
Written by: Anish Rao, Head of Growth, Listen Labs
7 Ways This Playbook Clears Your Research Backlog
- Enterprise research teams face structural capacity limits. Traditional qualitative cycles take 4 to 6 weeks, queues grow, and synthesis debt erodes stakeholder trust.
- A 7-step framework using AI-powered intake, tiered self-service, and clear SLAs can cut backlog age within 30 days without adding headcount.
- Core moves include a full backlog audit, centralized intake with Definition of Ready criteria, daily triage, and a knowledge repository that clears synthesis debt.
- A tiered research model powered by AI routes requests across self-service, assisted, and full-service tiers based on complexity and strategic importance.
- Listen Labs helps teams compress full research cycles to under 24 hours. Book a demo to build your 30-day backlog reduction plan.
Why Reducing Research Backlog Protects Your Influence
A growing research backlog is not a scheduling inconvenience. It is a strategic liability. When product and brand teams wait weeks for answers, they make decisions without data or run shadow research that bypasses quality controls. Stakeholder trust in the research function erodes, and the team’s influence over key decisions shrinks.
This trust gap widens as organizations shift toward continuous customer intelligence programs that expect always-on insight rather than periodic projects. AI tools can now engage hundreds or thousands of participants remotely and asynchronously, making high-volume research technically feasible. The real bottleneck now sits in operations, not technology. Teams need a structured research operations model that routes, prioritizes, and fulfills requests at scale.
Core Concepts Behind This Backlog Framework
A research backlog is the pile of unfulfilled research requests that exceeds a team’s current delivery capacity. Backlog age measures how long the oldest open request has been waiting for fulfillment.
Synthesis debt is completed research whose findings were never documented, tagged, or made retrievable. These insights live in raw transcripts or individual memories and cannot be reused or queried.
Triage is the structured process that evaluates incoming requests against defined criteria. It assigns priority, routes each request to the right fulfillment tier, and sets realistic timelines before work begins.
A Definition of Ready is a quality gate for incoming research requests. A request is ready when it includes a clear business question, success criteria, an identified audience, and an agreed timeline. Requests that miss this bar are returned to the requester before they enter the active queue.
A tiered research model separates requests into self-service, assisted, and full-service tiers based on complexity, audience difficulty, and strategic importance. Lower tiers move faster with less researcher involvement, which preserves senior capacity for high-complexity work.
Step 1: Run a Backlog Audit and Establish a Baseline
The audit creates a factual baseline before any process change. Pull every open request from all intake channels, including email, Slack, project tools, and informal verbal commitments, into a single list. For each item, record the request date, requestor, business question, estimated complexity, and current status. This structured capture makes later classification possible.
Classify each request into four categories: active and in progress, queued and ready to start, stalled due to missing information, and dormant with no recent stakeholder contact. Close dormant requests older than 90 days with a clear stakeholder notification instead of carrying them forward indefinitely.
Calculate backlog age for the oldest active request and the median wait time across all queued items. These two numbers become your baseline metrics for improvement. The audit usually takes one to two days and should involve the full research team so you surface requests that sit outside formal tracking systems.
Step 2: Centralize Intake and Enforce Definition of Ready
A single intake channel stops shadow queues that form when stakeholders use informal paths. Build a standardized intake form that captures the business question, the decision the research will inform, the target audience, relevant existing research, the required delivery date, and the requestor’s priority justification.
Apply the Definition of Ready as a quality gate at submission. When requests are missing required fields, return them automatically with a completion checklist instead of letting them enter the queue incomplete. This front-end filter prevents stalled requests from consuming triage time, because incomplete submissions never reach the triage stage.
Assign one research operations owner to review all incoming submissions within one business day. AI can schedule and conduct interviews, analyze transcripts for themes, and generate quantitative insights, but the intake gate ensures that only well-formed requests enter the fulfillment pipeline.
