
Written by: Anish Rao, Head of Growth, Listen Labs
Key Takeaways
- NLP combined with reflexive thematic analysis speeds coding and pattern detection across large interview datasets while keeping human interpretive oversight for validity and compliance.
- The hybrid workflow reduces traditional 4–6 week manual coding cycles to under 24 hours, so enterprise teams can clear research backlogs faster.
- Upstream quality drives downstream value, because clear objectives, rigorous screening, and strong data collection prevent poor inputs from degrading NLP outputs.
- Five repeatable stages (study design, sourcing, adaptive interviews, NLP-assisted analysis, and human synthesis) create a scalable, compliance-ready process for global research programs.
- Listen Labs operationalizes this entire workflow in a single platform; see how it works end-to-end in a live demo.
Prerequisites and Context for Enterprise Teams
This guide speaks to VP and Director-level consumer insights leaders and heads of UX research at Fortune 500 enterprises in tech, CPG, and retail. These teams usually manage 5–30 researchers, operate as internal service providers, and face research backlogs that grow faster than capacity.
Qualitative research captures the why behind behavior through open-ended interviews, while quantitative research measures the what at scale through structured surveys. The long-standing tension between the two has historically forced teams to choose depth or breadth. With qual-at-scale, the old trade-off between depth and scale is no longer a barrier.
Sample frame and incidence rate matter before any NLP layer enters the picture. A poorly defined screener produces low-quality transcripts that degrade downstream model outputs regardless of algorithmic sophistication. Moderation quality, whether human or AI-led, determines the richness of the raw text that NLP tools later process. These upstream decisions set the ceiling for everything that follows.
Continuous discovery programs and global research mandates have raised the stakes further. Teams now need repeatable, compliance-ready workflows that can run across markets and languages without rebuilding methodology from scratch each cycle. The five-stage process below provides that repeatable structure, starting with upstream decisions that determine downstream analytical quality.
