
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways
- Most AI market research mistakes in 2026 come from treating LLMs as replacements for real participants instead of tools that scale genuine conversations.
- Common errors include using synthetic respondents, ignoring emotional context, running linear moderators, and skipping validation guardrails, which all create flawed strategy and wasted budget.
- Effective AI research relies on verified human participants, quote-level traceability, adaptive probing, and behavioral matching so data quality and credibility hold up under scrutiny.
- Platforms that pair AI moderation speed with real participants and multimodal analysis deliver faster timelines and trustworthy insights while meeting enterprise governance standards.
- Listen Labs helps teams avoid these pitfalls by combining AI speed with verified human participants — see how our platform prevents these mistakes.
The Problem: Why AI Market Research Mistakes Derail Strategy
Enterprise research teams now need continuous customer intelligence, not occasional quarterly reports. Many teams have reacted by routing entire workflows through general-purpose LLMs, generating synthetic personas, summarizing fabricated interviews, and treating model outputs as market truth. The result is a new category of budget waste: studies that move fast but answer the wrong question, or answer the right question with invented data. AI-moderated platforms that integrate the full workflow can compress research timelines from weeks to hours, but only when real participants anchor the data. Without that anchor, speed turns into a liability.
See Listen Labs’ verified participant network across 45+ countries.
10 Common AI Market Research Mistakes
The following mistakes show the most common ways organizations waste budget and compromise data quality when they roll out AI research programs. Each mistake includes the core problem and a practical way to fix it.
Mistake 1: Using Synthetic Respondents as a Proxy for Real Participants
Synthetic respondents in market research are LLM-generated profiles that simulate how a customer segment might respond. They are fast to produce and cost nothing to recruit, but they are not real. Synthetic outputs mirror the model’s training distribution, not the lived experience of your actual customer. When a CPG brand uses synthetic respondents to test a new product claim, it measures what the internet has said about similar products, not what its buyers actually feel. Strategy fails in the gap between those two realities.
How to Fix It: Anchor every study in verified human participants matched to your target segment by behavioral and intent signals, not just self-reported demographics. Real-time quality controls should screen for fraud, low-effort responses, and mismatched profiles before any response enters analysis.
Mistake 2: Treating AI Outputs as Facts in Market Research
Treating AI outputs as facts in market research sends strategy in the wrong direction. A financial services firm used an LLM to summarize a market research report and received fabricated statistical data presented as factual information. In the same category, hallucinations in business LLM applications can lead to misguided investment decisions costing firms millions of dollars. In market research, this failure mode produces product roadmaps built on invented preferences and brand strategies tuned to audiences that do not exist.
How to Fix It: Require every AI-generated insight to trace back to a source quote, a video timestamp, and the reasoning behind the label. AI-generated insights that stand alone as summaries without links to source quotes or video moments create a credibility gap when stakeholders challenge findings during executive reviews. Treat quote-level traceability as a non-negotiable output standard.
Mistake 3: Replacing Customer Interviews with AI
Replacing customer interviews with AI by swapping real conversations for LLM-generated simulations removes the only irreplaceable element in qualitative research: the participant. Research comparing AI-moderated to human-moderated sessions consistently finds participants share more candidly with AI, which strongly supports AI moderation. It does not support eliminating participants. The distinction matters. AI should moderate the conversation, not replace the person having it.
How to Fix It: Deploy AI as the moderator, not the respondent. AI can schedule and conduct the interview, analyze transcripts for themes, and generate quantitative insights from those interviews. Throughout that process, the participant remains a verified human whose responses reflect genuine experience.
Mistake 4: Ignoring Emotional Context in AI Research
Ignoring emotional context in AI research produces data that captures what people say but misses what they feel. Research shows that AI-generated and AI-mediated outputs often convey functional and informational meaning more effectively than emotionally resonant meaning. AI sentiment models also struggle with sarcasm, irony, metaphor, and cultural nuance, producing classification errors especially for short or ambiguous statements. Two concepts can receive identical positive ratings while triggering entirely different emotional responses. Only multimodal analysis surfaces that difference.