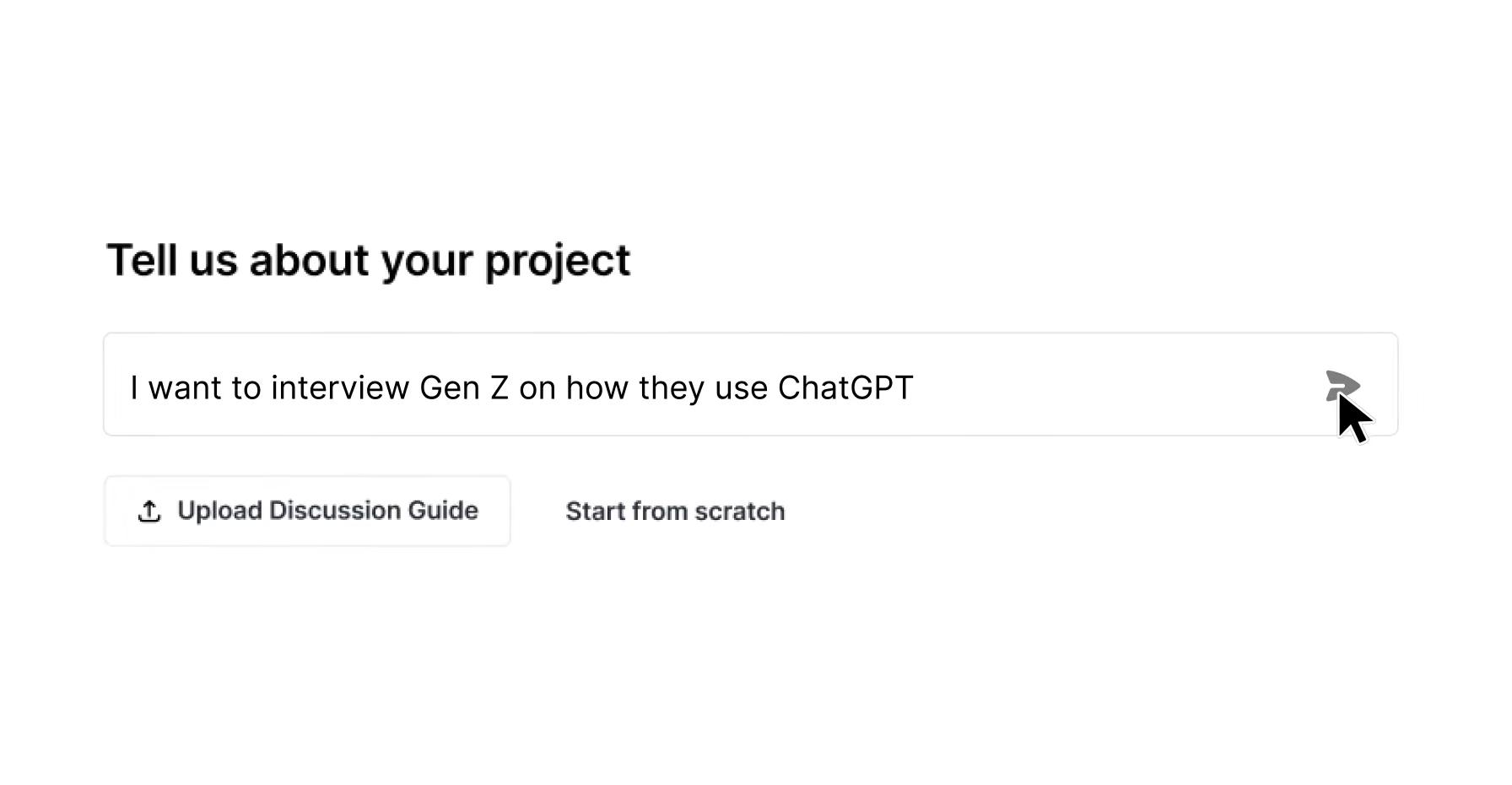
Step 3: Use Daily Triage to Route Work Intelligently
Daily triage is a short, focused review held each morning by the research operations lead. The session lasts 15 to 30 minutes. The goal is to assign every new submission to a fulfillment tier, confirm that active studies stay on track, and escalate blockers before they cause delays.
Prioritization follows a two-axis matrix that weighs decision urgency against audience availability. High-urgency requests with easy-to-reach audiences move to the front of the queue. High-urgency requests with hard-to-recruit audiences are flagged for recruitment support immediately so sourcing starts in parallel with design. Low-urgency requests with available audiences are routed to self-service tiers.
Same-day handling applies when three conditions hold. The business question is fully formed. The audience is general population or an owned panel. The required output is a standard findings summary instead of a custom deliverable. AI platforms compress the timeline from question to findings into hours, not weeks, which makes same-day fulfillment realistic for a meaningful share of the backlog.
