ENGINEERING
Reverse Engineering PowerPoint's XML to Build a Slide Generator
A PowerPoint Odyssey: Building a Better Slide Generator, 5036 pages later
Making PowerPoint presentations is much harder than it seems. While there are several LLM-powered slide generators out there, none of them produce truly satisfying results.
I set out to build a better one, and this article will walk you through that journey—from wrestling with the 5,036-page Office Open XML documentation to perfecting image formatting with rounded corners.
For context: I'm an engineer at Listen, where we've built an AI that conducts user interviews. We quickly learned that collecting data wasn't enough—it needed to be analyzed and presented, often in slide format. Since our focus was specifically on customer research insights, I thought building a specialized slide generator would be relatively straightforward.
I gave myself three weeks to build it end-to-end by myself but it turned out to be much harder than I thought.

The PowerPoint Maze
To ultimately generate PowerPoint presentations, I had to understand how they work. Luckily, Microsoft specified the format in the Office Open XML standard (a mere 5036 pages…). In case that hasn’t yet made it into your reading rotation, here’s a brief overview of how .pptx files work:
A .pptx is just a zip file with a bunch of XML files inside (plus your images and other media).
Try it yourself: unzip pres.pptx
There is one XML file for each slide, chart, speaker note, theme, master slide, slide layout, etc. While it is, in theory, “just XML”, it gets quite complicated with the XML files referencing each other arbitrarily (of course, in reality, in a very well-defined way). In fact, it’s complicated enough to make PowerPoint Turing-complete (just with shapes and animations, no scripting!)
For example, this is the XML-subtree for a picture from a slideX.xml file:
You can, for example, see the tags for the picture <p:pic>, some non-visible picture properties <p:nvPicPr> that define the placeholder used, and the position of the picture defined in the transformation tag <a:xfrm>. The actual image is defined through the binary large image pointer <a:blip> with ID “rId5”. This references an entry in another XML file that belongs to that slide – slideX.xml.rel:
This is where the actual image’s path is specified as "../media/image41.png".
Generating the deck
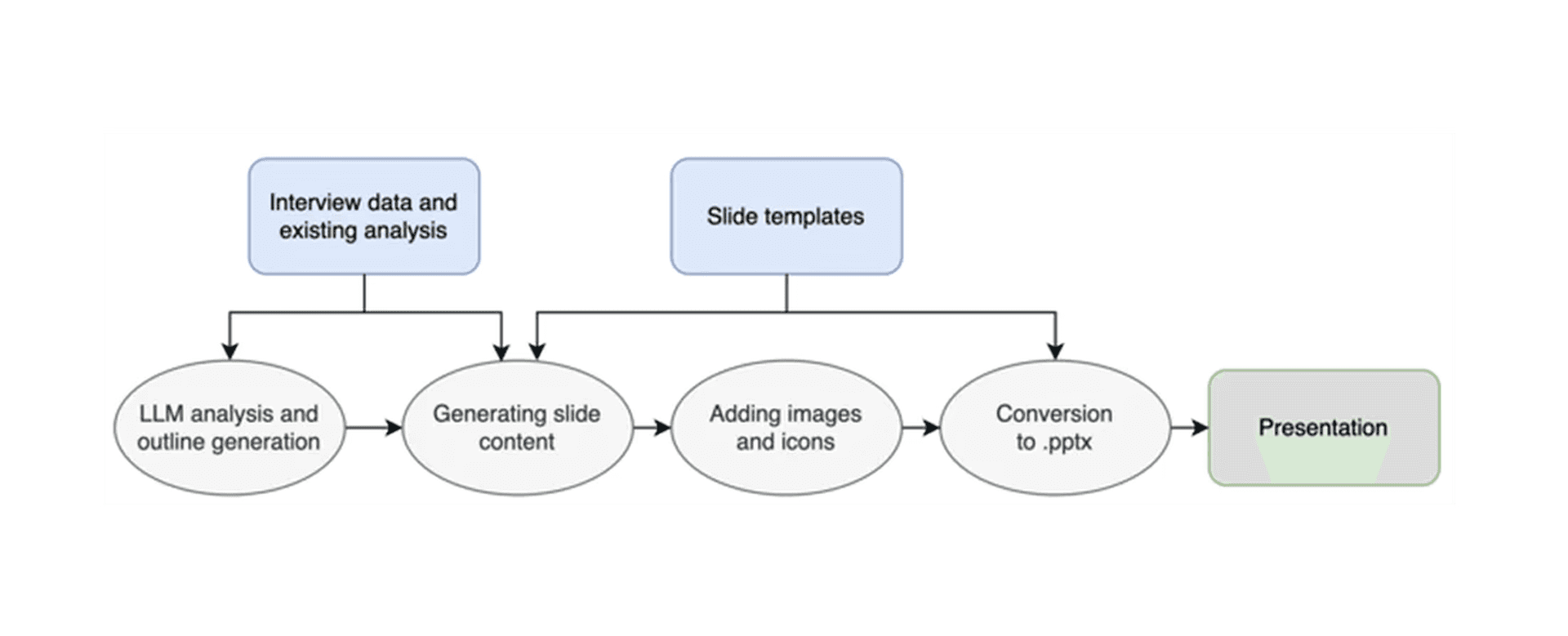
The simplest way to generate the PowerPoint would be to have the LLM write out the XML. But that “solution,” besides being incredibly inefficient (the entropy of the whole XML is not that high after all), overlooks the capacity of current LLMs. They aren’t good enough to write this consistently (note: written in 01/2025, let’s see how well this sentence ages).