How to Fix It: Use multimodal models that analyze voice, language, and facial signals together at the response level. Require every emotional label to connect to a specific quote and timestamp so teams can review the exact moment that drove the classification.
Mistake 5: AI Market Research Hallucinations Without Validation Guardrails
AI market research hallucinations occur when models generate plausible-sounding but factually unsupported findings. The risk increases when LLMs synthesize large volumes of interview data without structured validation. An audit and verification step after initial AI coding catches contradictions, overexaggerated intensity ratings, and miscoded responses that would otherwise distort emotional nuance in research findings. Without that step, hallucinated themes slip into the deliverable and shape decisions downstream.
How to Fix It: Build validation into the analysis pipeline as a structural requirement, not a post-hoc option. When validation operates as part of the core workflow, statistical significance testing, segment comparison, and source-linked verbatims are generated automatically alongside every finding. This approach prevents teams from skipping validation under deadline pressure and keeps unsupported insights out of executive decks.
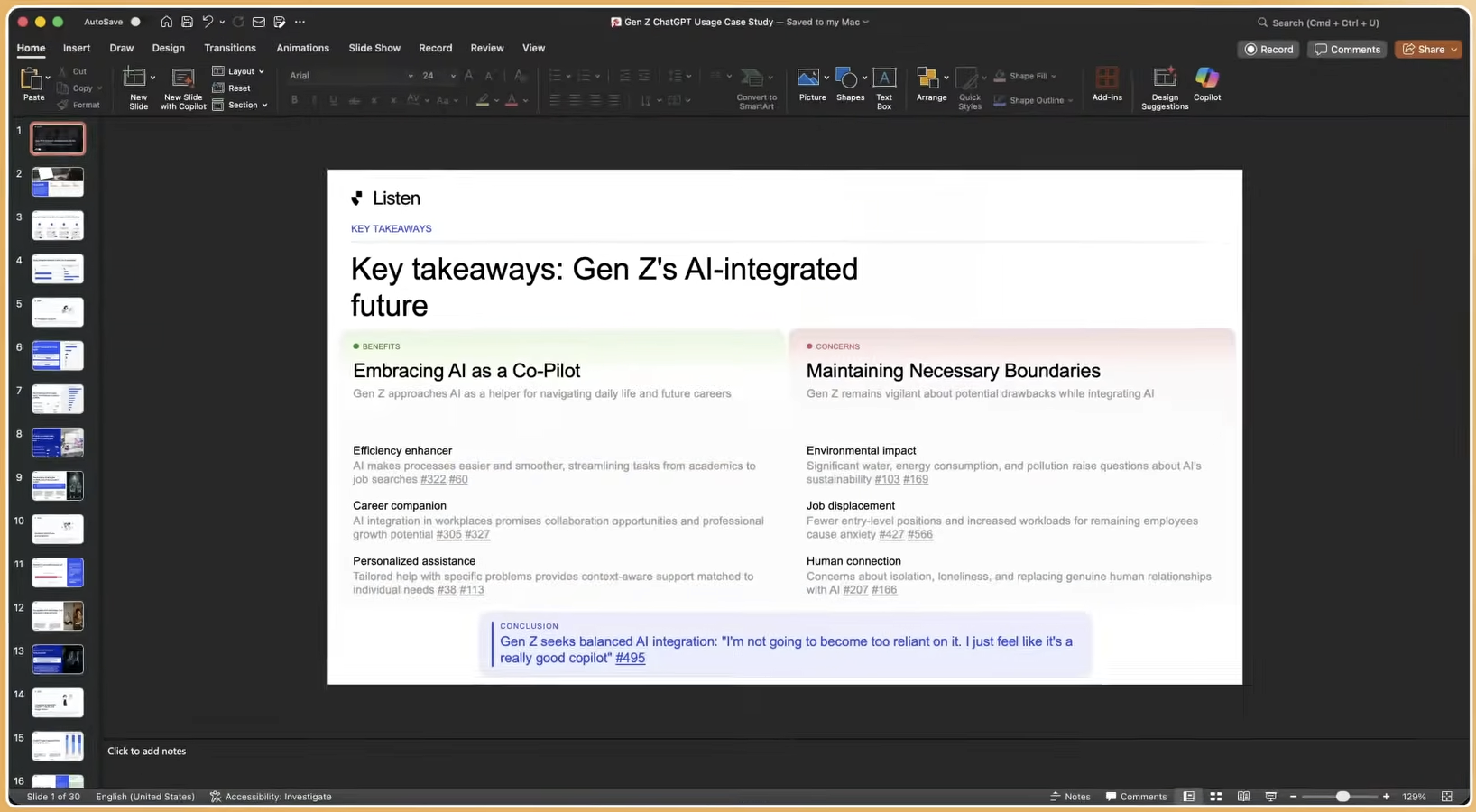
Mistake 6: Using AI Research Prompts Without Methodological Structure
AI research prompts mistakes appear when teams treat prompt engineering as a replacement for study design. Asking an LLM to “find the key themes in these transcripts” without defining coding frameworks, emotional intensity scales, or segment parameters produces inconsistent output. Without explicit definitions for quotes, ratings, and emotional intensity levels, AI models produce inconsistent results that fail to preserve contextual intent in customer responses.
