
Written by: Anish Rao, Head of Growth, Listen Labs | Last updated: July 14, 2026
Key Takeaways for Enterprise Insights Leaders
- AI research assistants achieve 85–97% accuracy on transcription and sentiment tasks but require human verification for complex inductive analysis and root-cause reasoning.
- Generic LLMs face higher hallucination risks and struggle with inductive reasoning, so human oversight remains essential for reliable enterprise insights.
- Specialized platforms outperform generic tools by combining proprietary data, real-time quality controls, and dedicated emotional intelligence layers.
- Listen Labs delivers consultant-quality results in under 24 hours through verified respondents, Quality Guard, and 50+ years of research expertise.
- Book a demo with Listen Labs to see how its enterprise-grade platform improves customer research accuracy and speed.
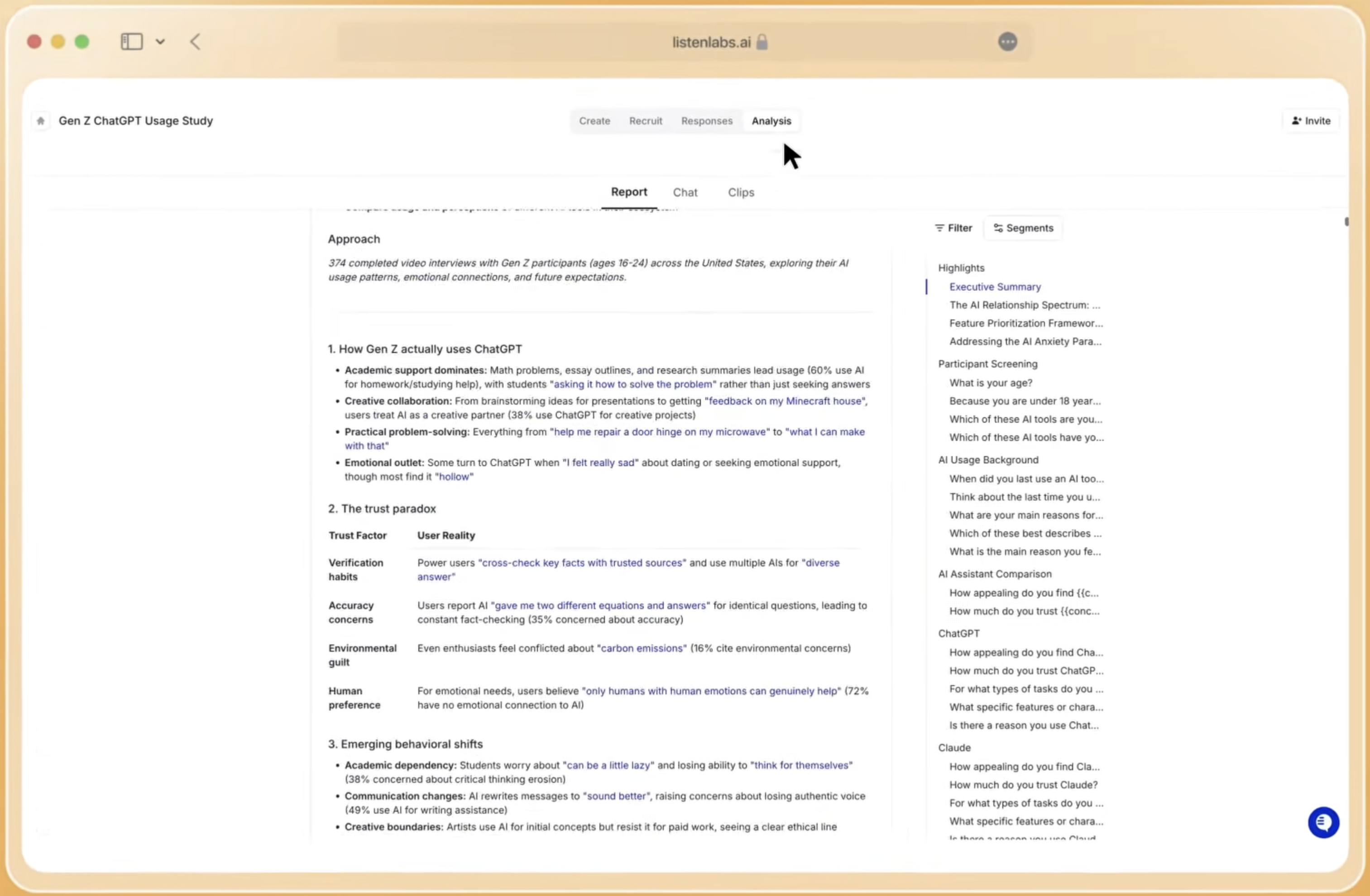
Task-Specific Accuracy Ranges for AI Research Assistants
Accuracy in AI-assisted customer research varies by task type, audio quality, language, and domain training. Teams need a clear view of where AI performs reliably and where human oversight remains non-negotiable.