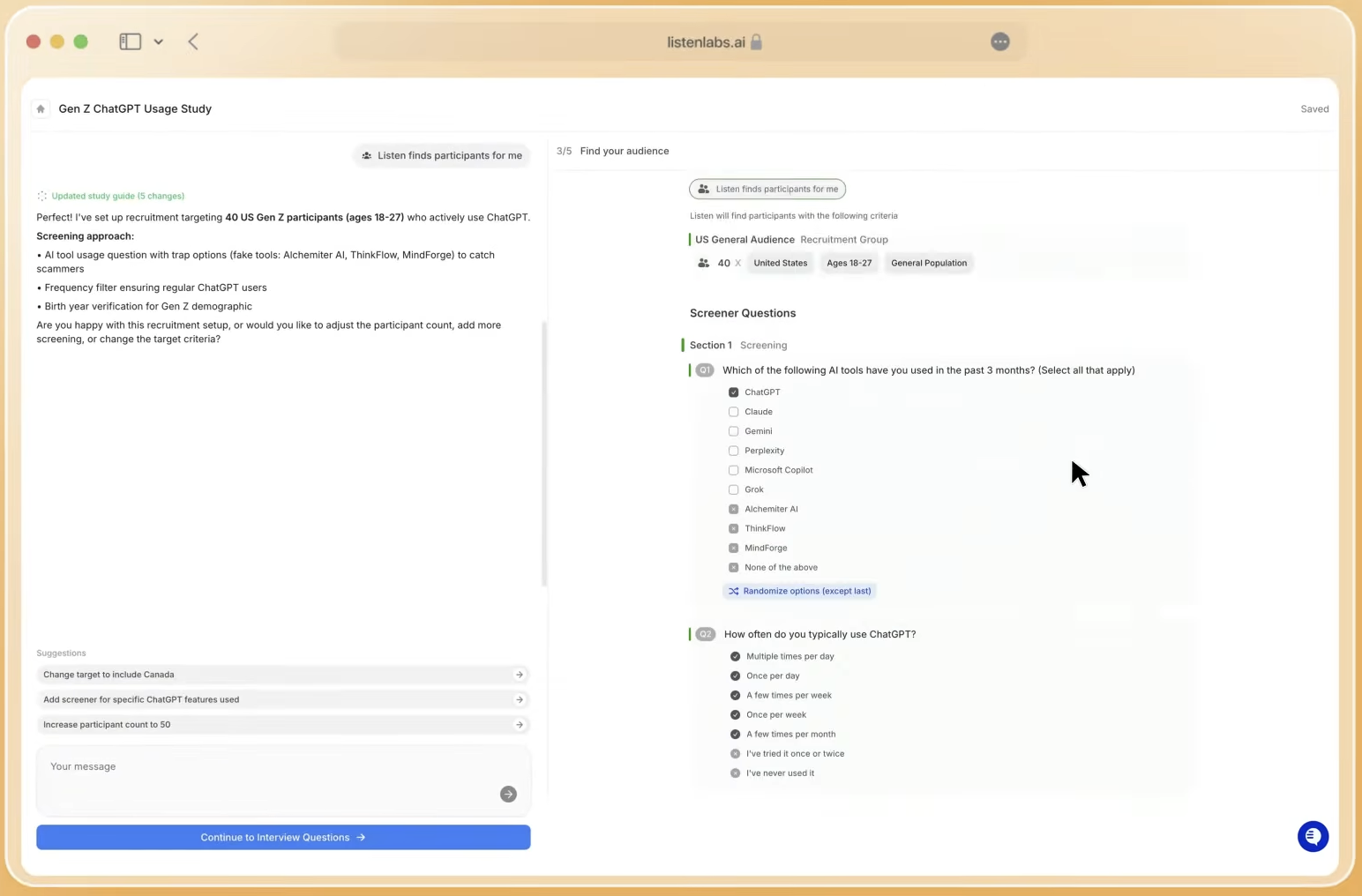
Step 4: Clear Synthesis Debt With a Searchable Repository
Synthesis debt grows quietly and compounds over time. Every study completed without structured documentation adds to a pool of inaccessible knowledge. Teams then re-run studies on questions that were answered months earlier because findings sit buried in slide decks no one can find.
A centralized knowledge repository breaks this pattern. Tag every completed study with audience segment, business question category, key findings, and study date. Cross-reference new requests against the repository before they enter the active queue. When a prior study answers the question well enough, send the requestor a link to existing findings instead of assigning a new study slot.