How to Fix It: Let study design come before prompt construction. AI-assisted study co-design, where the platform drafts structured objectives, question types, and probing context based on stated research goals, produces more reliable downstream analysis than ad hoc prompting against raw transcripts.
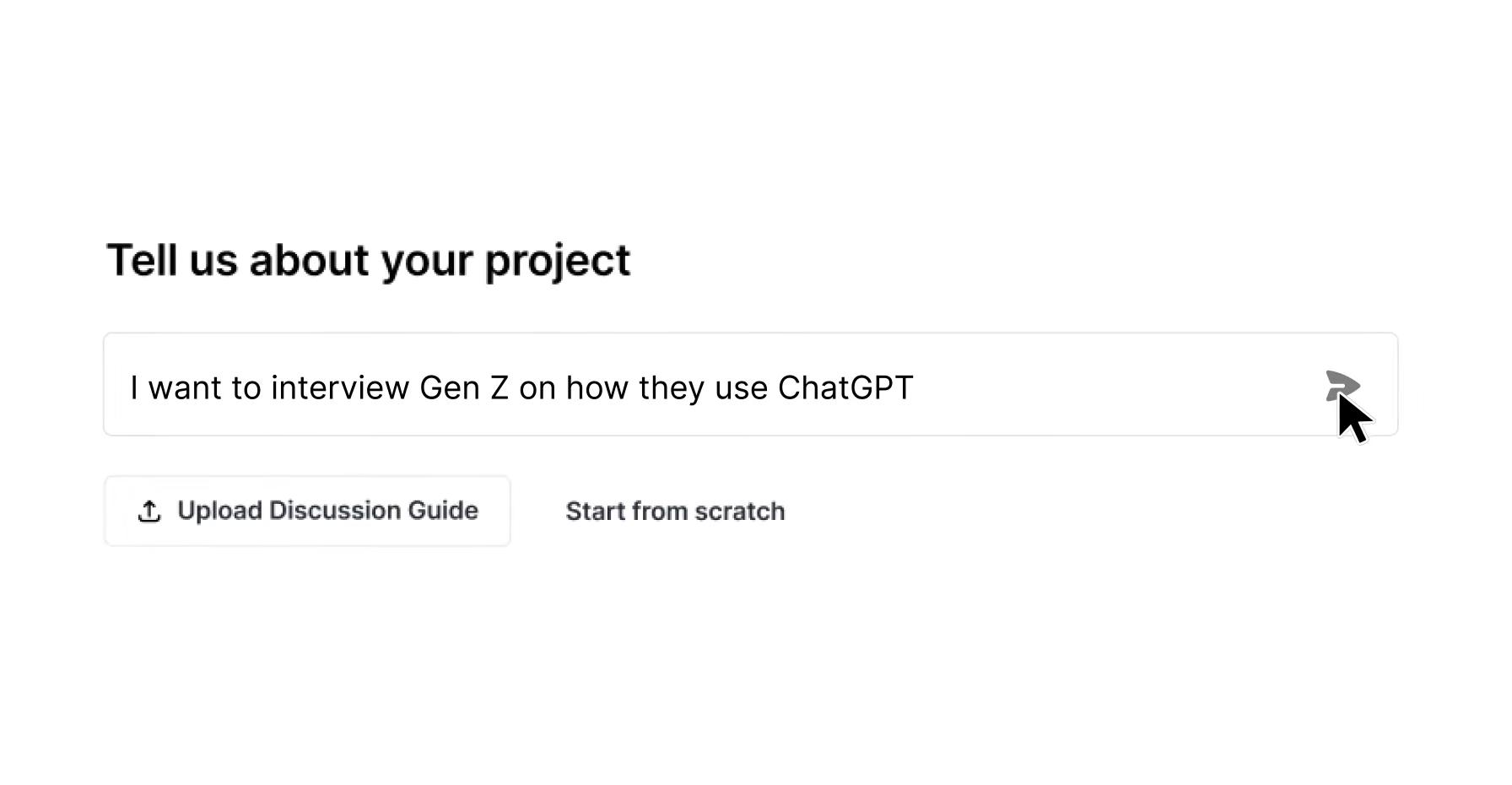
Mistake 7: Running Linear AI Moderators That Cannot Probe
A fixed-script AI moderator that advances through questions regardless of participant responses behaves like a survey with a conversational interface. AI moderators that run linearly through a fixed script instead of using adaptive probing in response to short or off-topic answers generate shallow, less substantive participant responses. The depth that justifies qualitative research, such as unexpected admissions or hesitations before answering, only appears when the moderator listens and responds.
How to Fix It: Use AI moderation platforms that make real-time decisions about whether to probe deeper, request clarification, or advance, based on the content of each individual response. With AI-moderated interviews, talking to users at scale is no longer the hard part, while the challenge becomes understanding what they mean.
Watch adaptive AI moderation handle hundreds of simultaneous interviews.
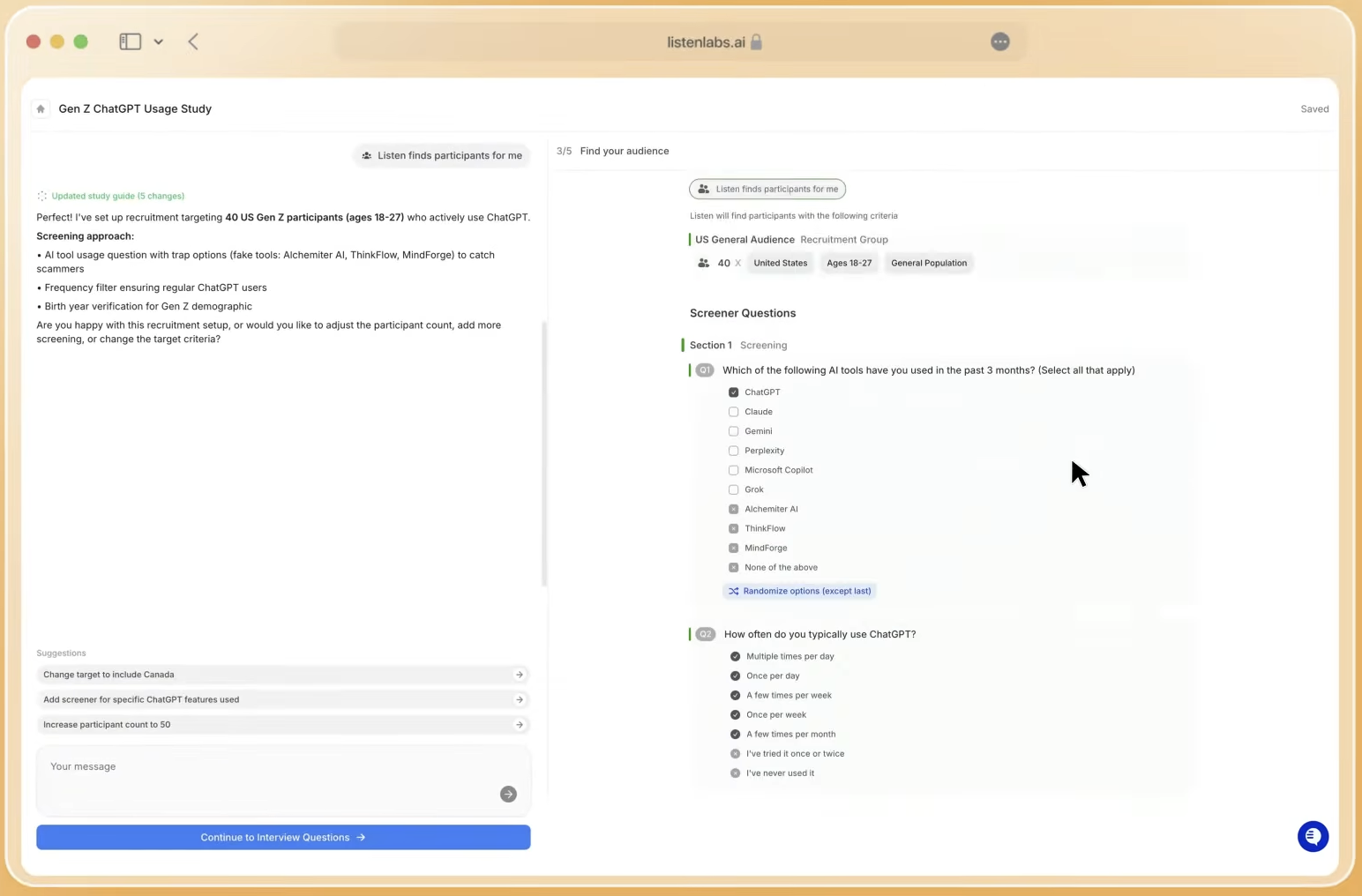