On transcription, AI tools in 2026 achieve 95–97% accuracy on clean studio audio and 85–94% on real-world audio. Sentiment and theme classification show similarly strong performance, with AI achieving high accuracy on three-class sentiment tasks. Root-cause and inductive analysis, however, tell a different story: a 2026 blinded study published in PLOS Digital Health examined how LLMs perform inductive thematic analysis of focus-group transcripts and revealed significant limitations in this more complex reasoning task. Specialized platforms that layer proprietary data and human research oversight over these base models outperform generic LLMs on every dimension that matters to enterprise insights leaders.
Reliability Profile of AI Research Assistants
Reliability depends on the architecture behind the tool. Generic LLMs and specialized enterprise platforms both rely on large language models, but the surrounding infrastructure determines whether outputs are trustworthy at scale.
As noted earlier, transcription accuracy varies significantly by audio quality. AI transcription services based on Whisper achieve roughly 88–92% accuracy on real-world English audio and exceed 97% only on clean benchmarks such as LibriSpeech test-clean. When teams add human review, accuracy improves further. Audio quality remains a major variable, with video conference recordings from professional setups outperforming field recordings with ambient noise.
Beyond transcription, theme extraction presents a different reliability profile. Topic and theme extraction models can achieve good precision on well-defined taxonomy categories in structured environments. However, models without domain-specific fine-tuning misclassify technical or industry-specific jargon more often than domain-trained models. Listen Labs addresses this directly through tens of thousands of completed studies that inform its analysis engine, creating a proprietary data moat that generic LLMs cannot access.
Hallucination rates further separate architectures. RAG-based AI systems with retrieval augmentation, confidence thresholds, and output validation drop hallucination rates below 2%, compared to 75–85% factual accuracy for LLMs without retrieval augmentation. The Connext Global 2026 AI Oversight Survey of 1,000 U.S. workers found that only 17% believe workplace AI is reliable without human oversight, and 70% define reliability as a hybrid model that combines AI with either light review or dedicated oversight.
AI and Customer Behavior Prediction
Behavior prediction accuracy depends on the decision being modeled and the quality of the underlying data. Standard, repeatable choices behave very differently from novel or disruptive behaviors.
BCG’s 2026 analysis found that synthetic panels trained on historical data predict real-world consumer choices with 92% accuracy when research outputs receive ongoing fine-tuning. That figure applies to standard choice scenarios with well-defined attributes. For radical innovations, new categories, or behaviors with no historical analog, synthetic panels face inherent limitations. They can overlook minority views and are susceptible to confirmation bias that pushes them to infer and artificially support researchers’ hypotheses.
Multiple studies show that LLMs struggle to replicate the diversity of genuine human behavior and should not substitute for real consumer responses. Listen Labs addresses this limitation through its network of 30 million verified respondents across 45+ countries. Instead of simulating behavior from training data, Listen Labs captures it directly through AI-moderated interviews with real participants, matched by behavioral and intent signals rather than self-reported demographics. The Robinhood engagement study illustrates this clearly. Qual interviews revealed that users who view prediction markets as entertainment rather than income drive 2.4x higher weekly re-engagement, a behavioral pattern that no synthetic panel could have surfaced.