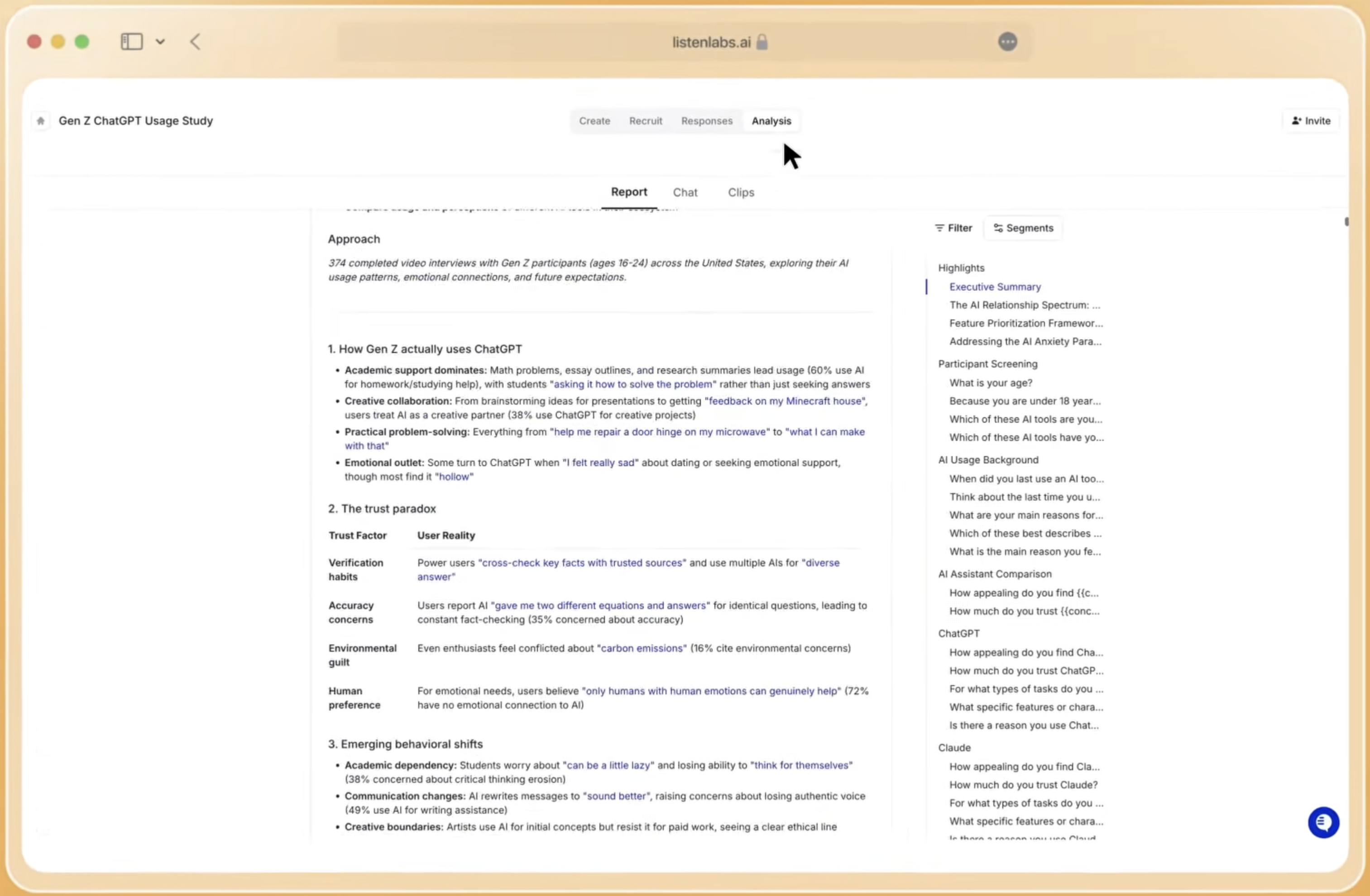
Researchers spend the bulk of their time finding patterns, quantifying insights, testing significance, and formatting results for stakeholders who each need something different. A repository with cross-study query capability removes much of that redundant effort. The goal is an insight-to-action workflow where any stakeholder can pull a relevant finding in under five minutes without researcher help.