Step-by-Step Hybrid NLP Workflow
Stage 1 — Study Design. Define research objectives in precise, testable language before writing a single interview question, because ambiguous objectives produce ambiguous transcripts that resist clean thematic coding. AI-assisted study co-design tools can accelerate this definition process by drafting structured objectives and probing context from a natural-language brief, while flagging logical gaps before fieldwork begins. Once the objectives are drafted, stakeholders from product, brand, and insights should align on them at this stage to prevent scope creep during analysis.
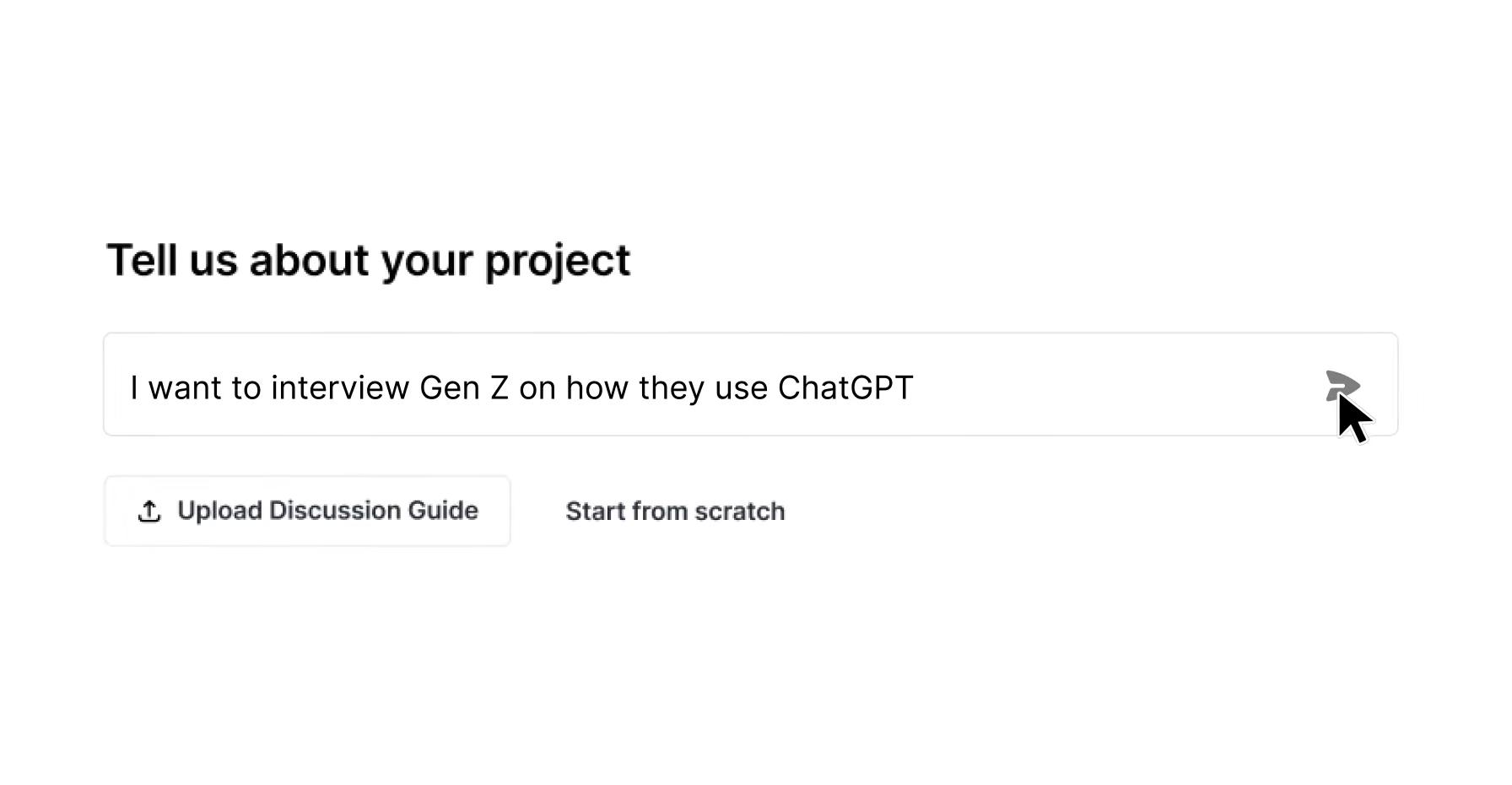
Stage 2 — Participant Sourcing and Screening. Match the sample frame to the research question. Incidence rates below 1% such as enterprise decision-makers, clinical specialists, or highly specific consumer segments require dedicated recruitment operations rather than commodity panel access. Behavioral matching on intent and past actions produces higher-quality transcripts than demographic self-reporting alone. Participant frequency limits, such as capping respondents at three studies per month, remove professional survey-takers whose responses introduce noise into NLP pipelines.
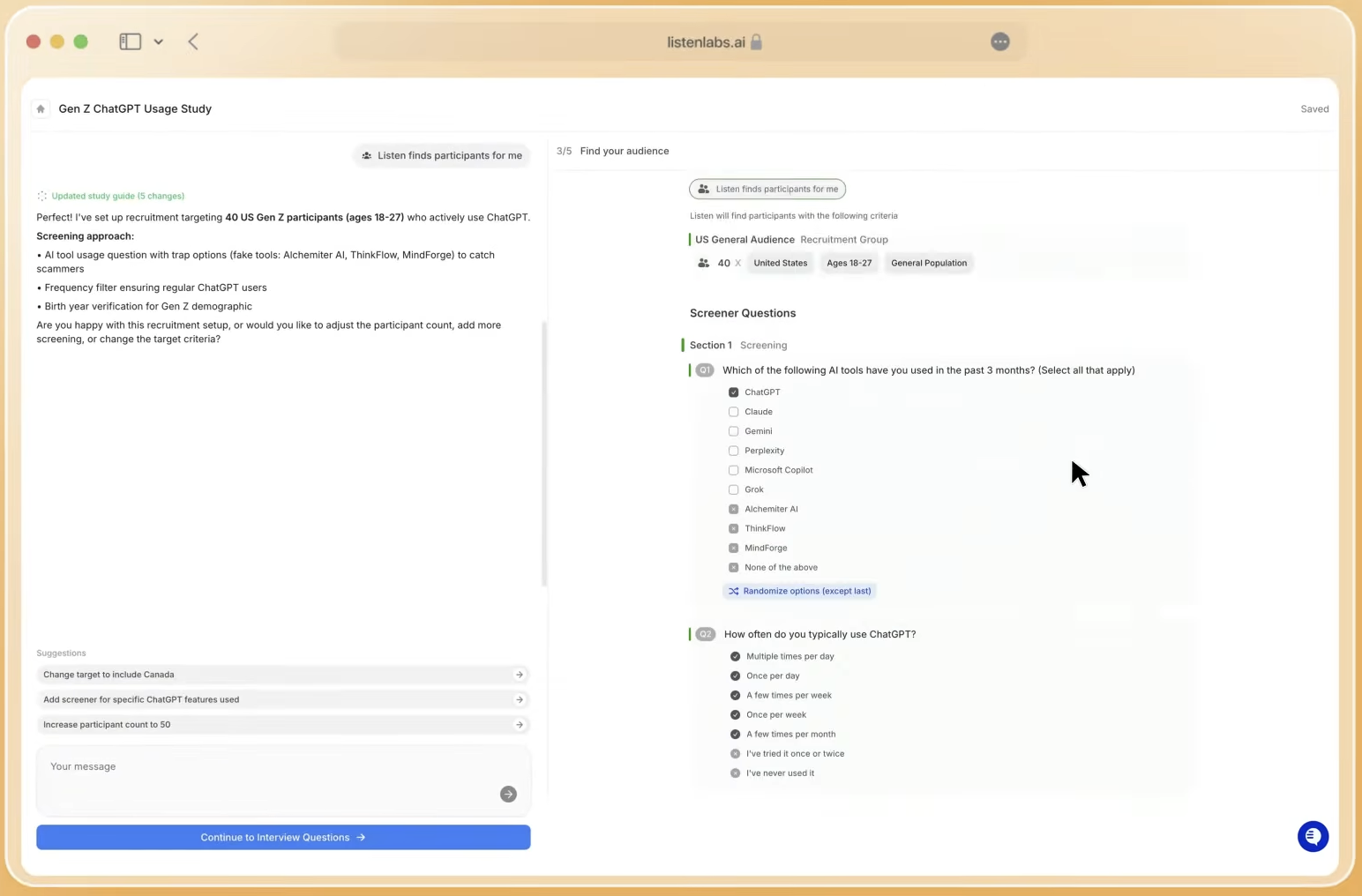
Stage 3 — Data Collection via Adaptive Interviews. AI-moderated interviews that probe dynamically on short or unexpected answers generate the semantic density that NLP models require. AI can schedule and conduct the interview, analyze the transcripts for themes, and generate quantitative insights from those interviews, yet the quality of follow-up questioning during collection still directly determines the analytical yield. Mixed-method designs that embed Likert scales or MaxDiff alongside open-ended questions allow NLP outputs to be cross-validated against structured responses.