Limits of AI for Root-Cause and Inductive Analysis
Root-cause analysis relies on inductive reasoning, moving from specific participant statements to underlying motivations without a predefined coding framework. Generic LLMs show their most significant limitations on this type of work.
The 2026 Hill et al. study in PLOS Digital Health, which compared ChatGPT-5, Claude 4 Sonnet, and QualiGPT against human analysts on a 12,172-word healthcare focus-group transcript, found comprehensive errors in inductive thematic analysis. The study concluded that low strict hallucination rates mask significant comprehensive errors. LLMs can therefore augment qualitative analysis but still require human verification for inductive tasks.
In deductive coding, where analysts apply a predefined framework to transcripts, LLMs achieved high mean agreement with expert consensus, comparable to blinded human analysts. This gap between deductive and inductive performance explains why generic LLMs work adequately for structured analysis but fall short when insights teams need to discover unexpected themes.
Listen Labs closes this gap through two mechanisms. Its analysis engine is trained on proprietary data from tens of thousands of completed studies, which calibrates its understanding of which patterns represent genuine signal versus noise. Its in-house research team, with 50+ years of combined expertise, reviews methodology continuously and ensures that inductive analysis outputs meet the standard of consultant-quality deliverables rather than raw LLM output.
Hallucination Risks in AI-Generated Customer Insights
Hallucination in qualitative research often appears as fabricated or recombined participant quotes. This matters because when an insights leader presents a finding to a product team or executive committee, the verbatim quote serves as the evidence supporting the recommendation. If that quote is synthesized, combining elements no participant actually said, the entire finding rests on fabricated data and crosses the line from minor error to fundamental breach of research integrity.
A 2025 study by Uintent documented that LLM thematic analyses often invented or recombined participant statements, requiring researchers to verify quotes against the source transcript. The problem can compound in long conversations because one early error may propagate through the entire analysis.
At the model level, on the HalluHard benchmark developed by EPFL and ELLIS researchers, even the strongest tested configuration, Claude-Opus-4.5 with web search, hallucinated approximately 30% of the time on multi-turn conversations requiring inline citations. For enterprise insights teams, this error rate is unacceptable for any research output that informs product, brand, or go-to-market decisions.
Mitigation Strategies and Quality Controls That Actually Work
Effective hallucination mitigation in AI-assisted research requires structural controls, not just prompt tweaks. Decision accuracy improves with validation. That difference separates research that drives confident decisions from research that creates liability.
Listen Labs embeds mitigation at every layer of its platform. Quality Guard monitors every interview in real time across video, voice, content, and device signals, detecting fraud, low-effort responses, AI-generated scripts, and mismatched profiles before they contaminate the dataset. Participant frequency limits of no more than three studies per month per participant remove professional survey-takers whose incentive-driven responses introduce systematic bias. Behavioral matching through Listen Atlas pairs participants to studies based on intent and past actions rather than self-reported demographics, so the sample reflects the actual population of interest.
Every emotion label and verbatim quote in Listen Labs’ outputs is traceable to the exact timestamp and source segment, which makes verification immediate instead of a time-consuming manual process. The in-house research team, with 50+ years of combined expertise, reviews methodology continuously, providing the human oversight layer that enterprise workers consistently identify as essential for AI reliability.
Capturing the Gap Between What People Say and What They Feel
Transcripts capture words but not the hesitation before a positive answer or the microexpression of confusion during a concept reveal. They also miss the flat affect that separates polite agreement from genuine enthusiasm. For creative testing, concept comparison, and brand research, this gap between stated and felt response often contains the most actionable insight.
Nuanced emotion detection beyond basic positive and negative sentiment can achieve 85% accuracy with fine-tuned BERT on datasets like GoEmotions. Generic tools that operate on transcripts alone cannot access the multimodal signals such as tone of voice, word choice, and facial microexpressions that distinguish surface-level sentiment from genuine emotional response.