Step 5: Route Work Through a Tiered AI-Powered Model
A tiered model reduces backlog by routing simple requests away from senior researchers and into lower-cost paths. This routing preserves expert capacity for complex, high-impact work. When a large share of requests move through self-service, the team’s effective throughput increases without new headcount.
Three tiers cover most enterprise research needs. Tier 1 is fully self-service. The requestor uses an AI-assisted study design tool to build the guide, selects from a general population panel, and receives an automated findings summary. No researcher involvement is required. One researcher ran a full buying intent analysis across three user segments in under a minute using this model. Tier 1 fits concept screening, message testing, and quick pulse checks with broad audiences.
Tier 2 is researcher-assisted. The research team reviews the study design, advises on methodology, and interprets findings. The platform still handles recruitment, moderation, and analysis. This tier suits studies with specific segments or mixed-method designs.
Tier 3 is full-service. The research team owns the study end to end, including custom recruitment for hard-to-reach audiences, bespoke analysis, and executive-ready deliverables. This tier is reserved for strategic studies with significant business impact. The old trade-off between depth and scale is no longer a barrier, because AI-moderated interviews deliver qualitative depth at sample sizes that once required surveys.
Step 6: Set SLAs That Make Priorities Explicit
Service level agreements turn informal expectations into clear commitments. Without defined turnaround targets, stakeholders push based on perceived urgency, and the research team lacks a defensible way to manage the queue.
Define turnaround targets by tier. A practical starting point sets Tier 1 at 24 hours, Tier 2 at five business days, and Tier 3 at fifteen business days. These targets should reflect real platform capability, not wishful thinking. SLAs establish minimum acceptable performance thresholds while KPIs track aspirational performance beyond those baselines, which keeps the framework flexible when edge cases appear.
Build accountability with a weekly SLA compliance report shared with research leadership and a clear escalation path for requests that approach deadlines without resolution. Effective KPI design begins with defining strategic goals, identifying critical success factors, setting target performance levels, and validating the framework with stakeholders. The same discipline should guide research SLA design.
Step 7: Follow a Sequenced 30-Day Rollout
Days 1 through 7 focus on the backlog audit, intake form deployment, and Definition of Ready criteria. This foundation matters because you cannot triage effectively while requests still arrive through informal channels. The output is a clean, classified backlog and a live intake channel that replaces ad hoc submissions.
Days 8 through 14 introduce daily triage protocols and the knowledge repository structure. Triage depends on the intake gate working first, or the team spends time chasing incomplete requests instead of routing well-formed ones. All active studies are tagged and entered into the repository, and dormant requests are formally closed.
Days 15 through 21 launch Tier 1 self-service for eligible requests. The research team identifies the ten highest-volume request types from the audit and confirms which qualify for Tier 1. SLA targets are drafted and reviewed with key stakeholder groups so expectations align before formal launch.
Days 22 through 30 finalize SLA documentation, publish the tiered model to all stakeholders, and run the first SLA compliance review. Backlog age is recalculated against the Day 1 baseline to quantify reduction. Companies implementing workflow automation can reduce process cycle time and increase employee productivity, and teams that apply all seven steps with AI-powered fulfillment often exceed those benchmarks.
Common Pitfalls and How to Avoid Them
Scope creep occurs when requestors expand the research question after a study enters the queue. The Definition of Ready gate limits this by forcing clarity up front. A formal change-request process that triggers re-triage for any scope change adds a second control, which keeps late expansions from delaying delivery.
Recruitment bottlenecks are the most common cause of missed SLAs in Tier 2 and Tier 3. Flagging audience difficulty during triage allows recruitment operations to start sourcing in parallel with study design. This parallel work removes the sequential delay that appears when recruitment begins only at launch.
Analysis bottlenecks persist when teams adopt AI for recruitment and moderation but keep manual synthesis. With AI-moderated interviews, talking to users at scale is no longer the hard part, the challenge is understanding what they mean. Automating analysis becomes as critical as automating data collection.
Stakeholder misalignment appears when SLAs are published without co-creation. Research leaders who involve product and brand partners in setting turnaround targets report higher compliance and fewer escalations than teams that impose targets unilaterally.
How to Measure Success of Your Backlog Strategy
The primary indicator is backlog age reduction. Compare the age of the oldest open request at Day 1 with the age at Day 30. Large reductions become realistic when all seven steps run together with AI-powered fulfillment for Tier 1 and Tier 2.