Stage 4 — NLP-Assisted Thematic and Sentiment Analysis. With AI-moderated interviews, talking to users at scale is no longer the hard part, while the challenge becomes understanding what they mean. This stage delivers the largest efficiency gains in the hybrid model. Automated qualitative analysis can achieve substantial agreement with human coders, which provides a statistically defensible starting codebook. Human researchers then review, critique, and refine AI-generated codes rather than building them from scratch, a shift that cuts cycle time dramatically. Every insight links directly to the underlying response data, which preserves the traceability that IRB review and stakeholder scrutiny require. Teams running this stage on large volumes of transcripts can recover significant time compared with fully manual coding.
Stage 5 — Synthesis and Validation. Human researchers interpret the implications of NLP-generated themes, connect findings to business context, and stress-test conclusions against disconfirming evidence in the transcript corpus. Deliverables such as slide decks, memos, video highlight reels, and statistical charts are generated from validated themes, not raw model outputs. This final human layer separates a defensible research report from an automated summary.
See how Listen Labs executes all five stages within a single platform.
With the process stages defined, the next section explains the analytical frameworks that guide choices inside Stage 4 and clarify how NLP integrates with established qualitative models.
Hybrid NLP Frameworks and Real-World Examples
NLP in Qualitative Research: The Investigator + NLP Hybrid Model
The Investigator + NLP hybrid model assigns distinct roles to computational tools and human researchers. NLP handles pattern detection, clustering, and frequency analysis across large corpora. Human investigators handle interpretation, contextualization, and reflexivity. Automated qualitative analysis is not a push-button process, and the strongest results come from blending AI with human expertise through a human-in-the-loop approach.
The GATOS workflow formalizes this division by using text embeddings, dimensionality reduction, and retrieval-augmented generation to generate an inductive codebook from raw text. It then positions that codebook as an assistive layer that mimics selected phases of Braun and Clarke's reflexive thematic analysis while still preserving the need for human interpretive oversight.