A 2026 arXiv study found that six frontier LLMs expressed engaging emotions more than disengaging ones when simulating human behavior, failing to capture the diversity of human social emotion responses across cultures. This systematic bias makes generic LLM emotion outputs unreliable for cross-cultural research programs.
Listen Labs’ Emotional Intelligence layer addresses this gap through multimodal signal analysis built on Ekman’s universal emotions framework, the same standard used in clinical psychology and UX research. Every emotion is quantified per question and concept, traceable to the exact timestamp, verbatim quote, and reasoning behind the classification. The system operates across 50+ languages and integrates directly with the Research Agent, enabling natural-language queries like “which concept triggered the most confusion in the 35–44 female segment” and returning timestamped highlight reels of the relevant moments.
Specialized Enterprise AI Platforms vs. Generic LLMs
The performance gap between specialized enterprise platforms and generic LLMs widens as research complexity increases. On simple transcription and deductive coding, the gap remains manageable. On inductive analysis, emotional intelligence, participant quality, and cross-study knowledge, it becomes decisive.
Speed favors both approaches over traditional methods, but Listen Labs delivers results in under 24 hours with a complete research lifecycle that covers study design, recruitment, moderation, analysis, and deliverables. Generic LLMs require separate tools for each step, which recreates the fragmentation that makes traditional research slow. Cost lands at roughly one-third of traditional agency rates. Sample quality differs structurally. Listen Labs’ 30 million verified respondents, matched by behavioral signals with a zero-fraud guarantee, cannot be replicated by prompting a generic LLM with a persona description.
LLMs exhibit instability in behavioral simulation and complex analyses, with model-generated data often diverging significantly from conclusions of original empirical studies, sometimes producing effects in the opposite direction. Listen Labs’ Mission Control compounds advantage over time. Every completed study grows the cross-study knowledge base, enabling trend tracking and institutional knowledge building that generic LLMs, which have no memory of past studies, cannot provide.
Specialized Enterprise AI Platforms vs. Traditional Research Agencies
Traditional research agencies deliver high-quality work, but the structural economics of human-dependent moderation, manual analysis, and sequential workflows cap speed and scale. No amount of talent fully overcomes those constraints.
Microsoft’s insights team cut research wait time from weeks to hours using Listen Labs, collecting global customer stories for the company’s 50th anniversary within a single day. The Director of Data Science at Microsoft noted, “I can reach out to hundreds of users at one third of the cost.” Anthropic’s Claude Code team ran 300+ user interviews in 48 hours to surface churn drivers, identified where former users migrate, and delivered a prioritized list of must-fix items, a process that would have taken a traditional agency 4–6 weeks. P&G used Listen Labs to evaluate how men respond to new product claims across 250+ interviews with quantified themes and verbatim proof, shaping product and brand strategy in hours rather than weeks. Skims validated campaign direction with thousands of high-income buyers overnight and secured board-level buy-in before launch.
Consistency adds another advantage. Human moderators vary in skill, energy, and adherence to discussion guides. In 4,180 completed AI-moderated sessions, AI moderators asked an average of 11.7 clarifying or probing follow-ups per session, 3.2x more than the 3.6 benchmark for human-led 30-minute sessions. Every participant receives the same depth of probing, which removes the moderator variability that introduces bias in traditional qualitative research.