Mistake 8: Ignoring AI Market Research Bias in Participant Sourcing
AI market research bias starts with recruitment, not only with modeling. Commodity panels filled with professional survey-takers, repeat respondents, and incentive-optimizing participants introduce systematic bias before the first question. Research platforms lacking verified participant panels and real-time fraud detection produce invalid data because bad participants generate unreliable responses that undermine study validity. In addition, emotion recognition performance varies across cultures, genders, and languages, which becomes a concrete limitation when sourcing participants from undifferentiated global panels without behavioral matching.
How to Fix It: Run participant matching on behavioral and intent data, not only on self-reported demographics. Combine real-time quality monitoring across video, voice, content, and device signals with participant frequency limits to remove the professional survey-taker problem at the source.
Mistake 9: Failing to Validate AI Market Research Against Business Objectives
Validating AI market research against the original business question often gets skipped when AI generates findings quickly. Speed creates a false sense of completeness that hides gaps in relevance. HBR notes that AI moderation is still in its infancy, requiring establishment of key metrics such as test-retest reliability and external validity before widespread adoption. A study that answers a well-formed question quickly creates value. A study that answers the wrong question quickly creates expensive noise.
How to Fix It: Tie every study to a defined decision such as a product bet, a campaign direction, or a pricing hypothesis. AI-assisted study design should map research objectives to question types and sample sizes before recruitment begins, not after results arrive.
Mistake 10: Treating Studies as Standalone Artifacts Instead of Building Institutional Knowledge
Organizations that run individual studies without feeding findings into a searchable knowledge base end up re-researching the same questions. Organizations that treat each study as a standalone artifact rather than building a cross-study searchable knowledge base must restart synthesis and insight generation from zero with every new project. In a continuous customer-intelligence model, this pattern becomes a structural failure that compounds with every study cycle.
How to Fix It: Route every completed study into a persistent, queryable knowledge base that supports cross-study trend tracking, segment comparison over time, and instant retrieval of past findings. Institutional knowledge should accumulate, not evaporate.