NLP Thematic Analysis: Inductive vs. Deductive Coding Choices
Inductive coding generates codes and themes directly from the data rather than imposing predetermined categories, while deductive coding uses pre-existing theories or a predetermined codebook to guide analysis. This choice has direct consequences for NLP configuration.
Inductive NLP analysis, defined as a data-driven approach to generate a codebook from the text when the researcher does not know a priori what is discussed, suits exploratory studies where unexpected findings are the primary objective. Deductive NLP analysis applies a pre-built code frame to new transcript data, which enables rapid measurement against established constructs. Most projects benefit from a hybrid strategy that blends inductive and deductive approaches throughout the coding process.
Cross-Industry Scenarios Using the Hybrid NLP Workflow
The following three scenarios show how the hybrid NLP workflow adapts to different research objectives across CPG, tech, and retail contexts, and each one highlights a distinct analytical challenge that the five-stage process addresses.
CPG product innovation. A consumer insights team at a global CPG company runs 250 AI-moderated interviews across three markets to evaluate new product claims. NLP clustering surfaces that comfort and reliability appear as dominant themes across all markets, while novelty-focused claims cluster in a low-frequency, high-skepticism segment. Human researchers interpret the regional variation and translate findings into a prioritized innovation brief, a process that previously required six weeks of manual coding.
Tech platform churn analysis. A product strategy team conducts more than 300 interviews with lapsed subscribers in under 48 hours. NLP sentiment analysis identifies friction points at specific product touchpoints, while inductive topic modeling surfaces migration patterns to competitor platforms that were not part of the original research brief. The hybrid workflow delivers a prioritized list of retention interventions grounded in verbatim evidence.
Retail campaign testing. A brand team tests creative directions with high-income consumers overnight. Multimodal NLP, which combines transcript analysis with tone-of-voice and micro-expression signals, distinguishes genuine enthusiasm from polite approval, a distinction that text-only analysis misses. Continuous emotion intensity evaluation, rather than binary emotion classification, quantifies the degree of emotional response across stimuli and enables side-by-side concept comparison with statistical confidence.
Explore how Listen Labs applies this hybrid model to your specific research context.
Common Challenges and Troubleshooting
Unclear objectives. NLP models surface patterns in whatever text they receive, so vague research questions produce vague codebooks. An early-warning signal appears when stakeholders cannot agree on what a successful finding would look like before fieldwork begins. The mitigation is a written research brief with testable objectives signed off by all stakeholders before study design is finalized.
Low-quality responses. Short, incentive-driven, or AI-generated responses degrade embedding quality and produce spurious clusters. A clear warning sign appears when median response length falls below two sentences per open-ended question. Effective mitigation combines real-time quality monitoring during data collection, participant frequency limits, and behavioral screening rather than demographic self-reporting.
Analysis bottlenecks. Researchers spend the bulk of their time in analysis: finding patterns, quantifying insights, testing significance, adding macro context, and formatting results for stakeholders who each need something different. NLP reduces this burden but does not remove the need for researcher judgment. Bottlenecks re-emerge when teams treat AI-generated codebooks as final outputs rather than starting points for human review.
Privacy and compliance concerns. Scaling NLP analysis on interview transcripts introduces data protection obligations. Organizations processing personal data should conduct a Data Protection Impact Assessment before high-risk processing and apply safeguards such as anonymisation or pseudonymisation. Deidentification, pseudonymization, and synthesizing anonymized data enable secure and valid analysis of unstructured qualitative elements. Platforms that hold SOC 2 Type II and ISO 27001 certifications can help reduce IRB and legal review friction.
Addressing these challenges early in study design prevents compounding errors that are expensive to correct after fieldwork closes. Once those upstream risks are mitigated, downstream metrics can confirm whether the workflow delivers the promised efficiency and quality gains.
Measuring Success
Four indicators reliably signal whether a hybrid NLP plus qualitative workflow delivers value at enterprise scale.
Study cycle time reduction. Baseline the current average time from study brief to final deliverable. Track this metric per study type to identify where manual steps persist and where automation has the greatest impact.
Participation rates and sample quality. Monitor completion rates, median response length, and fraud-detection flags across studies. Declining participation rates or rising low-quality response flags indicate upstream recruitment or screening problems that will degrade NLP outputs.
Inter-coder reliability. Thematic analysis using generative AI can achieve substantial agreement with human coders. Establish a baseline Kappa score for AI-generated codes against human review on a sample of transcripts per study. Scores below 0.70 warrant codebook revision before full-corpus analysis proceeds.