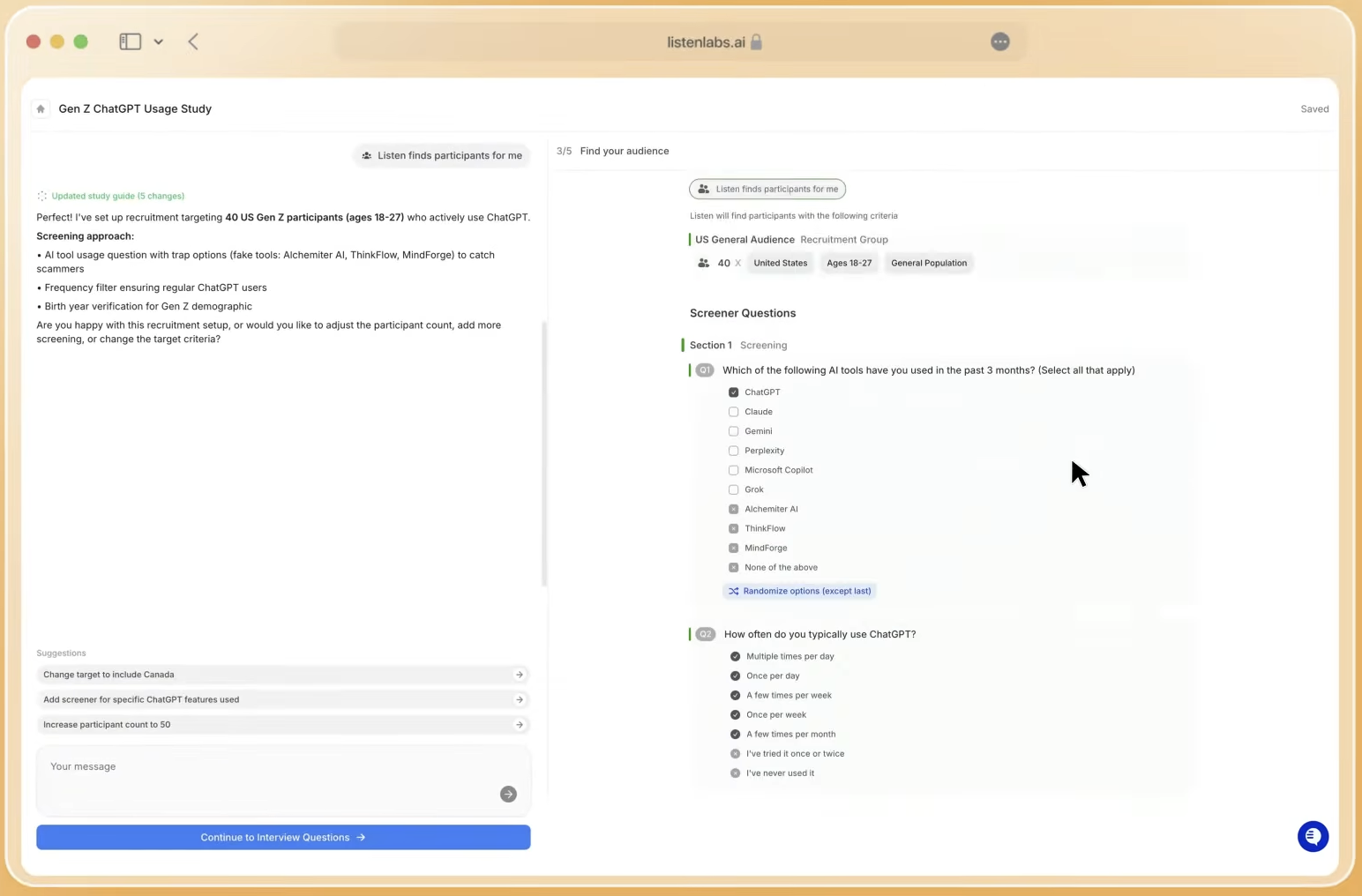
Decision Framework: Matching Research Goals to the Right Approach
The right research approach depends on timeline, risk tolerance, sample requirements, and the type of insight needed. Enterprise insights teams can use these factors to choose confidently among specialized AI platforms, synthetic panels, and traditional methods.
When the timeline is under 24 hours and the research objective involves concept testing, churn analysis, brand perception, creative testing, or consumer journey mapping, a specialized AI platform fits best. When the research explores radical innovations with no behavioral analog in existing data, synthetic panels should remain subordinate to real-participant interviews. BCG recommends a tiered decision framework, where low-risk decisions such as ideation can use synthetic panels as primary research, while high-risk decisions such as regulated claims or forecasting keep them subordinate to human testing.