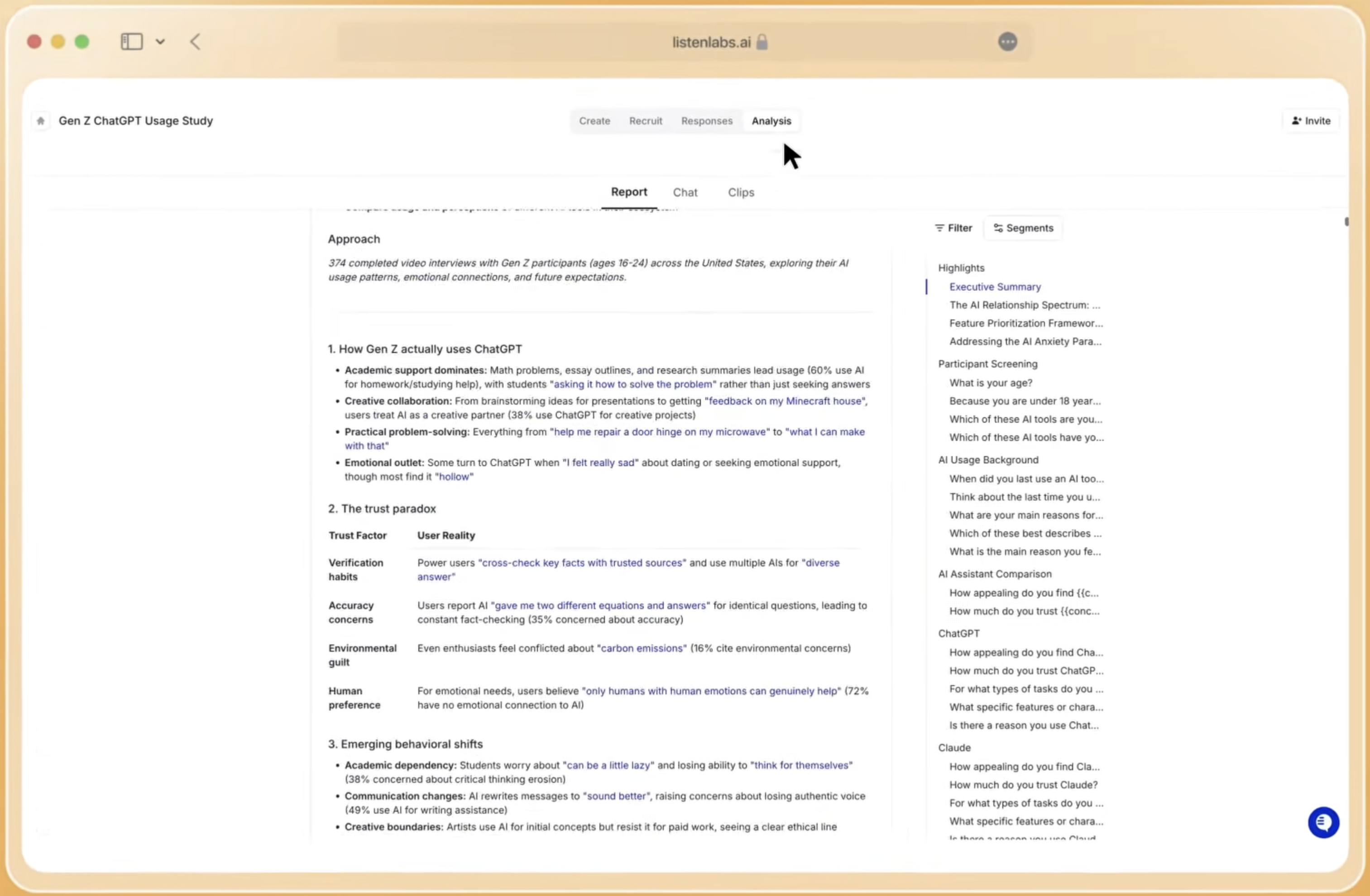
AI vs Human Market Research: A Neutral Comparison
These ten mistakes make more sense when viewed against the available research approaches and their trade-offs. The comparison below shows where each method performs well and where it tends to create the problems described above.
Each approach to market research carries distinct trade-offs across speed, depth, cost, and reliability:
- Pure LLM approaches (no real participants): Fast and low-cost for generating hypotheses or drafting study guides. Produce synthetic outputs that reflect training data, not real customer behavior. No participant verification, no emotional signal capture, and no governance trail. Hallucination risk runs high when teams use these outputs for insight generation without source data.