My game plan was to design PowerPoint templates for our specific use case (or rather ask our designer since he’s much better). For every new presentation, the LLM then first generates a cohesive storyline from our existing analysis dashboard data. Afterward, the LLM selects the right template for each slide and creates the appropriate content. The last step is using the LLM output and converting it to a .pptx file.
But this last step turned out to be more complicated than I anticipated.
The rest of our product is written in typescript, so my first thought was that I could use PptsGenJS to create the slides. While it’s the biggest library, it’s still missing features; the dealbreaker was that it’s not possible to load existing .pptx files. Without that ability, the coordinates of every object would have to be coded, making it unreasonably cumbersome to create really good-looking slides.
I searched everywhere, but there wasn’t a single library that had all the functionality I needed. I ended up going with python-pptx, since it seemed to be the best of imperfect options. As you can guess from the name, it’s a Python library. It was a bit inconvenient to integrate with the existing typescript stack, but it was worth the effort. At Listen, we believe in using the best tool for a task instead of sticking with one language just for the sake of it.
Python-pptx issues
Even python-pptx, while being by far the best library for this task, still did not support all the features I needed. And who can blame them? It’s an insanely long standard.
For example, it doesn’t support copying of slides. Seems like a straightforward feature, right? Just copying the slide XML file? But since each slide references global objects (like images, charts, and even simple links), copying requires duplicating all these referenced objects as well. This can easily break things if some objects are not copied correctly, which is probably why the authors decided not to implement it. To get around this for our more constrained use case, I implemented a custom slide copying function.
Most PowerPoint presentations are ugly as hell, and we can’t be responsible for putting more ugliness into the world. One example is borders, specifically rounded borders on images (highly recommend reading this story from Andy Hertz about Steve Jobs’ obsession with rounded borders). Square borders are painful to look at, but python-pptx didn’t allow us to generate anything else.
(Spoiler alert: here's a sneak peek of the final product - but for now, just focus on those borders)
 |  |
What python-pptx gives you | What Steve Jobs would have wanted |
Luckily, this is pretty straightforward as soon as you know where to put the right XML tags. A simple
sets the right geometry, and adds some adjustment value for the border radius (measured as 10⁵ = 100% of the smaller side).