When the audience is niche, such as enterprise decision-makers, healthcare workers, or consumers below 1% incidence rate, a platform with dedicated recruitment operations and a verified respondent network becomes necessary. Generic LLMs and commodity panels cannot reliably reach these segments. When cross-study knowledge and trend tracking are organizational priorities, a platform with persistent institutional memory like Mission Control outperforms any combination of point solutions.
Frequently Asked Questions
How long does Listen Labs take to deliver results?
Listen Labs compresses the entire research lifecycle, including study design, participant recruitment, AI-moderated interviews, analysis, and deliverable generation, to under 24 hours. Traditional qualitative research cycles run 4–6 weeks, and in enterprise settings with internal prioritization and budget approval, the process can stretch to six months. Listen Labs removes each of those bottlenecks through AI-assisted study design, automated recruitment from its 30 million verified respondents, simultaneous AI-moderated interviews, and one-click generation of slide decks, memos, video highlight reels, and statistical charts.
How does Listen Labs ensure participant quality?
Listen Labs applies three layers of quality control. It works exclusively with high-quality, non-commodity panel sources, avoiding professional survey-takers and incentive-optimized respondents. Quality Guard then monitors every interview in real time across video, voice, content, and device signals, detecting fraud, low-effort responses, AI-generated scripts, and mismatched profiles before they enter the dataset. Participants are limited to three studies per month, which eliminates panel fatigue and repeat-respondent bias. For hard-to-reach segments such as enterprise decision-makers, engineers, healthcare workers, and consumers below 1% incidence rate, a dedicated recruitment operations team partners with niche communities and specialized networks to source exactly the right participants. Organizations can also self-recruit from their own user base at reduced cost.
What security certifications does Listen Labs hold?
Listen Labs maintains enterprise-grade security with 256-bit encryption, and customer data is never used for AI model training. The platform holds SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. Enterprise SSO is supported. These certifications cover data protection, privacy management, and AI management system standards, keeping Listen Labs aligned with the requirements of Fortune 500 procurement and legal teams across the Americas, Europe, APAC, and MEA.
Can Listen Labs reach niche audiences or support self-recruitment?
Listen Labs supports both niche recruitment and self-recruitment. The dedicated recruitment operations team sources audiences below 1% incidence rate, including enterprise decision-makers, engineers, healthcare workers, and highly specialized consumer segments, by partnering with niche communities, micro-creators, and specialized networks. The platform’s AI orchestration layer, Listen Atlas, automatically matches and bids across multiple consumer and B2B panel partners as well as Listen Labs’ proprietary database of 30 million verified respondents across 45+ countries. For organizations that want to study their own user base, Listen Labs supports self-recruitment at reduced credit cost, with the same Quality Guard controls applied to self-sourced participants.