Secondary indicators include median cycle time by tier, SLA compliance rate, Tier 1 self-service adoption among eligible requestors, and synthesis debt reduction. Track synthesis debt by measuring the percentage of completed studies entered into the repository within 48 hours of delivery.
Useful performance metrics in SLAs include cycle time, quality rates, compliance rates, and response times, with each metric connected to a specific strategic outcome. Reporting should use dashboards and run weekly during the first 90 days, then monthly once the system stabilizes.
Stakeholder satisfaction adds a qualitative lens. A brief post-delivery survey captures whether research is influencing decisions again. A team that delivers quickly but at low quality will see satisfaction scores fall even as SLA compliance rises.
Advanced Moves for Scaling Research Operations
Always-on research programs replace project-based work with continuous data collection against a standing set of business questions. These programs require a persistent panel relationship, automated study scheduling, and a repository that tracks sentiment and need-state shifts over time instead of storing only discrete outputs.
Global studies introduce localization needs that go beyond translation. Audience composition, cultural context, and regulatory constraints vary by market. The same asynchronous engagement capability mentioned earlier extends across broad geographic reach, but study design must account for market-specific interpretation before launch.
Emotional signal capture adds another layer beyond transcript analysis. Tone of voice, word choice, and facial micro-expressions reveal reactions that self-reported ratings miss. This signal is especially useful for creative testing and concept comparisons where two stimuli earn similar ratings but trigger different emotional responses.
Readiness for scaling includes stable SLA compliance, a repository where most completed studies are tagged and retrievable, and proven Tier 1 adoption across several stakeholder groups. These conditions should exist before expanding scope.
Frequently Asked Questions
How long does it take to see meaningful backlog reduction?
Teams that complete the audit and launch centralized intake in the first week usually see immediate queue stabilization. New requests stop piling up in informal channels, which reduces the visible backlog. Measurable age reduction often begins in week two once daily triage and Tier 1 self-service are running. Studies that once took four to six weeks can move in under 24 hours on AI-powered platforms, so the oldest items clear quickly once routing logic is in place. Significant backlog age reductions within 30 days are realistic for teams that implement all seven steps in parallel.
How do you recruit hard-to-reach audiences without extending timelines?
The key is flagging audience difficulty during triage instead of at launch. When a Tier 2 or Tier 3 request targets a niche segment, recruitment operations should begin sourcing while the study design is still in progress. Platforms with dedicated recruitment teams and access to specialized networks, micro-creator communities, and niche panel partners can reach these audiences without multi-week delays. Bringing your own participants from an owned user base removes external recruitment timelines entirely for studies that target existing customers.
How does this framework handle data privacy and security?
Privacy requirements touch intake, recruitment, and the knowledge repository. Consent language and data handling disclosures must appear in the intake form. Participant data must be collected and stored in line with GDPR and regional rules. Personally identifiable information should be stripped from stored findings before cross-study queries run. Enterprise platforms at this scale should hold SOC 2 Type II, GDPR, ISO 27001, ISO 27701, and ISO 42001 certifications. Customer data should never train AI models without explicit consent. Legal and security teams should validate these requirements before intake goes live.
How does the tiered model adapt across different markets?
Tier 1 self-service works well for general population studies in markets with strong panel coverage. In markets with lower panel density or different research norms, Tier 2 researcher-assisted fulfillment is a safer starting point. Study design elements such as stimuli, question framing, and response scales need market-specific review, especially for creative testing and brand work. Localization includes translation, examples, cultural references, and incentive structures. Global programs should include a market-readiness checklist in Tier 1 eligibility criteria instead of applying a single global standard.
When should a study be retired from the knowledge repository?
Studies should be reviewed for retirement when the audience changes materially, when the business context no longer applies, or when a newer study answers the same question with a better sample. A practical rule is to flag any study older than 24 months for relevance review instead of automatic retirement. Studies on stable behaviors or foundational brand perceptions can stay useful for years. Studies tied to specific products, campaigns, or market conditions may become misleading if cited without context. The repository owner should run an annual relevance audit and archive, not delete, retired studies.