Downstream decision usage. Track whether research findings are cited in product roadmap decisions, campaign briefs, or executive presentations. High cycle-time reduction paired with low downstream usage indicates a synthesis or communication problem, not an analytical one.
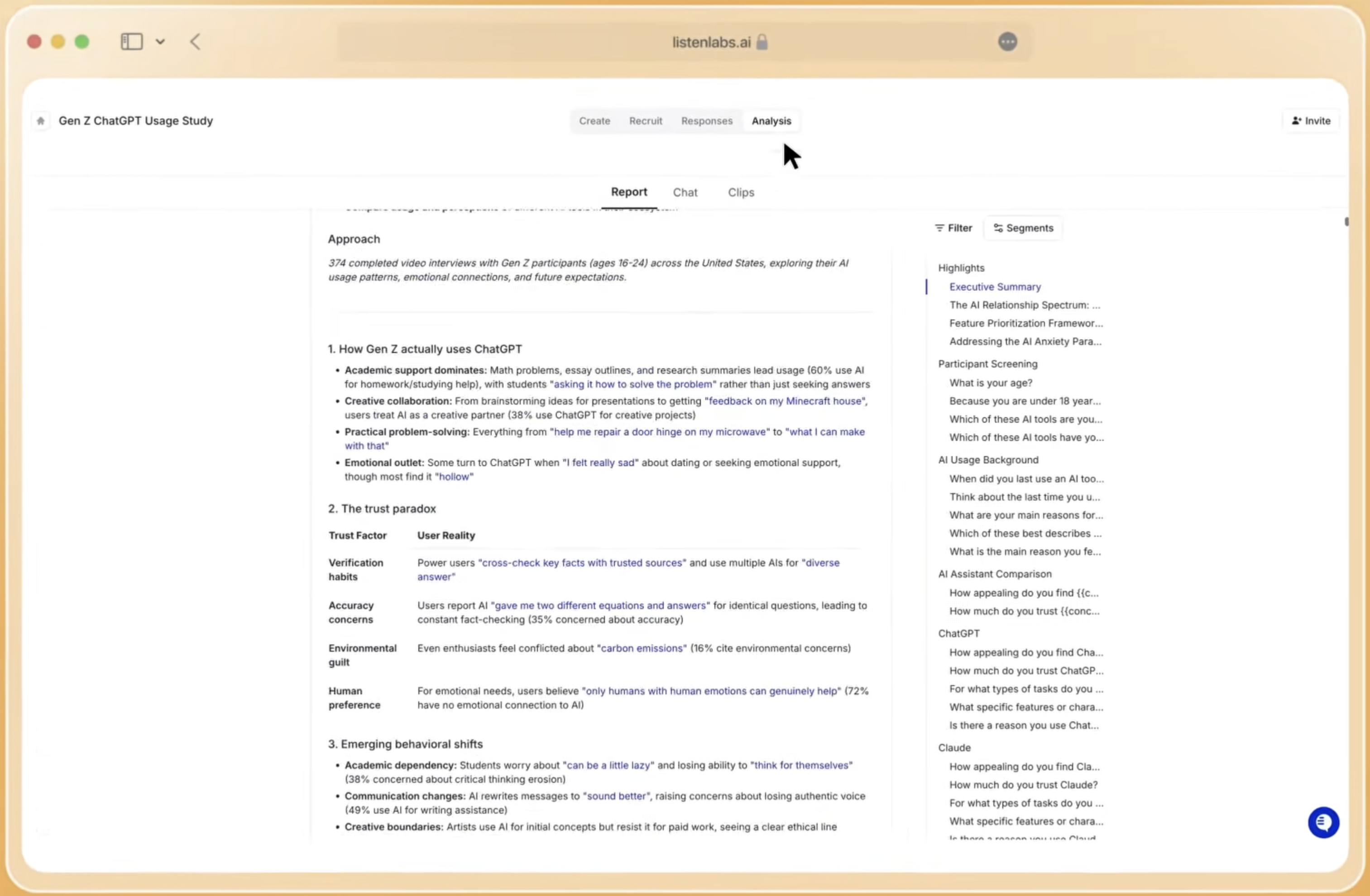
These four metrics together provide a complete picture of workflow health and justify continued investment in hybrid NLP infrastructure.
See how Listen Labs surfaces these metrics automatically within its Research Agent.
