cannot meet that bar. When a study requires 300+ interviews within 48 hours, platforms without parallel AI moderation and a proprietary large-scale panel will not reach that volume. When teams need multilingual moderation across 100+ languages without separate vendor sourcing, survey translation alone will not suffice. When procurement demands SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001, leaders should verify certifications rather than accept general security claims. When emotional signal capture matters beyond transcript content, platforms must analyze micro-expressions, tone, and word choice together with timestamp traceability. When finance teams want a single subscription that replaces recruitment, moderation, and analysis vendor fees, leaders should compare total cost of ownership across the entire research stack, not just license price.
Walk through this checklist against your current research stack in a live demo.
Frequently Asked Questions
How does Listen Labs maintain rigor while compressing timelines?
Listen Labs maintains rigor through structured study templates, auto-QA checks before launch, and adaptive AI moderation that follows predefined research goals. Quality Guard monitors every session for fraud and low-effort responses, and the Research Agent draws on a large proprietary dataset to separate meaningful patterns from noise. These safeguards keep quality high even as timelines shrink from weeks to hours.
How does Listen Labs protect participant quality at scale?
Listen Atlas matches participants on behavioral and intent data rather than only self-reported demographics, using the verified global panel described earlier. Quality Guard then monitors video, audio, and content signals in real time to flag fraud, AI-generated scripts, and low engagement. A recruitment operations team adds human review for hard-to-reach segments, and monthly participation caps prevent professional survey-takers from distorting results.
How is Listen Labs’ AI moderation different from tools that only record sessions?
Forsta InterVu and Discuss.io rely on human moderators and use their tools mainly for observation, recording, and transcription. Listen Labs uses AI as the primary moderator, running hundreds of interviews in parallel while adapting questions to each participant’s responses. The Emotional Intelligence layer then analyzes micro-expressions, tone, and language choices across the full sample, which human moderators cannot track consistently at scale.
Does Listen Labs meet enterprise security and compliance standards?
Listen Labs holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. Customer data uses 256-bit encryption and never feeds AI model training. Enterprise SSO is available. These controls cover information security, privacy, and AI management, which aligns with typical Fortune 500 procurement and legal requirements.
Can Listen Labs support always-on research programs?
Mission Control supports ongoing research by storing every completed study in a single searchable environment. Teams can run cross-study queries, track trends over time, and reuse proven designs. This structure supports the shift from isolated projects to always-on research infrastructure where insights compound instead of resetting with each new brief.
Conclusion: Matching Platforms to 2026 Research Demands
Forsta and Discuss.io were built for a research model that assumed human moderation, sequential workflows, and third-party panel sourcing as fixed constraints. In 2026, those constraints no longer hold. The criteria covered in this article, including cycle time, participant quality, moderation depth, analysis speed, emotional signal capture, multilingual reach, total cost of ownership, and enterprise compliance, reveal a structural gap between legacy capabilities and continuous customer intelligence needs.
Listen Labs closes that gap with a single end-to-end platform. It combines AI-assisted study design, a verified global panel with Quality Guard fraud controls, AI-moderated video interviews with Ekman-based emotional intelligence across 50+ languages, a Research Agent that generates deliverables in under a minute, and Mission Control for cross-study institutional knowledge. Outcomes include under 24 hours from brief to deliverable, 300+ interviews in 48 hours, and roughly one-third the cost of traditional research approaches, as demonstrated by Microsoft, Anthropic, P&G, Skims, and Robinhood.