- Traditional research agencies: Traditional qualitative research cycles take 3–5 weeks and can cost $4,000–$12,000 per 90-minute session. Well-resourced projects deliver strong methodological rigor. These cycles rarely scale for continuous intelligence programs. Analysis remains manual, subjective, and vulnerable to confirmation bias.
- Quantitative survey tools: Scalable and cost-efficient for structured data collection. Provide no adaptive follow-up, no probing, and limited ability to surface unexpected findings. Capture what participants select, not what they mean. Qualitative methods make up for their limitations in speed and sample size tenfold in their ability to uncover nuance and complexity in human decision-making.
- End-to-end AI interview platforms with verified participants: Combine the candor advantage noted earlier with adaptive probing that surfaces depth at scale. Multimodal emotional analysis captures signals beyond transcripts. Verified participant networks with real-time fraud detection protect data quality. A single platform covers the full research lifecycle, including design, recruitment, moderation, analysis, and delivery. SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 compliance satisfies enterprise governance requirements.
Frequently Asked Questions
What is the difference between AI market research hallucinations and normal analytical error?
Hallucinations describe a failure mode where an AI model generates plausible-sounding findings with no basis in the source data, such as invented statistics, fabricated themes, or attributed quotes that do not exist. Normal analytical error involves misinterpretation of real data. Hallucinations are more dangerous because they look identical to accurate outputs unless teams check source-level traceability. The mitigation remains the same in both cases: every finding must link to a specific participant response, timestamp, or verbatim quote before it enters a deliverable.
Can synthetic respondents ever be used responsibly in market research?
Synthetic respondents have a narrow legitimate use for early-stage hypothesis generation, stress-testing a discussion guide, or exploring question framing before a live study launches. They do not replace real participant data in any study that will inform product, brand, or investment decisions. The moment synthetic outputs are treated as consumer truth, the research loses validity. Any use of synthetic respondents should be clearly labeled, kept separate from real participant data, and excluded from final deliverables.
How do you capture emotional context in AI-moderated research without a human moderator in the room?
Emotional context in AI-moderated research comes from multimodal signal analysis that evaluates tone of voice, word choice, and facial micro-expressions together at the response level. This approach, grounded in frameworks like Ekman’s universal emotions model, quantifies emotional signals per question and concept with timestamp-level precision. Every emotional label must trace back to the exact moment and verbatim quote that generated it, rather than relying on aggregate sentiment scoring that flattens meaningful gradations in response tone.
What governance and compliance requirements apply to enterprise AI market research programs?
Enterprise AI research programs that operate across multiple markets face overlapping compliance obligations. Data security requires encryption at rest and in transit, along with explicit prohibitions on using participant data for AI model training. Privacy compliance requires alignment with GDPR for European participants and equivalent frameworks in other regions. AI-specific governance increasingly relies on standards such as ISO 42001. Platforms handling enterprise research data should hold SOC 2 Type II, ISO 27001, ISO 27701, and ISO 42001 certifications as baseline requirements, not differentiators.
How many participants are needed for AI-moderated qualitative research to be statistically meaningful?
Traditional qualitative research typically uses 5–15 participants per segment because human moderation cannot scale further within budget. AI moderation removes that constraint and supports hundreds of interviews per segment simultaneously. At that scale, qualitative depth and quantitative confidence coexist: teams can quantify themes, test segment differences for statistical significance, and detect outlier patterns that would remain invisible in a 10-person study. The practical minimum depends on the number of segments and the precision required for the decision, but AI-moderated platforms can routinely deliver around 50 interviews per study within 24 hours, with some reaching 50–100 in parallel or higher totals over 48 hours.
Conclusion: Pair AI Speed with Human Truth
Every mistake on this list traces back to the same structural error: removing real human participants from the research process and expecting AI to compensate. AI moderation, AI analysis, and AI-assisted study design now compress weeks into hours and remove manual bottlenecks. These capabilities act as infrastructure for conversations with real people, not replacements for those conversations. The old trade-off between depth and scale is no longer a barrier when AI moderates real interviews at scale, captures multimodal emotional signals, and delivers traceable, consultant-quality findings. That model pairs speed with truth at enterprise scale.
See how we deliver compliant, emotionally intelligent research in under 24 hours.