Advanced Workflow Extensions and Iteration
Once the five-stage workflow runs reliably, four extensions can multiply its strategic value. These extensions build longitudinal knowledge through continuous research, scale the approach across global markets, layer emotional signals onto text analysis, and de-risk adoption through controlled pilots. Each one moves the organization from single-study execution toward an enterprise-wide capability.
Always-on research programs. Single-study deployments of hybrid NLP workflows capture a moment in time. Continuous discovery programs that run recurring interview waves build a longitudinal dataset that enables trend tracking, sentiment shift detection, and cross-study queries against an accumulating knowledge base. Each study strengthens the institutional knowledge layer rather than existing in isolation.
Multi-market segmentation. Global research programs require NLP pipelines that operate across languages without losing semantic fidelity. Platforms supporting more than 100 languages with automatic translation and transcription allow a single study design to generate comparable codebooks across markets. This capability enables cross-cultural theme comparison that manual multilingual coding cannot match at similar speed.
Emotion-signal layering. Text-only NLP captures what participants say but misses what they feel. Multimodal emotion recognition systems that combine contextual text embeddings with sequential signal processing can achieve strong accuracy across discrete emotion classes, while continuous emotion intensity evaluation frameworks quantify the degree of emotional response rather than its binary presence. Layering tone-of-voice, word choice, and micro-expression analysis onto transcript data surfaces the gap between stated and felt reactions, a distinction that proves particularly valuable in creative testing and concept evaluation.
Safe pilot approaches. Teams new to hybrid NLP workflows should pilot on a completed study with known findings before deploying on live research. Comparing NLP-generated codebooks against existing human-coded outputs on the same dataset calibrates researcher confidence and identifies configuration adjustments before the workflow applies to high-stakes studies.
FAQ
What sample size is needed before NLP adds value to qualitative analysis?
NLP techniques outperform manual coding in speed and consistency when working with larger numbers of transcripts, where the volume of text exceeds what a single analyst can code reliably within a standard project timeline. At higher volumes, embedding-based clustering and topic modeling can surface patterns that manual review would likely miss or underweight. For smaller sets of transcripts, traditional reflexive thematic analysis often remains the more appropriate primary method, with NLP used selectively for sentiment scoring rather than full codebook generation.
What research skills are required to implement a hybrid NLP workflow?
Researchers need a working understanding of thematic analysis methodology, including the difference between inductive and deductive coding, to evaluate and refine AI-generated codebooks meaningfully. Familiarity with inter-coder reliability metrics such as Cohen's Kappa is necessary for quality assurance. Deep programming or data science expertise is not required when using end-to-end platforms that abstract the NLP layer, because the researcher's role centers on interpretive oversight rather than model configuration.
How does a hybrid NLP workflow handle compliance with GDPR and IRB requirements?
Compliance depends on three practices: data minimization, pseudonymization or anonymization of transcripts before they enter NLP pipelines, and maintaining a clear audit trail that links every AI-generated code back to its source verbatim. A Data Protection Impact Assessment should be completed before processing sensitive interview data at scale. Platforms holding SOC 2 Type II and ISO 27001 certifications provide a documented compliance foundation that can simplify IRB review and legal sign-off.
Can NLP analysis introduce bias into qualitative findings?
Yes. NLP models trained on biased corpora can systematically underrepresent minority viewpoints or amplify majority-group language patterns in codebook generation. Effective mitigation requires reviewing AI-generated codes against the full distribution of participant responses, not just high-frequency clusters, and applying human interpretive oversight to low-frequency themes that may carry disproportionate strategic significance. Explainable-AI methods that surface which phrases drove a particular code assignment help researchers identify and correct bias before synthesis.
How long does it take to go from study brief to final deliverables using a hybrid NLP workflow?
On an end-to-end platform that integrates study design, participant recruitment, AI-moderated interviews, and automated analysis, the full cycle from brief to deliverable runs in under 24 hours for standard studies, a timeline that enables continuous discovery programs and rapid iteration on research findings. The time reduction is most pronounced in the analysis and reporting stages, where automated theme generation, chart creation, and slide deck assembly replace days of manual work.
The practices described throughout this guide, from study design through advanced iteration, represent a mature, repeatable methodology for enterprise research teams. Listen Labs is built to execute this methodology at production scale, handling every stage from participant sourcing through final deliverable generation within a single compliant platform trusted by organizations including Microsoft, Google, P&G, and Anthropic.
See how Listen Labs compresses your research cycle without sacrificing interpretive depth.