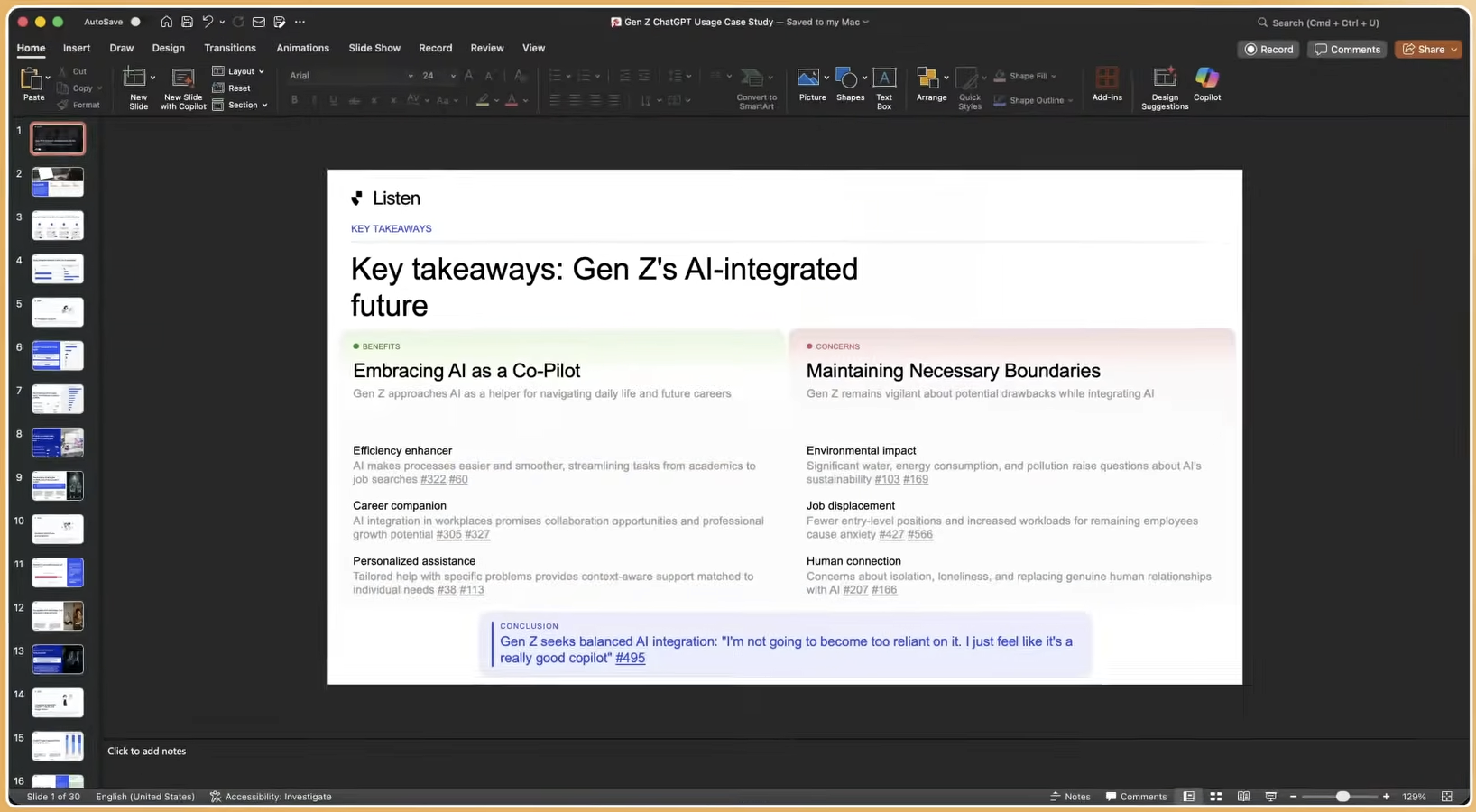
Conclusion: Choosing Accuracy at Scale
AI research assistants deliver strong value on transcription, deductive coding, and sentiment classification, where 85–92% accuracy is achievable and well documented. They fall short on inductive root-cause analysis, emotional nuance, cross-cultural behavioral prediction, and any task where participant quality determines the validity of the output. Generic LLMs compound these limitations with hallucination risks that remain difficult to control without proprietary data, real-time quality controls, and human research oversight.
Listen Labs is built for enterprise insights teams that refuse to trade accuracy for speed or depth for scale. Its 30 million verified respondents, Quality Guard fraud controls, Ekman-based Emotional Intelligence layer, and 50+ years of in-house research expertise combine into a platform that delivers what generic tools cannot. Teams receive consultant-quality qualitative insights in under 24 hours, at one-third the cost of traditional agencies, with every finding traceable to its source.
Microsoft, Anthropic, P&G, Skims, and Robinhood have already made this shift. For insights leaders managing growing backlogs and compressed timelines, the real decision is not whether AI can assist with customer research. The decision is whether the platform behind that AI meets the standard that enterprise decisions require.