Another seemingly basic feature missing from python-pptx was the ability to change link colors. You can change the color of all links (by changing the slide theme) but why not individual links? Doing it in the PowerPoint UI makes it look very straightforward…
To implement this myself, I looked at the XML generated by PowerPoint:
But trying to look up the <ahyp:hlinkClr> tag in the specification, I couldn’t find it.
Notice the <a:extLst> subtree? It specifies the <a:ext> extension with ID A12FA001-AC4F-418D-AE19-62706E023703. Turns out Microsoft uses extensions to their own format. It seems like in the 5096 pages of specs, the Microsoft engineers forgot to add a way to color the link, so they had to add this incredibly cumbersome extension. This can then be used for the actual tag <ahyp:hlinkClr> — which specifies the val=”tx” – instructing it to use the text color defined for that run instead of the link theme color.
There were a lot of other issues (like missing features for styling charts, copying of which is ofc not supported by python-pptx… in fact, styling charts is not even properly supported by the official PowerPoint-online), but I was able to find similar workarounds eventually. Actually, once you get the hang of it, writing PowerPoint XML files by hand feels like markdown.
Well…maybe not quite ;) haha
Generating content
Layout and formatting are nice, but they only create more of a headache for our customers if they feel like they need to change all the content. If the content doesn’t make sense or the storyline feels off, they’ll need to change all the slides, defeating the purpose of generating things to begin with. That makes this the most important part to get right.
In certain areas, we could build on top of our existing analysis pipeline. It automatically extracts and quantifies themes and gives qualitative insights. I could also use existing code to reliably produce and cite quotes, iteratively checking them to make sure the LLM does not make stuff up (which we all know LLMs sometimes like to do…).
But having interesting content and insights is not enough for a good slide deck. A great slide deck has a clear storyline, clear action titles to guide the viewer, and details that go deeper into each insight. For the storyline, I used multi-step prompting techniques (some would call it agent…but why use a buzzword when you can just say what you mean). For the depth, I enabled the connection to customer quotes.
The last step was the images. Without visuals, presentations look dry. I actually feel like falling asleep when I stare at a presentation with no pictures. A presentation that puts people to sleep is definitely not what we’re going for.
I wanted two different styles of images:
Sketches to make overview slides look nice and
Stock-image-like pictures for content slides
To make the images look nice, I used different styles for different purposes and LORA-finetuned a diffusion model to create good results more consistently. For sketches, we ended up picking images out of an existing library of sketches since the image generation didn’t create good images consistently enough.
The end result
After three weeks of intensive work and many late nights, we finally had something to show for it. What started as a seemingly simple problem — generating slides — turned out to be far more complex and interesting than I had imagined.
In many respects, this is on par with or better than the slide decks we have seen from agencies:
It goes more into depth, providing vivid quotes and backlinks to our platform to watch the full interviews
The images are often of higher quality
The storyline is clear
And they’re much faster, available within minutes as the responses are collected instead of days or weeks.
Of course, it isn’t better in every respect. Naturally, our AI approach is a bit more constrained. For example, agencies sometimes create great custom graphics to illustrate a point or the central thesis/framework. Those things are not possible with AI…yet.
The AI slide decks are now our default deliverable for all studies – and our customers love them! Instead of looking through raw responses or using our analysis dashboard, many just review the slides to get their insights (along with watching highlight reels and using our Analysis Chat – but those are stories for another time).
Want to judge for yourself? Here are some of the slides we generated:
 |  |
 |  |
But this isn't the end. In fact, it’s just the beginning.
We’re now experimenting with generating the speaker notes for presentations. So far, they’re surprisingly good, and we envision a future that combines video, user interaction, and AI control for engaging presentations.
We’re also working on things like:
Real-time video understanding of UI interactions
Fraud detection algorithms of panel participants
Hypothesis testing/validation driven by reasoning models like o3-mini.
Through our partnerships with Google, OpenAI, and Anthropic, we also get early access to new models to play around with and integrate into our product.
If reading through this excited you and you’d like to work on similar problems, reach out to me at tobias@listenlabs.ai. We are always looking for passionate and smart engineers to join our team!