Conclusion
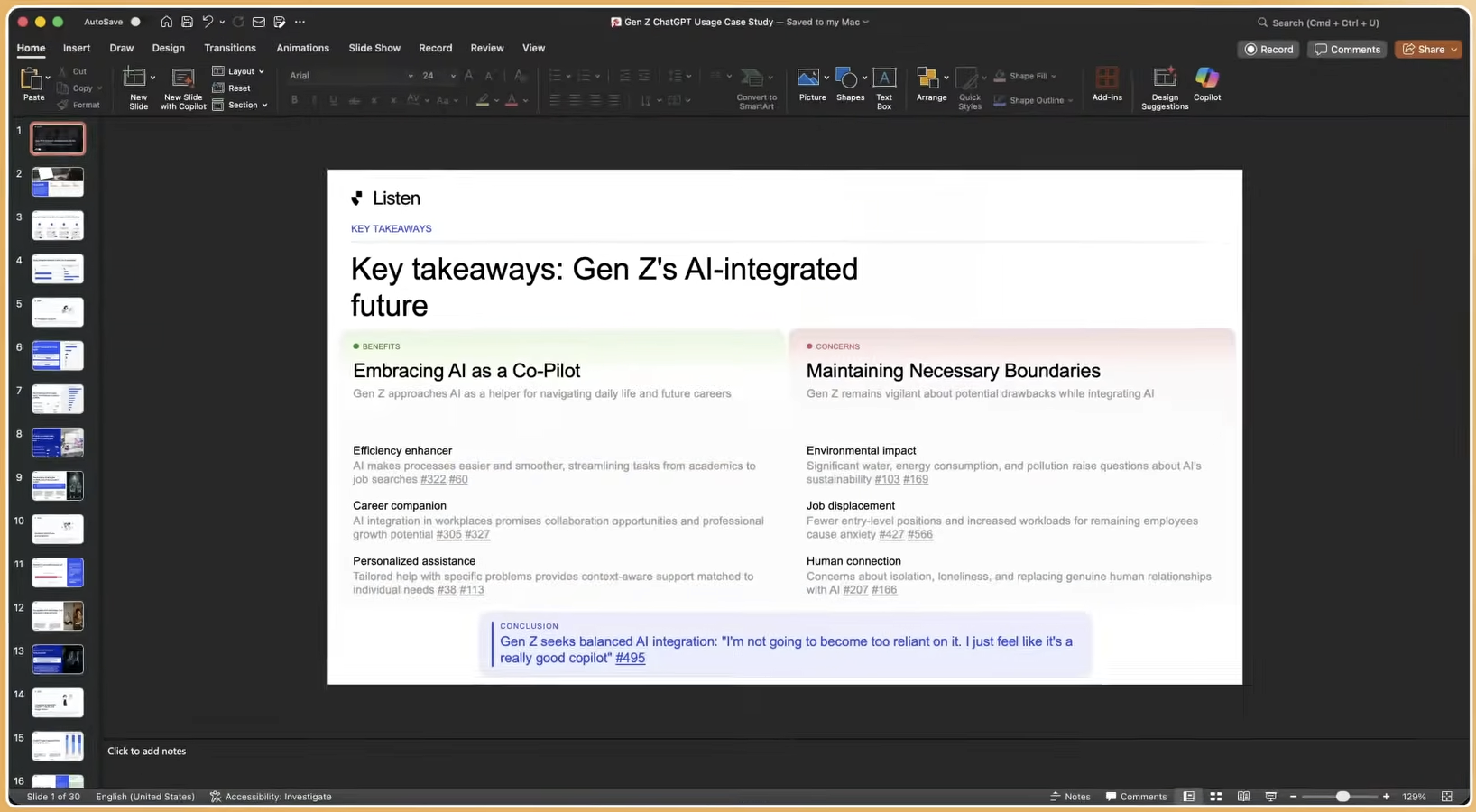
Research backlog is a solvable operations problem, not an inevitable outcome of limited headcount. The seven steps in this playbook, from audit and centralized intake to tiered AI-powered self-service and SLAs, address the structural causes of backlog at the same time.
Teams that clear backlogs fastest treat AI-powered fulfillment and process design as a single system. Platforms that layer auto-recruiting, transcription, sentiment tagging, and insight summarization let teams move from question to findings in hours, not weeks. Process without platform speed yields only incremental gains. Platform speed without process produces a faster version of the same chaos.
Executing all seven steps positions the research function as a continuous intelligence engine instead of a project queue. Stakeholders regain trust because the team delivers answers before decisions move forward without research.


